Cadence deploys parallel strategy for faster synthesis
RTL synthesis has joined the array of tools developed by Cadence Design Systems that employ distributed processing, with the aim of exploring more ways of creating area- and power-efficient logic blocks.
The successor to Encounter RTL Compiler, Genus splits and distributes the blocks it processes at three different levels. For large blocks, the tool starts at the level of roughly 100,000-instance subblocks and working down to the unit level where the tasks are allocated to threads on a single server or workstation to try a number of different synthesis strategies in parallel to find the best fit for the design.
Paul Cunningham, Cadence vice president of R&D who moved over 18 months ago to front-end design at the company from his former focus on implementation tools such as CC-Opt, said synthesis needs to be able to cope with the diversity of design types – ranging from ultralow-energy IoT designs through mobile appliances up to cloud computing SoCs. This requires the exploration of many different gate-level outcomes to find the best fit for the design. “It’s anything we can do to get better power and area,” he said.
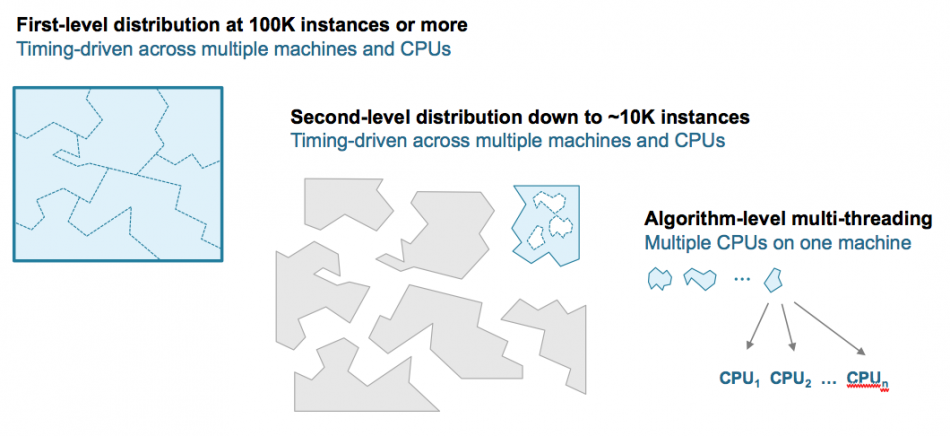
Image Parallelization strategy used by Genus to divide blocks among CPUs
Architectural analysis
The synthesis optimizations in Genus have focused on architectural transformations, not dissimilar to some of the techniques used in system-level synthesis. “Those are hugely powerful in trading power, performance and area. We characterize many different architectural transformations of the design. Every one of those configurations is a point on a curve. We funnel all of those results into an analytical solver to decide on the globally best PPA,” Cunningham said.
A customer test on a video codec block led to a 16 per cent improvement in area with the runtime halving to just under 15 minutes.
The decisions extend to considerations of different types of logic that can minimize attributes such as power for certain processes. For example, power consumption caused by glitches has emerged as an issue in finFET-based designs because the devices have focused attention back on dynamic power (Guide) and because some of the physical techniques for glitch minimization are not available with quantized devices.
“Power cost is one of the calculations, so it may pick a configuration that uses low-glitch arithmetic,” he said.
Cunningham said the use of architectural exploration in RTL synthesis may lead to more designers expressing their designs at a relatively high level rather than trying to overconstrain the synthesis through the use of almost gate-level constructs. “It’s like optimizing compilers for C++. Very few people use inline assembler now because the compiler generally produces better results. I believe that as our customers get more confidence in this approach they may change the way they write RTL.”
Iteration reduction
Although tools attempts to find the best candidate syntheses based on the current constraints, iteration caused by the need to hit power, area and timing targets as they become clearer from the implementation tools leads to numerous, time-consuming iterations. The job of optimizing the logic for implementation has to be done without forcing designers to iterate through full synthesis and place-and-route cycles many times over, Cunningham said.
Some iteration is inevitable, so the company has made it easier to iterate units and subblocks within the context of the overall block and SoC environment to make it easier to focus effort on problem spots.
“We can run the chip or a large block with the real floorplan with full physical synthesis of the kind that you would use for an over-the-weekend tapeout-ready run. Then cut out a section with a single command and from that run for a single RTL unit.”
