Master the design and verification of next gen transport: Part Two – high-level synthesis
Part one of this series outlined advantages of high-level synthesis (HLS) and emulation that next generation transportation designs can exploit. This second part goes into more detail as to how primarily high-level synthesis (HLS) can be used for design exploration and verification.
Part Two is based on a demonstration using the Tiny YOLO convolutional neural network (CNN) for object classification.
A high-level definition of HLS’s advantages is that it represents a more efficient abstraction above RTL that is particularly well-suited to (and has been demonstrated in) the types of machine learning (ML) and artificial intelligence (A() designs that are increasingly important toward the delivery of advanced assistance and autonomous driving. Like ML and AI algorithms, HLS uses C++ and SystemC.
HLS can thus get a project to a stable RTL state more quickly, allow for early verification and free up more time for optimization and analysis. A broad overview is shown in Figure 1.

Figure 1. Overview of HLS advantages (Mentor)
Two specific uses of HLS are described here. First is the use of HLS and emulation to experiment with synthesis options. Second is architectural exploration.
The example CNN, Tiny YOLO, is a comparatively small CNN for object detection and classification. It targets roughly 20 objects. CNNs performing the same role in vehicles are likely to need to classify more, particularly as design moves toward Level-5 autonomy.
However, although small, Tiny YOLO requires a lot of computation. It performs more than 70 billion MACs per second and includes 25 million weights, processed mostly through two-dimensional convolution and pooling layers. So, it is a good test of solutions to the challenges that need to be overcome.
HLS plus emulation to explore implementation
As discussed previously, HLS’ use of C++ reduces coding size and time by several multiples, separating functionality from implementation, and thereby accelerates design.
In this first example, a flow combining HLS (here Catapult HLS) and emulation (Veloce from the same vendor) is shown that inserts and verifies enhancements to a Tiny YOLO implementation.
The demonstration derives from the CNN’s testbench. It is written in Python and based on the open-source TensorFlow ML framework (Figure 2).
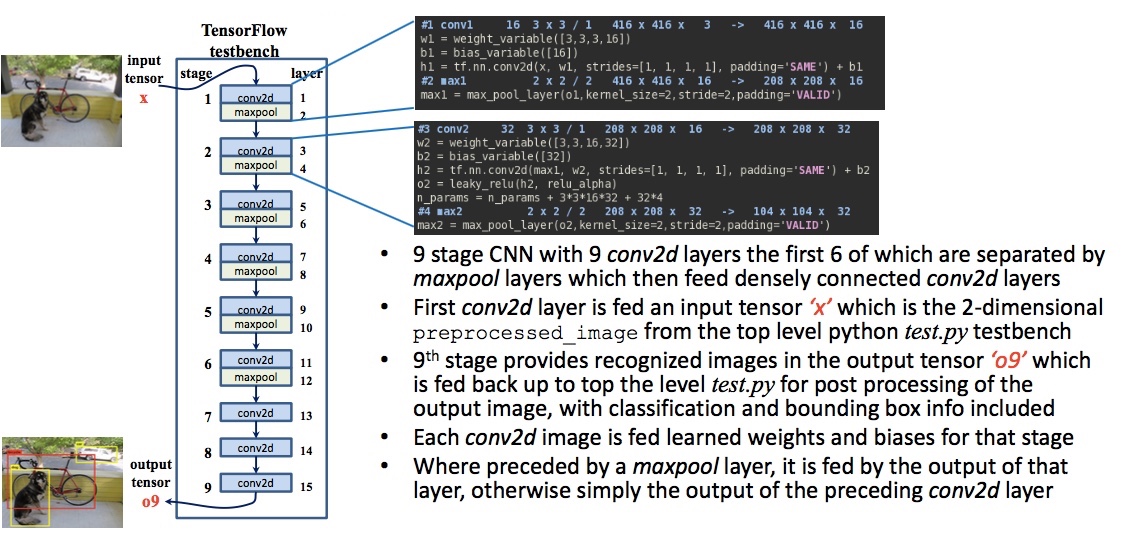
Figure 2. Python/TensorFlow testbench for Tiny YOLO (Joseph Redmon – click to expand)
As shown above, Tiny YOLO is a nine-stage CNN. There are nine layers across which six of those for two-dimensional convolution are separated by ‘maxpool’ layers. These feed densely connected ‘conv2d’ layers.
