Cadence adds deep-learning support to audio DSP
Cadence Design Systems has added direct support for neural networks to the latest iteration of its digital signal processor (DSP) cores aimed at audio systems, and built a software library to support the recurrent neural networks used in smart speakers and other voice-response systems.
Gerard Andrews, product marketing director for audio and voice IP at Cadence’s Tensilica operation, said the HiFi 5 was developed with the help of several partners that are already supplying products for voice response in embedded systems and with a view to capturing design-ins that need local deep-learning acceleration instead of handing everything off to the cloud. A typical use-case for a single HiFi 5 would be to perform both audio preprocessing, including beamforming, and simple deep neural-network (DNN) processing such as recognizing keywords and simple commands.
“The trend of what folks are doing in the home of offering these voice-controlled systems is encouraging the car manufacturers to improve the voice-control systems in their vehicles,” Andrews claimed. “And they can’t rely solely on the cloud to do voice recognition.”
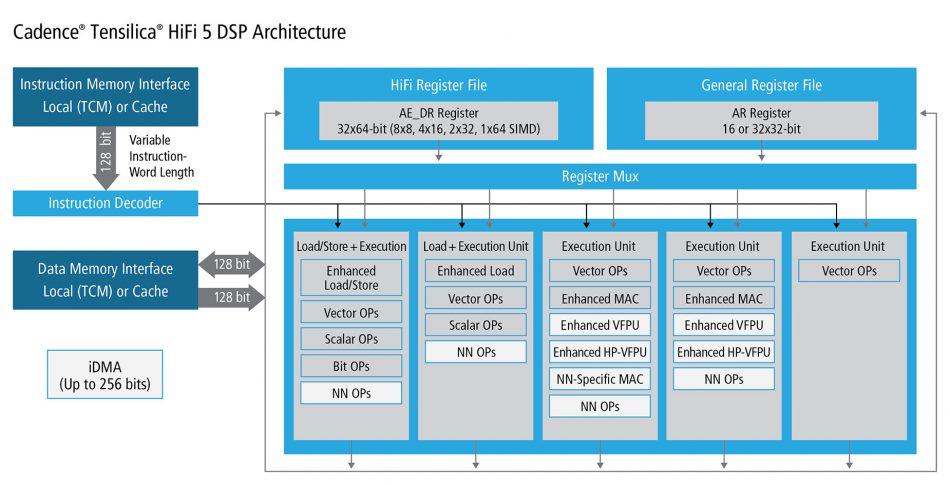
Image Block diagram of the HiFi 5
The HiFi 5 is configurable in terms of the execution units and memory controllers it can use. To support tasks such as beamforming, the DSP pipeline is able to use floating-point. This can be dropped in favor of the DNN-oriented units, which focus on lower-resolution fixed-point arithmetic, going down to numerous 8×8 multiplies in parallel. Alternatively, the DSP can be deployed without the DNN-focused modes for conventional audio processing.
“We doubled the fixed-point multiply-accumulate capability from the HiFi 4. To feed those multipliers we had to increase the load/store capability to a dual 128bit load/store design,” Andrews said.
The DNN-focused execution units contain a number of specializations that cater for the way that embedded inferencing has evolved in the past few years. One is support for weights down to binary and 4bit as well as 8bit. These still feed into the 8×8 MAC pipelines but the engine takes care of unpacking the weights when they are read from memory.
Similarly, there are squeeze and unsqueeze operations intended to support sparsified networks, which have large numbers of zero weights. The zero-weight operations still flow through the pipeline but the support in the HiFi 5 reduces the memory bandwidth needed to support sparse DNNs. This is in contrast to some other embedded DNNs, including Cadence’s recently launched DNA-100, where the zero-weight operations are removed from the pipeline so that the execution units can be redeployed.
“What we have is an architecture with a classic DSP heritage. Processors that were designed from the ground-up for neural networks can take advantage of these new architectures,” Andrews said.
A further optimization is direct support for activation functions, including tanh, sigmoid and ReLU, to avoid the need to load data from memory for operations that are used extensively in DNN pipelines. The library software for the HiFi 5 includes functions that are useful for the recurrent neural networks often used on voice processing.
One of the first customers for the HiFi 5 is subthreshold specialist Ambiq Micro. The company aims to build audio microcontrollers for small battery-powered systems that can handle speech recognition.
“To meet the extremely difficult challenge of bringing computationally intensive NN-based far-field processing and speech recognition algorithms to energy-sensitive devices, Ambiq Micro chose to be the first silicon licensee of Cadence’s HiFi 5 DSP”, said Aaron Grassian, vice president of marketing at Ambiq.