ARM explores multithreaded core as alternative to GPU computing
ARM is working on a heavily multithreaded version of its processor core to see if it can provide a more convenient alternative to graphics processing units (GPUs) for heterogeneous computing, CTO Mike Muller told delegates at the recent Hot Chips conference in Cupertino.
In his keynote, Muller used the example of dark silicon, a concept he introduced just over five years ago to describe the growing problem of powering logic on multi-billion transistor SoCs. He conceded that his prediction that some of the transistors on these SoCs would not be usable by today because his original assumption had been based on designers maintaining a constant power envelope.
“You can see what happened to the power budgets. What was a 200mW power budget has turned into 2W. I had took the idea of iso-power and run that forward to 11nm. What’s happened is that we haven’t gone iso-power on those chips,” Muller explained. “The mobile industry has grown into the thermal limits of the platform that they are in. But we do have I believe a dark-silicon problem coming. You hit those thermal limits by 10nm. If you want iso-power on that chip, you can only use 40 per cent of the transistors. You have to find techniques to make that work for you. There are some possible solutions but it’s still all about the power and always will be.”
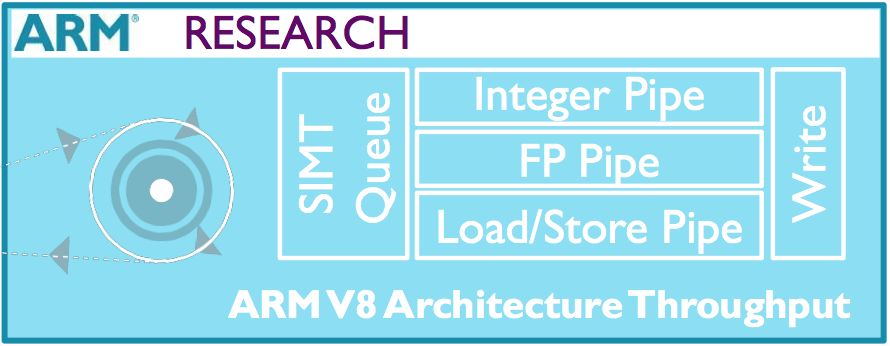
Image Conceptual block diagram of the experimental SIMT ARM
Muller claimed: “The obvious solution to the dark-silicon problem has always been heterogeneous computing. The first processor we did for Nokia was heterogeneous: ARM plus DSP. Now you have the Galaxy Note: ARM with GPU. I don’t think the programming paradigm has changed at all. But those transistors are not turned on all the time, so dark silicon is here.”
What is changing, Muller argued is the need for greater performance in a widening range of designs. “Performance drivers are applications such as computational photography, performing functions such as blemish reduction. One hundred gigaoperations per second at 1W are required for some of these functions. In vehicles you have ADAS [automated driver assistance systems]. Similar computations are required here, but around 40Gop/s at 1W. It’s lower performance but you need the ASIL [safety] compliance so the number of gigaoperations per second you have in the power budget is lower.
Exaflop architecture
“If you are going to build an exaflop supercomputer at 20MW, if you decompose the requirements and look at the numbers you end up with the same answer. 100Gop/s at 1W are what you want. For all these applications you get to the same performance points,” Muller added.
The problem is that the programming paradigm for current heterogeneous architectures involves multiple languages, some of which are very low level. For the Galaxy Note example, Muller said developers needed to use C++ together with OpenCL and Renderscript, “which is about as close to assembler you can get”.
For the processor designer, the massively parallel GPU has some advantages, Muller said. “There is no dynamic scheduling. You don’t have to worry about branching. You don’t do register renaming,” he explained, referring to one of the common techniques employed in superscalar general-purpose processors. “You can make really small cores with long pipelines and lower the clock frequency. You can use multithreading to tolerate long memory latencies and still get performance. When you stick it all together, what you are doing is reducing your control logic to ALU ratio, which gives you better operations per watt at the end of the day.”
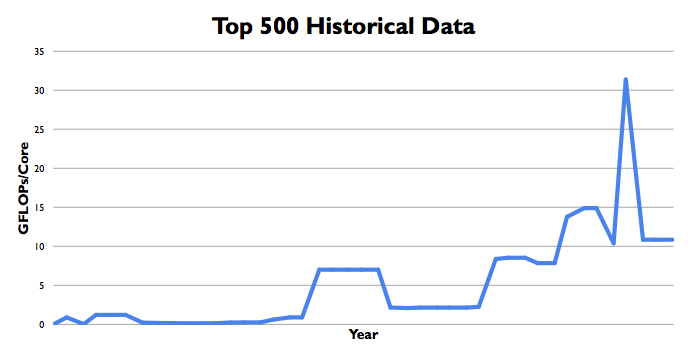
Image Mike Muller's slide showing the 'GPU spike' in Top 500 supercomputer entries
“Is it all good news? No,” Muller noted, pointing to a chart of the historical data for the Top 500 supercomputer list. It showed a clear spike in claimed performance for the few years in which GPUs inside the machine became suddenly fashionable – before the peak numbers declined to reflect a changing balance in supercomputer architecture.
The problem, Muller argued, is that many of today’s heterogeneous architectures suit programmers with a strong hardware background who understand the concepts behind the machines. Software programmers lack this background, leading ARM to look more closely at heterogeneous computers using a homogeneous architecture, citing the Big.Little pairing as a low-end example. “Can you be a little divergent and push this a little harder?” Muller asked.
Massively multithreaded
“Can you build a massively threaded machine that looks a bit like ARM? You can. You can provide a familiar ABI, instruction set, the same memory model,” Muller claimed, pointing to an architecture currently being researched at ARM. Intel has explored similar concepts in supercomputing with the Xeon Phi, which is built around a simplified form of the x86 architecture.
Using the SGEMM benchmark, Muller claimed comparatively small changes to code, such as the use of software prefetching and intrinsics libraries tuned for the machine could boost performance more than an order of magnitude despite the SIMT ARM clocking at half the frequency of a Cortex A15-class processor.
“It’s only useful for certain codes but with dark silicon you will have transistors lying around that you can use. With some more polishing maybe you can push it to more than 100 times faster,” Muller said, pointing to some work on the benchmarks that with “medium effort” got to a 125-fold performance boost. For comparison, a Mali running similarly optimized code reached 136x but Muller said this core consumes more die space than the experimental SIMT ARM.
“It’s strictly an implementation reality,” Muller said. “We looked at what we thought were the right sort of compute size and performance tradeoffs for that engine. The GPU is already bigger and so gets better results.”