For the testbench, an input tensor is introduced. It is a 2D preprocessed image from a top-level Python ‘test.py’ testbench. It goes through the CNN to the ninth stage to provide an output tensor that is fed back to test.py. Here, there is post-processing of the output with a classification and bounding box included.
Each image is fed weights and biases based on prior learning as appropriate to the stage. Where a ‘maxpool’ layer is present, the image is fed with the output of the ‘maxpool’ layer, otherwise it is fed the output of the preceding ‘conv2d’ layer.
This case study follows a progressive refinement of Tiny YOLO. The first overarching objective is to explore different implementation options where one or more of the original layers is broken out and reviewed within the original Python testbench (Figure 3). These blocks of synthesizable code are then verified before RTL is generated.
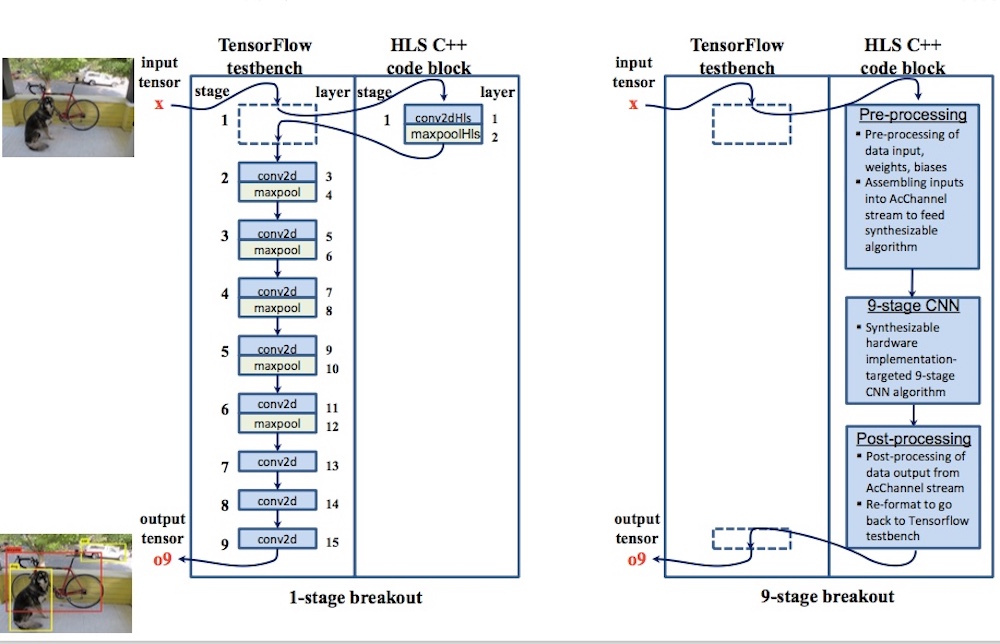
Figure 3. Testbench layers broken out to HLS-ready C++ implementation-targeted algorithms (Mentor/Accellera – click to expand)
So far, the project has been carried out within a HLS environment. For the next stage, emulation is introduced. The HLS-verified C++ code prototypes are synthesized and replaced with RTL that will run on Veloce (Figure 4) but still within the context of the original Python testbench.
