Semidynamics adds flexible vectors to RISC-V cores
Semidynamics has released a customizable vector unit to accompany the 64bit RISC-V processor cores the company has designed for high-performance computing systems.
The company has built the unit according to the RISC-V Vector Specification 1.0 standard and offers the ability to tailor the design to a variety of datatypes ranging from full 64bit floating point down to 8bit integer as well as the 16bit block-float (BF16) format now used in machine-learning accelerators. A vector unit built using the core IP is made up 4, 8, 16, or 32 vector cores, each of which performs multiple calculations in parallel on a vector of operands. The result is a pipeline fed by a data bus up to 2048bit wide.
Semidynamics has equipped its vector unit with a network that provides all-to-all connectivity between the vector cores and which supports instructions in the RISC-V standard that shuffle data between the different vector cores, such as vrgather and vslide.
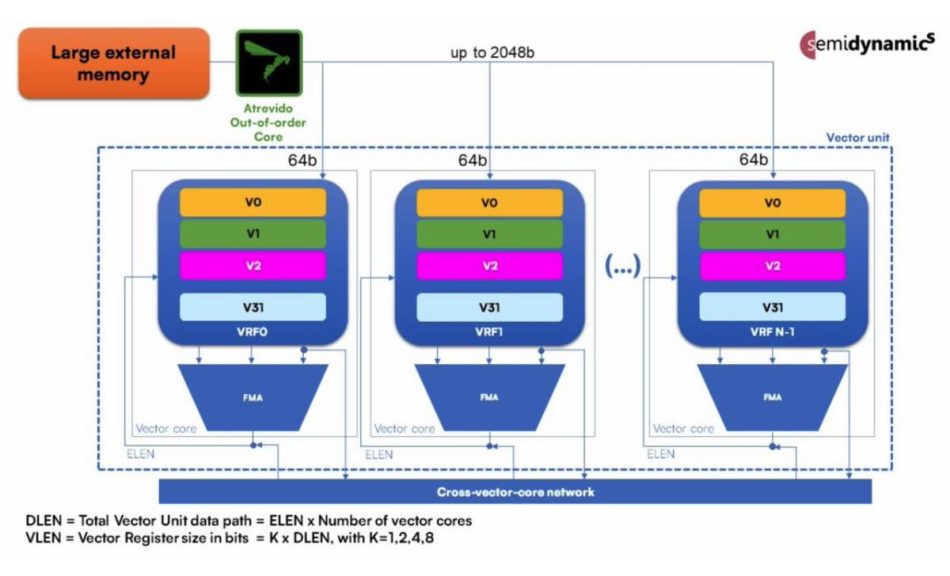
Image Block diagram of Semidynamics' vector unit
The number of bits of each vector register can also be tailored to customer’s needs, with the vector register being up to eight times wider than the data pipeline. This allows tradeoffs of cycles per instruction that may make more sense where high memory latency is an issue or where die area or energy consumption are at a premium.
“This unleashes the ability for the Vector Unit to process unprecedented amounts of data bits,” said Semidynamics CEO and founder Roger Espasa. “And to fetch all this data from memory, we have our Gazzillion technology that can handle up to 128 simultaneous requests for data and track them back to the correct place in whatever order they are returned.”
Another less common attribute of the vector unit is that it supports register renaming for out-of-order execution and handles the correct updating of operations that work on partial vectors. The support for out-of-order execution, which goes hand-in-hand with the processor core launched earlier, is designed to improve the tolerance of high memory latencies particularly where scatter-gather operations are used to fetch and align data vectors.