Ceva dedicates hardware to deep learning
Ceva has developed its first processor architecture aimed squarely at deep learning.
Although it borrows from the company’s earlier work on neural networks, Ceva regards the NeuPro as the first core it has developed inhouse since the company started in 1990 that is not classed as a digital signal processor (DSP). The NeuPro hardwires a number of core deep-learning functions in an architecture that is meant to limit the demands these algorithms place on memory bandwidth and, with that, power consumption.
Liran Bar, director of product marketing for imaging and vision at Ceva, said: “The core will be available for lead customers in Q2, with general availability following in Q3.”
Typically, the NeuPro will sit alongside a more conventional vector processing unit (VPU) from Ceva. The NeuPro engine can also be licensed separately by customers for use with their own vision or audio processors. The VPU will typically run conventional signal-processing algorithms, such as image warping to provide a preprocessed data for the neural networks as well as customized deep-learning layers and managing the flow of data through a stack of neural-network layers. But the three fundamental building blocks of today’s deep-learning architectures are handled in dedicated execution units. “The architecture has the flexibility to cope with neural-network changes that might be made in the future,” claimed Bar.
The NeuPro integrates multiple multiply-add units (MACs) into a section dedicated to handling the neuron-weight calculations for convolutional and fully connected layers, with the aim of keeping as many of the data elements within the confines of the execution units while they are needed. The execution unit includes functions to handle the padding of convolutions at image boundaries, avoiding the need to go into software for these edge conditions.
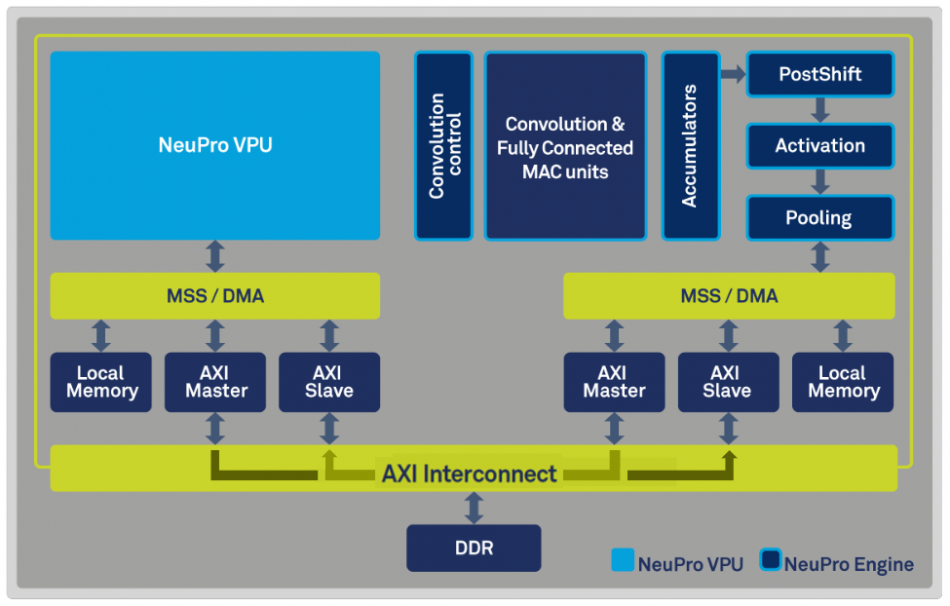
Image Block diagram of the Ceva NeuPro
The results then move into a series of units that handle tasks such as activation, using common functions such as tanh and reLU, and the pooling stages that commonly follow a stack of convolutional layers. “Activation and pooling can be done on the fly without going to the memory,” Bar said, adding that the flow of data between activation and pooling stages can be reversed to cope with situations where downsampling is performed before the activation function is applied.
In designing the NeuPro, Ceva’s architects opted to use two fixed-point data resolutions — 8 and 16bit — and not implement half-precision floating point. “For half-resolution floating-point, you pay a high price in power and area,” Bar said, adding that 16bit fixed-point offers sufficient precision for training. Once trained, the resolution used during can, in many cases, be trimmed to 8bit. Bar noted that AlexNet and GoogleNet among others continue to perform well when converted to 8bit. The precision can be selected on a layer-by-layer basis.
The architecture is designed to perform both inferencing and local training using the same core architecture. Future versions may offer lower resolutions, depending on the progress of R&D on reduced-precision weight calculations.
“We haven’t seen networks trained on 4bit,” Bar said. “But people are starting to talk about binary networks.”
As with Ceva’s previous forays into deep learning with its vector signal processors, the NeuPro is supported by the CDNN software package. This can take networks trained and optimized on servers and convert them to fixed-point versions that can run on the embedded platform. It performs parallelization analysis to work out which layers can be run simultaneously to maximize throughput through the MAC arrays. Experiments on ResNet-50 converted for the NP4000 implementation of NeuPro demonstrated a 61 per cent speedup over the previous version running on the XM6 processor.