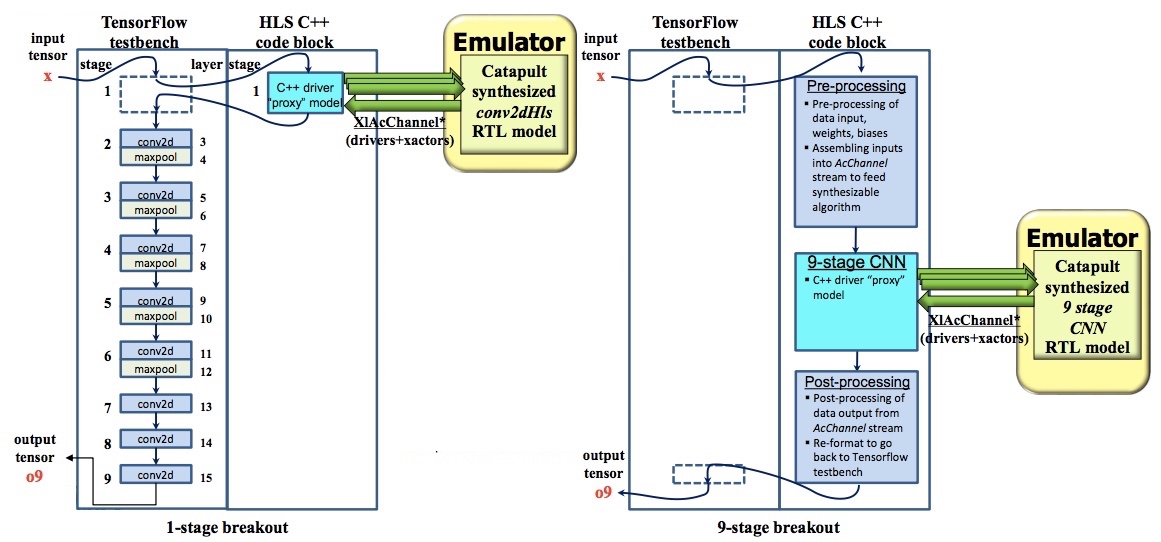
Figure 4. C++ implementations of CNNs replaced with synthesized RTL blocks (Mentor/Accellera – click to expand)
In this example, the C++ blocks become ‘AcChannel’ drivers to ‘AcChannel’ bus functional models running on the emulator. For both breakout examples, cross-process ‘XIAcChannelDrivers’ derived through transaction-level modeling couple the TensorFlow testbench and HLS C++ remote client process with the co-model host process and Veloce.
The overall process is summarized in Figure 5. It allows users to verify HLS C++ code and RTL in the single testbench. It is much faster than working in RTL alone. For the Tiny YOLO example, verification that would previously have taken hours now takes minutes.
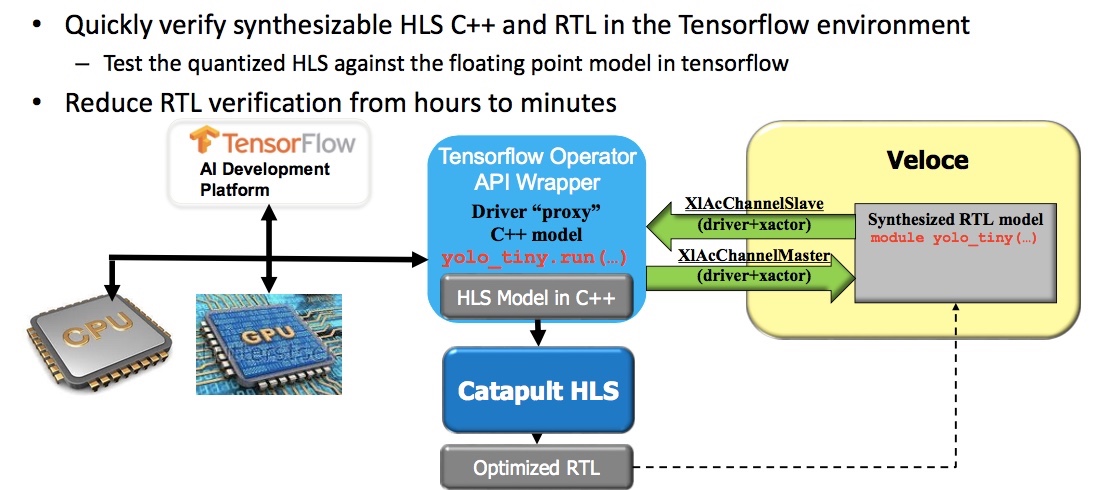
Figure 5. HLS and emulation combined to accelerate verification (Mentor/Accellera – click to expand)
HLS for architectural exploration
Time saved through more efficient and simpler processes elsewhere in a design flow can both speed project delivery and/or open up options for greater architectural review. This is very useful when the target is an objection classification task such as that performed by Tiny YOLO.
