Ceva adds hardware to speed up deep learning
Ceva has launched the fifth generation of its vision-oriented digital signal processor (DSP) core family with an architecture tuned for the fast-growing area of convolutional neural networks (CNNs) and deep learning.
Unveiled at the Linley Processor Conference, the XM6 extends the vector-oriented DSP of its XM4 predecessor but adds a dedicated hardware unit for the computationally and memory intensive convolutional layers of a full CNN stack.
“The most time-consuming layers are the convolution layers. If we can take out those layers and accelerate them you will gain additional performance,” said Liran Bar, director of product marketing. “But in deep learning, we believe there is still room for flexibility. If you decide to have all the layers on a fixed-hardware solution you will be limited in terms of what types of layers you can support in the future. Who knows what will happen with neural networks until then?”
Since the launch of the XM4 around three years ago, Ceva developed a conversion tool to take neural networks developed using open-source platforms such as Caffe and Google’s TensorFlow, and which typical employ floating-point arithmetic into fixed-point versions suitable for the DSP. That tool has been extended to handle the additions to the XM6, with the ability to not only split the network between the conventional DSP and the convolutional accelerator so that they run in parallel but perform some manipulations to improve overall efficiency.
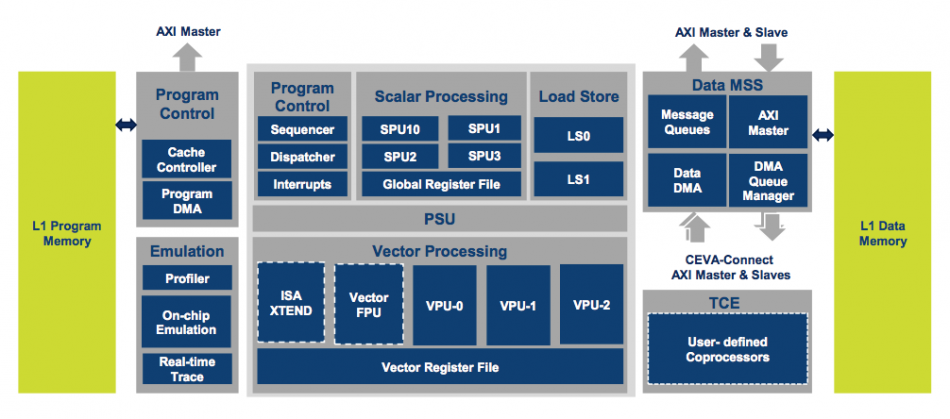
Image Block diagram of the Ceva XM6
The result, Bar claimed, is an engine able to run the AlexNet/ImageNet and GoogleNet Challenge benchmarks around four times faster than an nVidia TX1 graphics processor and with 25 times greater power efficiency.
The hardware changes made to the XM6’s fully programmable processor section extend from what Bar regards as the relatively straightforward measure of adding multiply-accumulate (MAC) units to more subtle changes to the memory-management unit that funnels data in and out of the processor core.
As well as the accelerator for CNNs, the IP house has added hardware implementations for other functions. “Where the algorithm is fixed it only makes sense to enhance performance by extracting the relevant function from the DSP and moving it to hardware. One example is for 360°-view cameras for ADAS. With those cameras, the fish-eye lenses used by manufacturers have a distortion that is almost fixed. There is nothing new in terms of algorithms to perform the dewarping,” Bar said. So the company put image dewarping into a hardware accelerator.
“One of the major changes made in the XM6 was in the vector unit,” Bar added. “In the past we had two VPUs [vector processing units]. Now we have three, which allows us to have better utilization. The other thing is that we enhanced the scatter-gather memory-load mechanism. It improve performance not only on computer vision algorithms but neural networks.”
Bar said the changes to the scatter-gather unit help improve the flow of data into the execution units. The scatter-gather unit manages the loading of data values from different parts of the external memory into contiguous registers so they can be processed easily by the VPUs. Ceva made improvements to the sliding-window technique introduced on the XM4 that takes advantage of the overlaps between image areas used by many computer-vision algorithms.
