Xilinx plans reconfigurable compute for 7nm FPGA generation
Xilinx plans to make reconfigurable computing the focus of its upcoming generation of FPGAs, which will be made on a 7nm finFET process at TSMC and expected to start sampling next year.
The family of FPGAs, which Xilinx has codenamed Everest for the moment, will greatly expand the use of hardwired compute cores beyond the arithmetic logic unit (ALU) slices that are used today to build datapaths for digital signal processing (DSP) operations. Xilinx aims to use the reconfigurable compute cores to underpin applications such as machine learning. In a break from conventional FPGA design, the cores will be accessed through a network on chip (NoC) rather than through the fine-grained FPGA interconnect fabric where the existing DSP and distributed-memory blocks sit.
Although the company has indicated the new compute engines will be supported under languages such as C/C++ and Python as well as RTL hardware-design tools, Xilinx has provided no details on the internal architecture of the compute engines.
“There is an instruction set, but we will hide that under the hood behind libraries and APIs,” said Xilinx CEO Victor Peng.
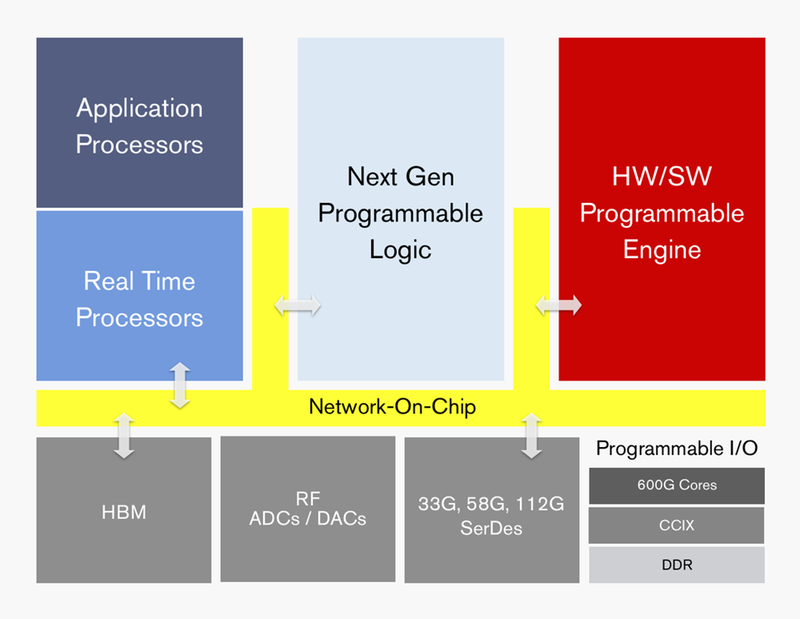
Image High-level block diagram of the Xilinx Everest architecture
Peng explained the Everest adaptive compute acceleration platform (ACAP) is a response to the “explosion of data” that has led to rampant growth in data-center compute. “It will require a different form of computing. We are in the very early stages of AI. This will disrupt multiple industries.
“We are really at an inflexion point where we have moved beyond the FPGA. It is a new product category: a heterogeneous processing platform. Because of that we can accelerate a broad range of workloads.”
Everest is also a response to the problems of silicon scaling. Peng said: “What do you do when Moore’s Law is slowing or stopped completely? I’m in the camp where it’s stopped. It’s not that we don’t know how to get to the next node it’s just how we get to the cheaper part. Going to the new process node doesn’t give you faster, better, cheaper.
“We expect everything that has semiconductor content to just get better, faster, cheaper and that’s just not true anymore. We are now in a phase where we are moving to a different form of computing and we are seeing disruption across a broad breadth of applications. Because things are changing so dynamically this connected world needs to be adaptable,” Peng argued.
The combination of expensive leading-edge custom design and requirement for compute engines that can be reconfigured on the fly to handle changes in applications in Peng’s view should force more of the future market to ACAP platforms. One of the underlying changes made to Everest will be to support faster partial reconfiguration than in the existing Xilinx devices.
As well as accelerators in data centers, Xilinx has its eyes on “cloudlets” that are likely to emerge at the edge of the internet, as well as greater use of machine learning and other applications that have high-throughput data-processing demands in its traditional markets.