Cadence tunes fixed-point DSP for neural networks
Cadence Design Systems has launched its latest parallel DSP – one that is aimed squarely at convolutional neural network (CNN) processing in embedded systems – instead of adding specialized instructions to an image processor. However, the Vision C5 has much in common with the P5 and P6 image processsors that preceded it.
The architecture is broadly the same as that of the P6 but without the SuperGather engine that was introduced to deal with image-processing algorithms such as warping and histogram functions. Instead, the fixed-point-only C5 deploys four times as many multiply-accumulate units (MACs) that can run in parallel, armed with instructions that have been tweaked to deal better with the memory-access quirks of CNNs. A further addition is support for on-the-fly decompression of data. This is aimed primarily at the banks of coefficients needed for each layer of a CNN, reflecting a more general trend in CNN design to try to reduce memory bandwidth demands in embedded systems.
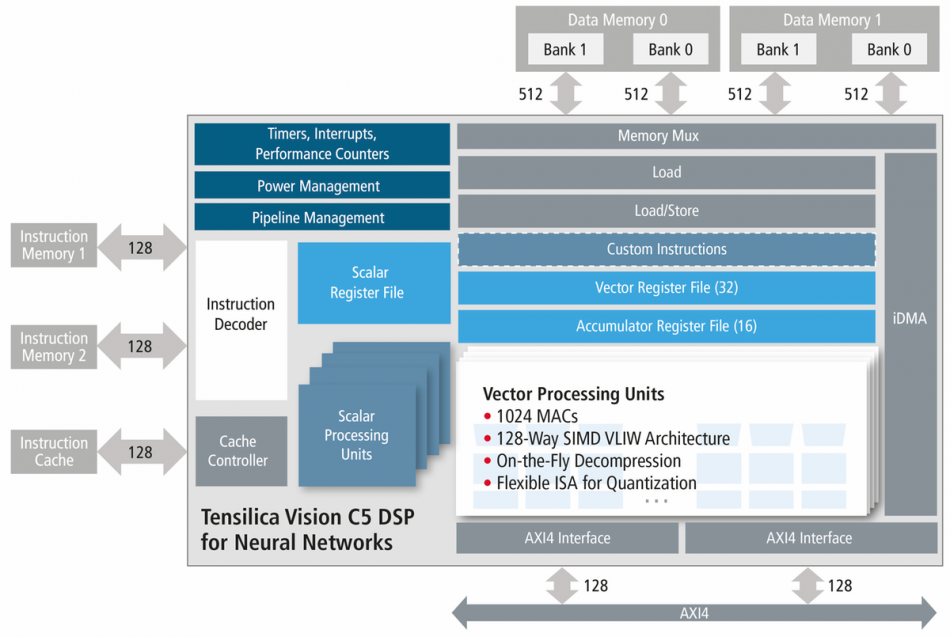
Image Block diagram of the Cadence Vision C5
Having avoided implementing hardwired coprocessors for throughput-intensive tasks such as the convolutional layers that form the core of a typical CNN, Cadence’s argument is that a fully programmable engine based on a fairly conventional SIMD DSP pipeline allows for optimization of memory. In principle, kernels can be merged more easily if all the data is already local. Local operation avoids the need to copy data to the buffer of another coprocessor when it takes over the workload. However, such considerations may be dwarfed by the bulk of the memory operations being repeated accesses to the large banks of input data and neuron coefficients, which will be to and from whichever processor is acting on them at the time.
The earlier P6 implemented a bunch of instructions tuned for CNNs based on extensive application profiling. The key, as described by Greg Efland at HotChips last year, was to take advantage of the way that many CNNs stack up maps into a cubic data structure. This stack provides a way to access memory more efficiently. If you create a window that takes a data element from each slice of the stack of maps needed for the layer, your opportunities for caching data inside the register file compared to running a bunch of convolution kernels in parallel for a single slice and stepping through each layer one by one.
Cadence said the C5 introduces further instructions that are intended to improve the handling of memory accesses by the MACs and so have more operations run in parallel for a wider range of CNN layer types.
The MACs can operate as 16bit units or divided into two 8bit datapaths to suit the heavily quantized data and coefficients that result from heavy optimization of trained networks. The company has implemented a set of compiler tools that take the output from environments such as Caffe and Tensorflow and map them onto the C5’s instruction set.