Ultrawide neural engine fills a hole
One of the advantages of adding accelerators to multicore processors is that sometimes pad limits mean the area needed comes almost for free. When adding a neural-network unit to its latest x86-based processor, Centaur Technology’s designers found they could put much of it into otherwise unused die area.
Parviz Palangpour, who heads up the AI effort at Centaur, explained at the recent Linley Group Spring Conference how the relatively small engineering team approached the problem of inserting a custom accelerator without making big changes to overall production costs for a chip designed for TSMC’s 16nm FFC process.
The main target for the multicore processor is in edge servers. “Customers wanted to provide high-end video analytics in edge servers: it’s costly to upgrade the cameras themselves and these companies were already deploying x86 servers at the edge. However, the x86 isn’t efficient at inference,” Palangpour explained. “We would be happy to support GPUs with our SoC however these companies didn’t want to add GPUs to their systems. So we thought, why not integrate a coprocessor to accelerate these workloads?”
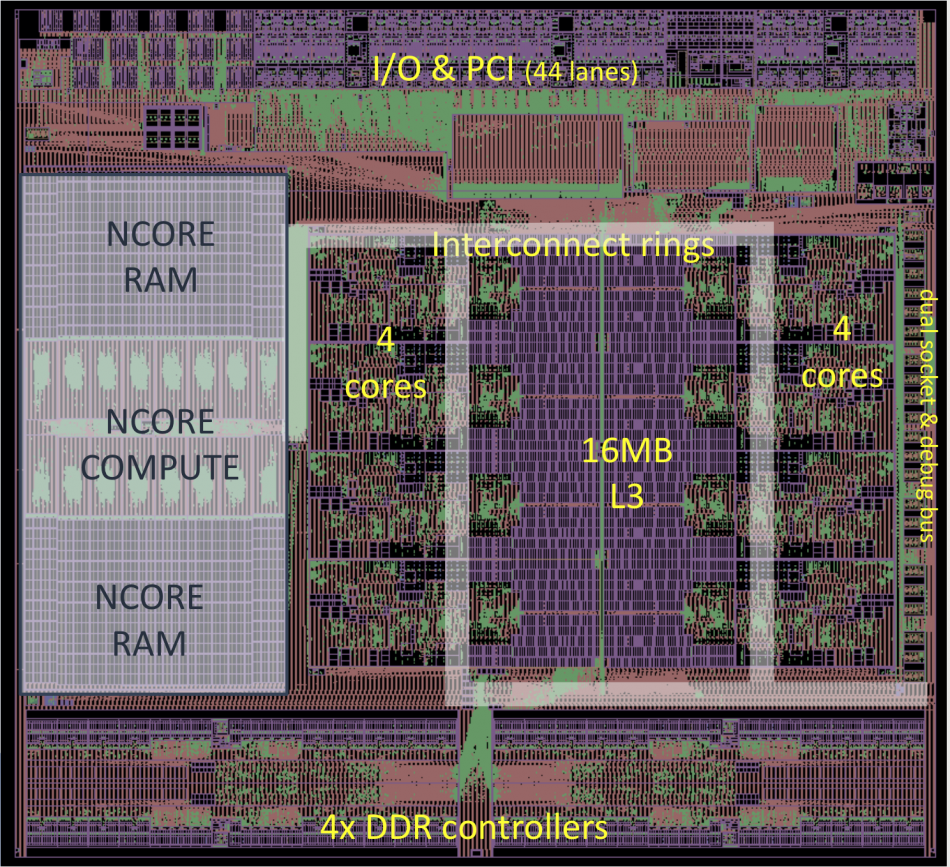
Image Centaur CHA die, showing the neural accelerator on the left side
Although pad and I/O constraints provided a sizeable area of silicon that could not be used for the x86 cores or the interface controllers, Palangpour noted: “The coprocessor had challenges. We had to live with the constraints of the rest of the chip. We had very little control over the size and aspect ratio of the hole available for it.”
Glenn Henry, cofounder of Centaur, said: “The hole started off small. But with the addition of four memory controllers and PCI, things got bigger. Overall, we maybe made the die a touch bigger.”
As well as not being able to control the shape and size of the coprocessor directly, a further constraint on the architecture of the core was that it should support models without retraining or the kinds of pruning that are common in building accelerators for embedded inferencing. And it had to be implementable by a small team. Henry opted to write most of the RTL himself.
To get data in and out of the coprocessor, the designers attached it to the same dual 512bit ring as that used to interconnect the eight x86 cores. From a software perspective, the coprocessor looks like a standard PCI device with registers that can be read and written directly.
SIMD rather than systolic
Rather than the systolic-array structure that many neural-network accelerators have employed, the Centaur team opted for an extremely wide SIMD. “These are generally much more programmable,” Palangpour claimed. “We wanted the flexibility to run new workloads.”
The result is a SIMD unit that is 64 times wider than that found in the AVX512 units sitting inside each of the onchip x86 cores. GH: “The x86 cores have about the same performance as a Haswell, except for some applications which take advantage of AVX512, which the Haswell doesn’t have.”
The SIMD unit, which could be classed as AVX32768, runs at the core frequency of 2.5GHz and has access to 2048 of local RAM, for a total of 16Mbyte. “That’s in addition to all the L3 cache memory,” Palangpour adds. “One instruction controls the entire pipeline. It’s very low level, like microcode: all instructions execute in one clock. The instructions won’t be made public because they likely won’t live for longer than each hardware generation.”
Instead, software libraries provide access to typical neural-network functions, mapping the code onto a group of dataflow pipes organised as 8bit or 16bit integer operations. The microcode library also provides support for the Bfloat16 format, with three clocks for a multiply-accumulate on that data type. A data unit in each pipe handles a number of movement operations that are commonly needed in deep learning, such as row rotations and edge swaps.
“The SIMD approach works really well,” Palangpour claimed. “We had a lot of doubters but it works really well.”