The cutout section, which may be a single unit of RTL, carries the timing context within which the unit is sits in the full chip so that it can be used to constrain synthesis. “A designer might want to run synthesis on that unit five times in a day as it’s optimized,” Cunningham said. “The synthesis is done with a complete understanding of the interfaces, how it communicates with the memories and other blocks. We are bringing the physical further into synthesis.”
Cunningham claimed the use of auto-generated constraints from the chip-level context should at least halve the number of unit iterations.
Implementation correlation
Genus shares a lot of its implementation approaches with Innovus that, the company claims, leads to high correlation of results between the two tools which should cut the number of iterations there. “Innovus and Genus change the game in terms of unification, so we can deliver very tight correlation,” Cunningham claimed, pointing to techniques such as how the effects of wire-length are calculated. Genus takes into account the effects of wires to other nodes on the same wire to compute total wire-length and the effects.
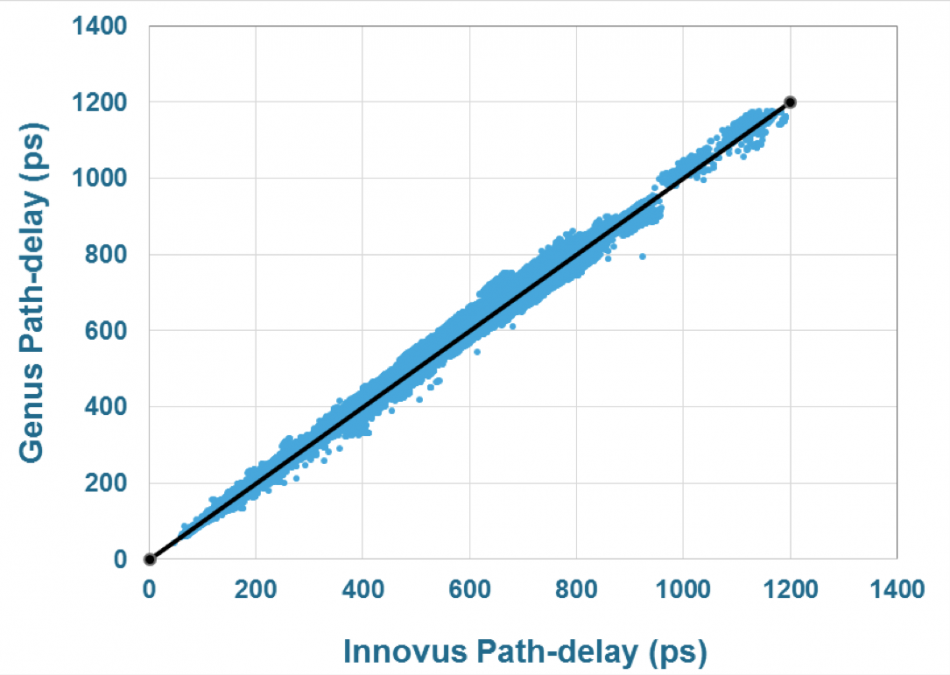
Image Correlation for path-delay results between Genus and Innovus
Cadence said the difference between Genus and Innovus on path delay is to within 5 per cent, an improvement of 50 per cent over the previous generation of tools. The wire-length difference have halved to 1 per cent.
Parallel strategy
The parallelization used by Genus comes in three stage. The first stage groups chunks of logic that can be split off from others reasonably clearly. “We can’t cut them up into equal-sized chunks, we need to be careful not to cause inefficiencies on the boundaries. There has been a lot of innovation and fundamental IP developed here about how we cut up and distribute the design,” Cunningham claimed.
“We then run the parallelization at two levels. There is a coarse-grained cut and then it’s divided into even smaller pieces. That provides a lot of opportunities to speed things up across a network. Then, at the algorithm level, we leverage different threads in the same machine to try different approaches on the same unit. That final stage is one that has been around for some time,” Cunningham added.
“The parallelization scheme can kick in on even modestly sized blocks,” he said, adding that the approach allows for different types of server farm. “I could take a huge design and run it across 16 high-performance servers or a hundred smaller machines and it doesn’t matter.”