Advanced transportation devices are moving more processing to the edge. Here a training as opposed to an inference strategy is preferable for efficiency, latency and power consumption. An important factor for power is memory: keeping data local helps to minimize consumption.
For this project, a dual-layer architecture is explored to reduce RAM access as much as possible. Going back to the CNN’s nine layers, the proposal is to use and optimize a sliding-window architecture for layers one-to-four and an in-place architecture for layers five-to-nine. The goal is to use the HLS environment to reorder, organize and unroll loops as appropriate in the two parts of this hybrid (Figure 6).
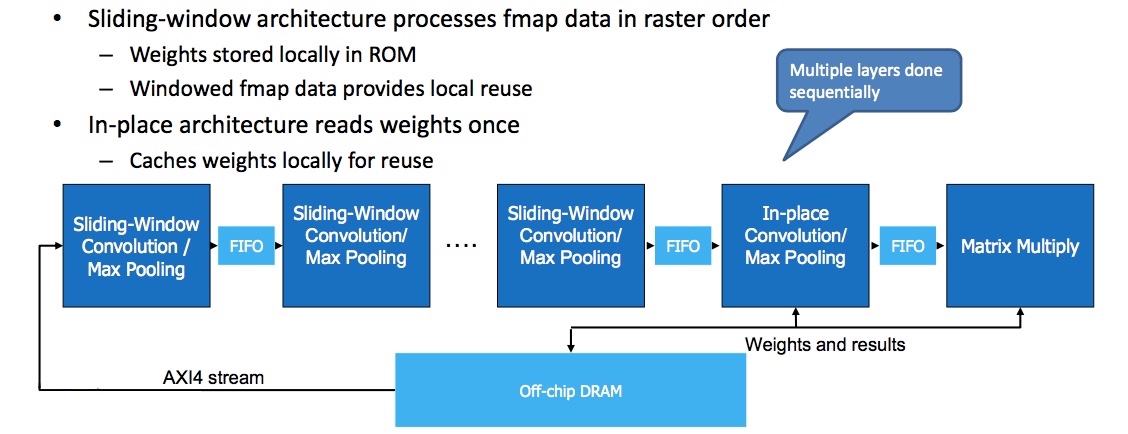
Figure 6. Proposed hybrid architecture (Mentor/Accellera – click to expand)
A sliding-window architecture processes feature map (fmap) data in raster order. Weights in Tiny YOLO are stored locally in ROM and windowed data is available for local reuse.
An in-place architecture processes one layer after another with feature maps stored locally in SRAM and weights read once from the system memory.
Figure 7 shows the reordering of loops for the sliding-window layers to facilitate unrolling achieved within an HLS environment for the sliding-window strategy, and Figure 8 highlights that unrolling, now allowing multiple outputs to be processed in parallel.
