Achronix deploys network on chip for faster FPGAs
Achronix is introducing an FPGA architecture that pulls a full network-on-chip (NOC) into the programmable-logic fabric to create a structure the company claims will be far better at handling machine-learning and high-speed networking designs.
Steven Mensor, vice president of marketing at Achronix, claimed: “This will fundamentally change how people design with FPGAs. The NOC is the equivalent of an operating system to a programmer. It isolates people from the difficulty of connecting to various high-speed I/Os.”
The intention behind the design was to able to drive I/O such as 400G Ethernet at maximum speed using programmable logic, something that he claimed is not possible with conventional FPGAs. A key issue in networking designs cited by Mensor is the dramatic drop in achievable clock rate once data leaves a hardened peripheral core such as a 400G Ethernet media-access controller (MAC).
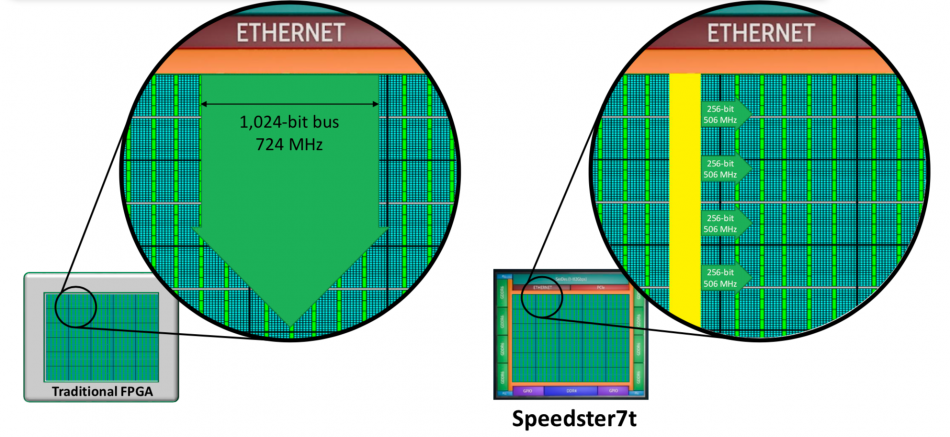
Image The Speedster 7t NOC splits data passing from the Ethernet core into the fabric to reduce the control overhead
Mensor argued that a conventional FPGA networking-controller design would need to deploy a bus some 1Kbit wide in order to be able to ingest the data coming in at the full rate. And that bus would still need to be clocked at more than 700MHz. Increasing the bus width to 2Kbit would increase area consumption dramatically and lead to less than a 100MHz reduction in the clock rate required.
Direct connections
For the Speedster 7t, which uses TSMC’s 7nm process, Achronix engineers decided to connect the Ethernet MAC directly to the NOC and build control logic that can split the incoming data into chunks that are delivered over four 256bit buses running at a more feasible 500MHz into the programmable-logic. For packetized data, the controller will keep frames and headers together and deliver consecutive packets to different buffers based on loading. If the designer wants to treat the incoming data stream as contiguous, the controller can be directed to treat the four buses as one so that the design is closer to a conventional structure, but without the need to implement the splitting and redirection logic in LUTs and programmable interconnect.
Inside an outer ring that delivers data to the onchip memory controllers and PCI Gen 5 interface, the NOC is implemented as a collection of bidirectional 256bit-wide rows and columns, passing 2Gbit/s each way. Access ports close to the intersections pass data into the fabric and allow data to move from a row to a column or vice versa. As well as being used for I/O-to-fabric transfers, the NOC can connect distant programmable-logic clusters instead of using the standard FPGA interconnect. Logic inside the FPGA can use AXI transactions to talk to peripherals or to other embedded controllers. Mensor likened the architecture to a freeway network that sits atop a conventional street network. He claimed the availability of the NOC would help to reduce the “pulling effect” that tends to increase congestion in FPGAs because of the need, with a conventional interconnect fabric, to place interoperating blocks close to each other on the floorplan.
For the Speedster 7t, Achronix has decided the HBM and HBM2 memory interfaces will remain too expensive to be practical for many designs although they can offer extremely high bandwidth for offchip storage. Instead, the company has implemented controllers that support the GDDR6 interface in addition to the more conventional DDR4.
As well as networking designs, Achronix has its eyes on the expanding market for AI accelerators, many of which will be deployed in arrays interconnected by 400G Ethernet or custom links based on same 112Gbit/s PAM4-encoded PHYs.
AI support
“In AI, there are so many different algorithms being applied and new algorithms are being envisioned all the time and there is a lot of change,” Mensor noted, making it difficult to build fully hardwired engines to handle the evolving workloads. Even the number formats keep changing as optimisations in deep learning have led inferencing development to first favor byte wide variables before moving onto binary and ternary datatypes. In Achronix’ view, this pace of change leads to a strong demand for programmable logic as an alternative processing fabric, particularly as conventional lookup tables can implement the narrowest datatypes efficiently while byte and word integer formats can be directed to hardwired processors such as the machine-learning processors (MLPs) in the Speedster 7t.
In contrast to prior arithmetic blocks on FPGAs, which tend to focus on DSP filters, the Speedster 7t’s MLP is designed primarily for matrix arithmetic and implements several 16 it floating-point formats useful for machine learning, with one designed for Tensorflow. The integer units are fracturable. “Worst case, I believe we are 4x the density of MACs [versus competitors] for any number format,” Mensor claimed.
Density on floating point is helped by the incorporation of a block floating-point mode that only operates and shift mantissa bits while the exponents of all the operands remain fixed. According to Mensor, this structure makes it possible to have more operations running in parallel for the same amount of logic as there is no need to implement a wider accumulator to allow for a normalization operation at the end.
To improve matrix and convolution-kernel throughput, the MLP has two tightly coupled memory blocks. One acts as a register file for data elements that will be reused many times by the kernel and another 72Kbit block RAM for other temporary data. Nearby MLPs can share data using cascade links.
To allow development using the common AI frameworks, Achronix is writing low-level libraries that are intended to ease the porting of code from the workstation or cloud environment to FPGA-based implementations. In anticipation of the big cloud operators and other companies moving to multichip modules, the company also plans to make versions of the Speedster 7t available in chiplet form in addition to providing the core fabric in IP form for integration into monolithic ASICs.