Balancing PPA as machine learning moves to the edge
High level synthesis (HLS) has already established itself as a useful design strategy for AI and machine learning (ML) SoC design in the cloud and other locations where there are hefty computational resources. However, ML is now increasingly moving to the edge.
‘Machine learning at the edge: Using HLS to optimize power and performance‘ is a recently published white paper from Mentor that looks at the additional challenges this trend raises, and how they can be resolved.
Many of the emerging edge instances are application-specific and, by their nature, mean there are far stricter constraints in terms of power, performance and area – particularly power. That last factor rules out GPUs and TPUs, as well as the majority of ML accelerators.
At the same time, the demands being placed on ML systems everywhere are becoming more complex. Image processing, for example, is using more spatial and temporal inputs. In this context, CPUs are often too slow.
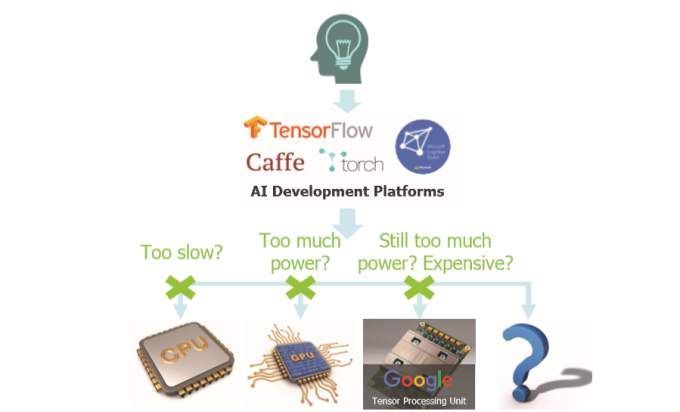
Figure 1. Off-the-shelf hardware limitations for edge ML (Mentor)
As a result, these edge use-cases can often involve custom design, and, given the nature of machine learning, the convolutional neural networks that underpin it, and ML’s broader evolution, these are sometimes best achieved using multiple processing architectures (e.g. early-stage fused-layer/later-stage multi-channel array) because of progressively different demands on buffers and memory. The resulting memory architectures are also complex.
Trying to realize this kind of design at the RTL is hard. Verification is lengthy, for a start. The paper considers how HLS is a better enabler for this kind of multi-architecture project in terms of both design and verification, using inherent techniques such a automatic memory partitioning and power optimization.
With ML algorithms themselves still in a state of rapid evolution, it also notes that the synthesizable C++ that HLS produces can be fed back into the frameworks (e.g. Caffe, TensorFlow) on which the algorithms are developed for more complete system verification.
The paper is available for download here.