Ceva extends control-oriented DSP
Ceva has followed its IoT-oriented Ceva-X series of processor cores with a more powerful family that is designed to handle control and signal-processing algorithms using the same pipeline.
Moshe Sheier, director of strategic marketing at Ceva, said: “Many applications are need this mixture. Whether wireless modems or motor control systems they blend more and more digital signal processing with control.”
The Ceva-BX has about four times the DSP throughput of the earlier Ceva-X by providing two scalar processors and a five-way VLIW DSP engine. The pipeline is longer than in the Ceva-X: running code with a maximum of 11 stages. This allows a maximum clock speed of 2GHz in TSMC’s 7nm process.
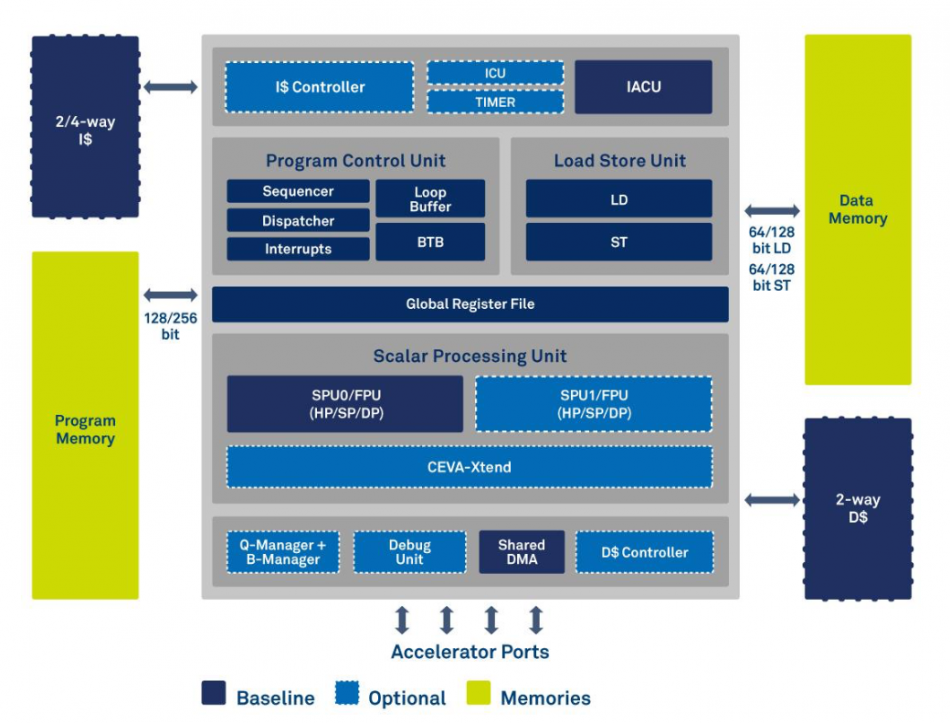
Image Block diagram of the Ceva-BX
There are two main flavors of BX, initially. The BX1 has a single 32×32 MAC and quad 16×16 MACs. The BX2 adds more MAC units to support four 32×32 and eight 16×16 operations in parallel.
The BX core has acquired some additional support for the operations used in neural-network inferencing, recognizing the shift to push this kind of work to embedded systems. As well as adding more parallel functional units, the architects reworked the variable-length instruction set to improve overall code density.
At the microarchitectural level, Ceva has added some functions to improve loop and branch latency. One is a small loop buffer of a size that suits tight DSP kernels. There is also a dynamic branch translation buffer that is designed to help speed up the branch performance of control code. A further change is support for branch-break instructions, intended primarily to help reduce code size. The LLVM compiler also gets some assistance with hardware support for a common symbol table to make it easier to combine operations in a single instruction.