ARM, Ceva aim at multi-carrier modems
ARM and Ceva have both aimed at the need for to juggle control code and DSP in the upcoming LTE-Advanced and 5G with their latest processor core architectures. ARM is pushing a new iteration of its Cortex-R v8 architecture that uses out-of-order scheduling to try to improve throughput while Ceva has focused on bringing control-code support to its X series of DSPs.
Chris Turner, director of advanced technology for ARM’s CPU group, said advanced cellular modems need “microsecond granularity” to be able to handle the multiple parallel data streams that will pass through LTE-Advanced and 5G modems. “LTE Advanced sends data aggregated over a number of carrier frequencies. For 5G, we expect to see datarates up to 50 times faster than today. They will be managed in software rather than hardware as this will allow more flexibility.”
Emmanuel Gresset, business development director in Ceva’s wireless business unit, said high context-switch speeds are needed for multi-carrier data transfers and multi-RAT access. “When you get five carriers on LTE and need to use 3G as well, you need to be able to switch between them quickly much more than before.
“Up to now, multi-RAT has been done mainly with multiple independent modems. Tier-one customers want to combine them in a single modem. So what was acceptable for task switching isn’t anymore.”
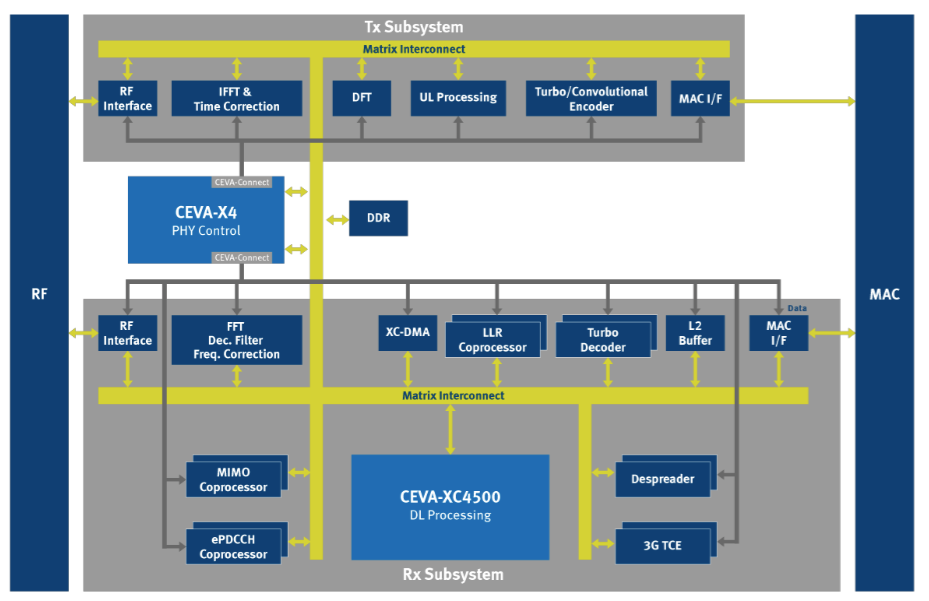
Image Ceva's proposal for a multi-carrier modem based on two X4 cores
Switch speeds
To improve context-switch speed on the Ceva-X4, the company’s proposed architecture for multi-carrier modems, the processor has shadow registers and support for multiple stack pointers to avoid having to push and pop values into memory on each switch. Data and instruction caches that can be up to four-way set-associative help reduce the chance of independent code streams from constantly ejecting each other from the caches.
Like its predecessors, the Ceva-X4 is a very long instruction word (VLIW) processor that will form part of a larger family of cores. “Ceva-X is an architectural framework for targeting baseband applications in general. Using it we will generate processors for specific markets,” Gresset said.
Although some of the architectural changes are aimed more at machine-to-machine communication protocols such as narrowband LTC, the rise of multi-carrier techniques to improve data-transfer rates has driven much of the design of the Ceva-X processor. Turner said the R8 is not designed purely for cellular modems – it is likely to find its way into storage arrays and solid-state drives similar to earlier versions of the Cortex-R family.
Control-code speedups
To reflect the greater emphasis on the ability to handle control code, Ceva claims an implementation of its Ceva-X architecture tuned for PHY control rather than dataflow can achieve on the EEMBC benchmark suite 4 Coremarks/MHz, and will run at up to 1.5GHz on a 16nm finFET process.
Ceva calls the pipeline in the architecture “zero latency”: it is a pipeline that although based on issuing instructions in compiled-code order allows out-of-order completion on non-dependent instructions so that it can initiate instructions on each stage after launching a multicycle operation.
In contrast, ARM has opted for out-of-order dispatch in the R8 in which the processor inspects the incoming instructions and reschedules them dynamically based on resource availability. This decision follows on from the existing dual-issue R7. Gresset said the core X4 processor is smaller and uses less power than ARM’s existing R7. “They are dual-issue out-of-order: we don’t pay the penalty of that.”
Turner argued the support for out-of-order instruction dispatch helps overcome bottlenecks in execution caused by memory stalls, particularly when the processor hits several loads and stores in a row that are held up by the need to fetch data from outside the cache or tightly coupled memories.
“What we see when we look at modem code is that you get sudden bursts of activity going out onto the memory bus. With in-order execution, you are more likely to stall. What we see broadly in benchmarks is that going out of order [for dispatch] is a breakthrough,” Turner claimed.
Turner said a quad-core array of R8s can achieve an EEMBC Coremark performance of 28,000 at 1.6GHz. That equates to a little under 4.4 Coremarks per megahertz per core.
Branch handling
Like its predecessors, the ARM R8 has branch prediction that helps keep the instruction pipeline fed, using a combination of branch-history tables and loop buffers.
In the Ceva-X, branch prediction is optional for applications where control-code speed is less important. But it has been beefed up from the previous generation, offering dynamic prediction based on history rather than static. Ceva has added instructions to help manage inter-task interactions such as atomic memory accesses, semaphores and support for supervisor and user modes.
Although many of the datapath operations will be offloaded to coprocessors, Gresset said core DSP is still needed as handset makers are moving the handling of older 2G and 3G protocols to software-only.
To work with coprocessors, Ceva envisages the processor using a separate interconnect to AXI, co-ordinated by a dedicated management bus. The CevaConnect use queues for each accelerator to relieve the processor from some of the data-transfer overhead. “You can sequence them without intervention from the X4,” Gresset said.