Tensilica DSP extends pipeline for performance
Cadence Design Systems’ Tensilica division has launched a variant of its Vision P6 processor core to tackle embedded designs that need to run a mixture of imaging and deep learning-type algorithms.
The Q6 uses super-pipelining to increase its clock rate and effective throughput, pushing the expected speed on a finFET process from around 1GHz to 1.5GHz. Pulin Desai, product marketing director in the Tensilica group, said it would have been impractical from a programming standpoint to boost throughput by adding more instruction slots to the existing very long instruction word (VLIW) in the processor’s vector unit.
For the Q6, Cadence has attempted to ease the programming burden and improve throughput for code that mixes complex control and vector operations by giving the scalar execution unit its own data cache. To avoid excessive branch penalties in the deeper, 13-stage pipeline the architects opted for a beefed-up branch-prediction unit.
“Compared to the P6, we can get two times higher performance on some of the imaging filters,” Desai claimed.
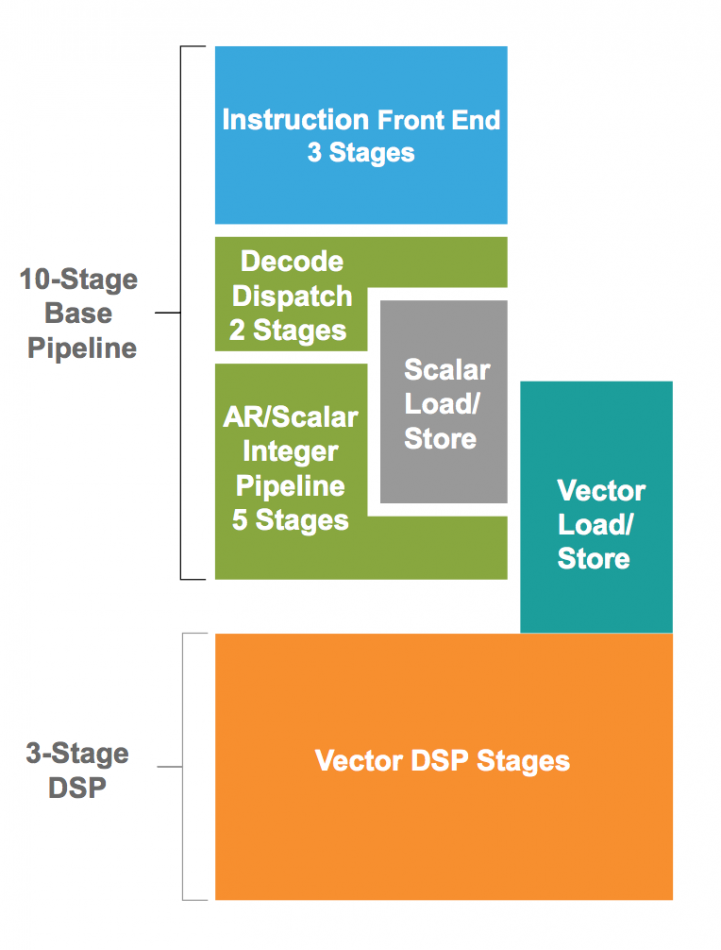
Image Pipeline of the Vision Q6 core
To support inferencing by neural-network models, Tensilica has added a number of specialised vector instructions, focusing primarily on 8bit operations. In common with others working on inferencing on embedded systems, 8bit resolution for neural weights and other data appears to offer the best tradeoff of accuracy and performance for a given power budget. There is some loss of accuracy, but for typical benchmarks, the difference in classification against the server-based model is apparent for less than 1 per cent of the test inputs.
To also help deal with the prodigious memory bandwidth requirements of neural networks, Tensilica is taking the approach of supporting on-the-fly decompression for neuron weights as they are loaded into the register banks for processing.
The company has converters for commonly used environments such as Caffe and Tensorflow so that models trained on servers using floating-point arithmetic will run efficiently on the Q6. The company also has support software for the Android Neural Network environment that forms part of release 8.1 of the mobile operating system.