Software puts deep learning onto embedded DSP
IP supplier Ceva has put together a software package that is intended to streamline the porting of deep learning and convolutional neural network implementations to the company’s XM4 image- and signal-processor core.
Yair Siegel, director of marketing for Ceva, said: “The idea is to bring in networks that have been pre-tuned on the PC and enable them to run on camera at low power, and bring deep learning technology to the embedded space.”
Aimed at applications such as object recognition, driver assistance, vision analytics, and augmented and virtual reality, the Ceva Deep Neural Network (CDNN) takes a neural network that has been tuned and trained on a workstation and converts it to run efficiently on the XM4. Part of the process involves converting the floating-point operations used by workstation-class software to fixed-point instructions that can run more efficiently on the DSP core.
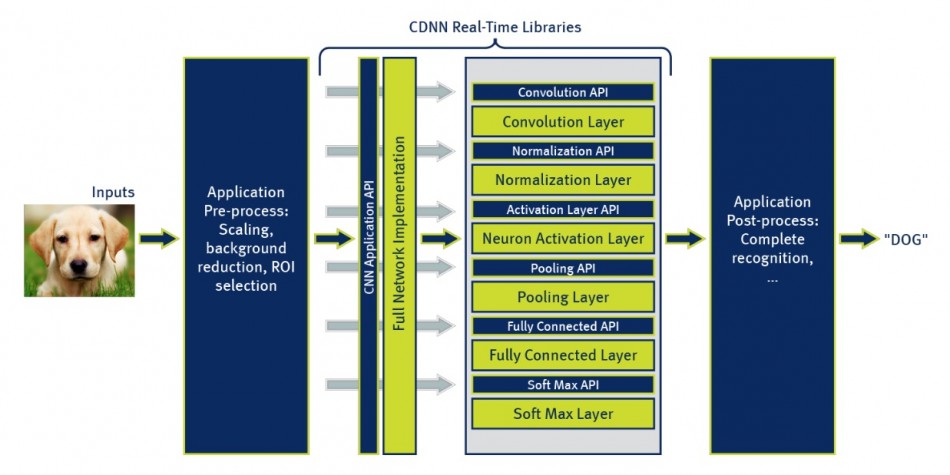
Image CDNN architecture
Siegel said the key advantage of an approach based on deep neural networks is the relative ease with which they can be trained to detect different objects or situations once an appropriate neural-network has been found. Most deep-learning algorithms rely on a particular arrangement of specialised layers that typically reduce high-dimension data, such as 2D images, into vectors with low dimensionality that contain relatively high-level information on the contents of the source data.
“With deep learning, you can write the code once. Then, once written, the same algorithm can be adapted to identify different objects,” Siegel said.
Ceva has signed a partnership with Phi Algorithm Solutions, one of the new crops of companies providing off-the-shelf neural-network stacks. “They are bringing a universal object detection algorithm based on deep learning. It can be adapted to many different objects,” Siegel said.
Siegel said the framework, which is based around the Caffe open-source software developed by researchers from the University of California at Berkeley, can handle an arbitrary number of layers with APIs used to pass data between specific types such as convolutional, pooling, and fully connected layers.
Although the core conversion process is automated, the API can be used to provide a greater degree of control over the way in which the network is mapped to the DSP and whether specific layers use fixed-point or floating-point maths. For example, higher precision can be useful for fully connected layers.
Siegel claimed the architecture of the XM4 is well suited to handling 2D images through the memory handling features added to the core, such as the ability to perform scatter-gather reads in parallel to different parts of memory and support for sliding windows. With the sliding window support, as the window moves the memory controller only loads data from the area that is not already sitting in the local registers. The data already present is shifted and realigned to make way for the new data.
“We want to minimize memory bandwidth use, as well as the power it consumes,” Siegel said, adding that the architecture provides more flexible support for future developments in deep learning than dedicated hardware. “Qualcomm and others talk about dedicated hardware for deep learning. That might be nice in the future, but because this market is changing very rapidly there is an advantage in having a programmable solution.”
According to Ceva, an implementation of the AlexNet neural network on the XN4 resulted in a 30-fold power saving over a version ported to a GPU.