PCI may provide key to OCP chiplet standard
A group set up by Netronome and a small group of IP and silicon vendors to create standards for chiplets to be used in server accelerators is looking to base the core inter-die communications interface on the PIPE protocol of PCI. The approach could avoid the need to pick one of many emerging low-power physical-layer interfaces.
Late last year, Netronome recruited GlobalFoundries – which has decided to focus on multichip integration since giving up 7nm development – along with Achronix, NXP, SiFive and others to form the Open Domain-Specific Architecture (ODSA) Workgroup. This effort has now been absorbed into the Open Compute Project (OCP) organization formed to create standards for data-center products.
During a talk on ODSA at last week’s OCP Summit (March 15, 2019), Netronome engineer Bapi Vinnakota said the number of companies involved with ODSA has grown to 35 and that the workgroup plans to build a proof-of-concept multichip module suitable for use on an OCP-compatible daughtercard that will likely include external photonics ports using existing parts provided by members, including Achronix, Avera Semiconductors, Netronome, Sarcina and zGlue. The exercise will help identify issues with integrating chiplets from multiple vendors. In tandem, the group wants to define an “open cross-chiplet fabric interface”, he noted.
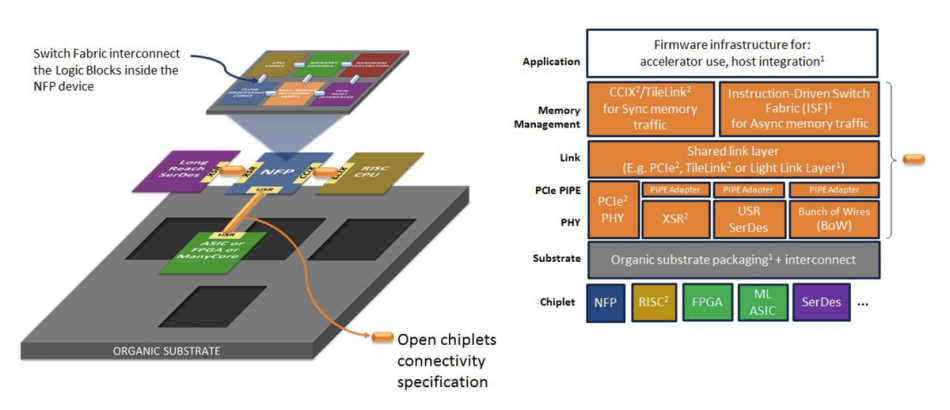
Image The OSDA Workgroup wants to focus chiplet interconnect standard on the PCI PIPE abstraction
Vinnakota said, with the exception of system-in-package (SIP) products that use HBM for high-speed memory integration, most chiplet-based designs use devices designed by a single vendor. Examples in use today include the larger FPGAs made by Intel Programmable Systems Group (PSG) and Xilinx. In 2015, Marvell said its AP806 and Armada A3700 products were based on chiplets integrated into what the company called ”virtual SoCs” based on an inter-die extension of its onchip bus interface called MoChi. The physical-layer interface in the chiplets uses IP from one of the ODSA Workgroup’s first members: Kandou.
The motivation for the work is to reduce the cost of designing accelerators for server applications that, because of their domain-specific nature will serve markets too small to justify the cost of designing complete SoCs on leading-edge processes. “Only the biggest can afford to build these devices,” Vinnakota said.
A second problem Vinnakota argued is that, for those startups and internal groups trying to create accelerators, much of their time is spent building the ancillary functions that will hook their IP into the server infrastructure. He cited one startup he had talked to which had raised Series B funding but found two-thirds of that would be needed to design and build the management processors and I/O needed to realize a complete accelerator SoC.
By moving development to a chiplet-based design, he argued much of the funding could be focused on core competencies: “Don’t burn your dollars in building this large monolithic die. All accelerators have three or four things in common but only one is specific to acceleration.”
A key development in the evolution of chiplet-based SIPs is the emergence of low-power serdes IP. A white paper produced by the group late last year identified a number of options that can offer energy consumption down to the level of a couple of picojoules per bit that is needed to make the architecture feasible.
Rather than attempt to pick one of these candidates, the Vinnakota said the current aim of the group is to work at a higher level so that users can decide on which PHYs they implement and demand from suppliers. Already supported by accelerator-focused PCB-level standards such as CCIX, the group sees PCI’s PIPE as a potential platform for the interface standards. This could support both cache-coherent interconnects such as CCIX, OpenCAPI and SiFive’s TileLink as well as non-cache-coherent bulk-transfer links.