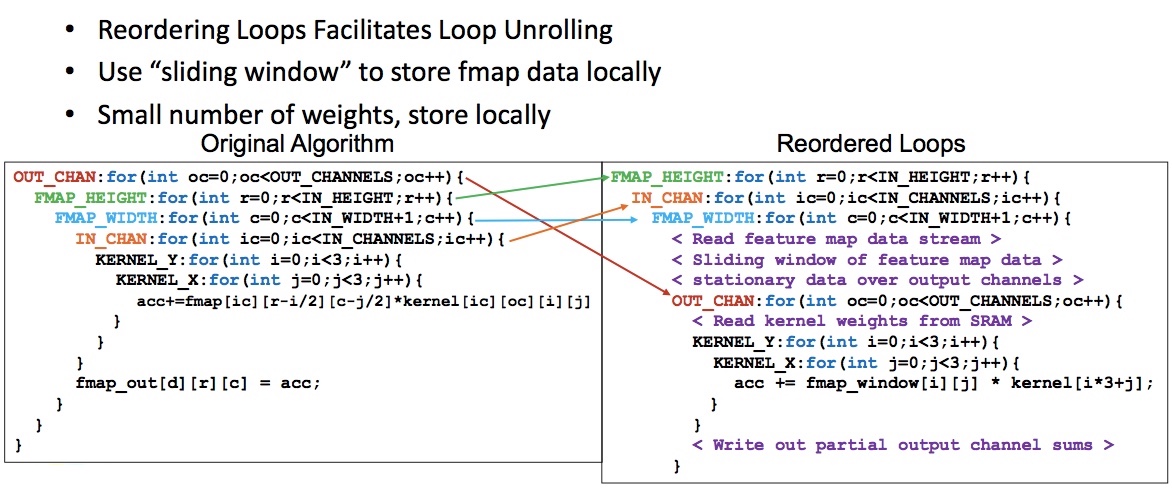
Figure 7. From original algorithm to reordered loops – sliding-window (Mentor/Accellera – click to enlarge)

Figure 8. Unrolling loop options – sliding window (Mentor/Accellera – click to enlarge)
For the in-place architecture, Figure 9 shows the organization of loops so that weights are read only once, with those weights held stationary across feature maps. The feature maps are computed in order and stored in local SRAM.
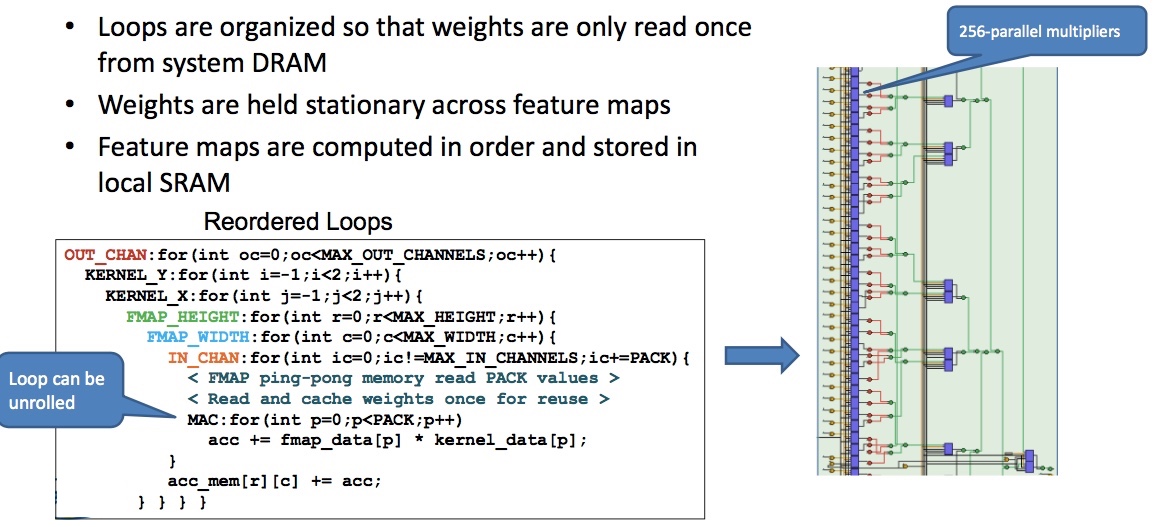
Figure 9. Unrolling loop options – in-place (Mentor/Accellera – click to enlarge)
This type of exploration helps HLS deliver more highly optimized designs, here primarily for memory access and thereby power.
Further options
This article has looked at two cases where HLS (with emulation) can help to deliver complex transportation-type projects more efficiently than through the use of traditional flows using hand-coded RTL.
There are further options in terms of formal pre-RTL analysis – particularly to find potential mismatches as well as bugs and errors – and higher level power analysis.
These advantages are described in more detail in the original tutorial on which this article is based. ‘Next Gen System Design and Verification for Transportation’ is available within the proceedings of DVCon United States, where it was presented by authors David Aerne, Jacob Wiltgen and Richard Pugh of Mentor, a Siemens business.
It will also be presented in full during DVCon Europe in Munich. More details are available here.
The fourth part considers emulation in a broader system-of-systems context.