Sonics updates tune memory and link width for speed and power
The latest release of the SonicsGN on-chip network (NoC) infrastructure provides speedups for multichannel memories that are more suitable for use with standard cache architectures than simple wide-memory structures as well as better layout optimizations for flows based on physical synthesis.
Sonics CTO Drew Wingard said: “This release is mostly focused on improving memory system performance. Use of multichannel DRAMs and memory sub-systems is now pervasive in SoC designs, for example, in mobile applications where maximizing memory throughput takes precedence over increasing memory capacity. So the biggest headline element is enhancing performance for multichannel DRAM.
“To get to their target bandwidth, people are using DRAMs in parallel. But when they use parallel channels, the amount of data delivered by even a minimum-size burst gets very big. The cache line size is normally 64 bytes for an ARM processor. When you have a 128bit-wide bus delivering 8-word bursts, that’s too big to be efficient.”
Reorder control
To make better use of the available bandwidth, it makes more sense to interleave memory accesses from different masters so that the DRAMs can still be used in parallel but to support unconnected transactions at the same time. However, this requires a level of transaction mapping not just for the DRAM controllers themselves but for the interconnect protocols commonly used in SoCs, such as ARM’s AXI.
“One thing that’s interesting about AXI is that it has ordering IDs, but there is no flow control associated with them within AXI itself,” said Wingard.
Instead, in the case of AXI, masters are expected to handle the transaction reordering that needs to be used to maximize multichannel-DRAM throughput. “That raises the issue of getting deadlocks,” Wingard said. “So, we have introduced reordering buffers. One we had that, there was a bunch of other things we could do. If I have a core that doesn’t use AXI and it needs transactions to be strongly ordered I can use pseudo-IDs and use the reordering buffer to put them back together in the expected order. Also some blocks say they are AXI compliant but don’t support reordering, so we can deal with those.”
Physical assistance
The other main change for SonicsGN 3.0 is to align the network connectivity with a physical fabric that may span multiple clock, voltage, or power domains
Wingard said: “When we generate a netlist for multi-power domain designs, we have to generate hierarchies. People generally want the logical hierarchy to match physically. But at the top level there will be links that cross boundaries and they can get long so that they need retiming elements. You have to deal with questions such as: which power domain do we put them in? Is the retiming associated with the sender, receiver, or sitting in the middle?”
By providing this information up-front and carrying it through to the implementation flow, it “gives the place-and-route tool an easier problem to solve. And you can visualise where the elements sit.”
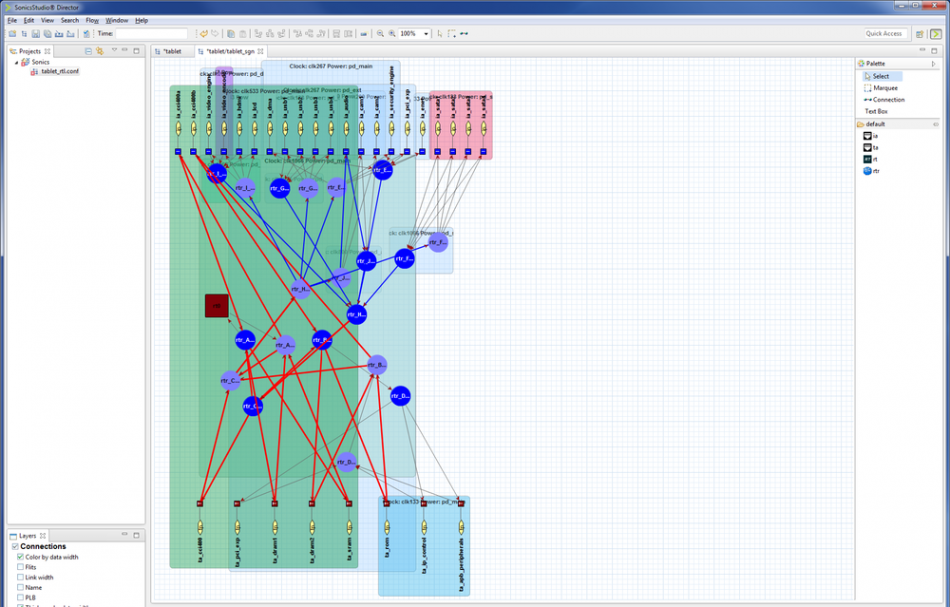
Image NoC layout and color coding in SonicsStudio v8
Better visualization was one of the objectives of the version 8 release of SonicsStudio, announced around DAC.
“One of the unique capabilities is to show clocking, power and data demands. The components are now colored in one clock domain or another, so it is easy to see the various hookup decisions. You can also see latency. As a customer makes choices about interface timing and retiming, they can see and add up tick marks along the path,” Wingard said.
“One of the unique capabilities that we have is that [network] switching elements can have independent data widths coming in. So we can show those based on line width.”
Width tuning
Wingard said the ability to tune bus width can be an effective weapon in reducing power, especially for those that do not need to deliver sustained bandwidth. “You can save a lot by using narrow links. We added a very cool capability: we learned along the years that analyzing the power of an onchip network can be difficult to do. Some parts connected to network are highly active, others not so much. We have an environment for generating traffic for different use-cases. After you’ve generated the netlist, you can run it in simulation and use that to get accurate node switching information that you can then feed to power-aware synthesis.”
Simulation based on the network topology can be used to track performance problems, Wingard said. “The level of instrumentation in simulation environments varies. However, VCD is pretty standard and we can take one of those files and pull it into the environment, which goes and stitches the activity on each interface into end-to-end transactions. That lets you see where something got stuck in a buffer. It makes it easier to home in on performance problems.”