Energy-efficient implementation of machine-learning algorithms for IoT
Synopsys has published a white paper that explores the energy-efficient implementation of machine-learning (ML) strategies on embedded processors in IoT applications. The paper starts with the basics of ML and progresses through the common characteristics of various popular algorithms, the kinds of computation they need, how that computation can be efficiently implemented in optimised processor architectures, and how software libraries can help ensure that the hardware is used most effectively. The paper ends with a worked example of implementing a popular image recognition task and benchmarks about the effectiveness of the approach.
The white paper, authored by Pieter van der Wolf, principal R&D engineer, and Dmitry Zakharov, senior software engineer, both at Synopsys, opens with a general overview of machine learning in the context of IoT. Early applications of the technique already include voice control in smart speakers, distinguishing different types of human activity in fitness trackers, face detection in security cameras, and some aspects of advanced driver assistance systems in cars.
To give readers a sense of the basic computational challenge of machine learning, the white paper goes on to explain the difference between training and inference, and compares the volumes of input data involved in some of the basic applications outlined above.
The paper then explains some of the basic algorithms of machine learning, and the importance of efficient dot product calculations, in which an array of input data, perhaps representing an image, is multiplied by a separate array of weighting data, to create a single value in an output array.
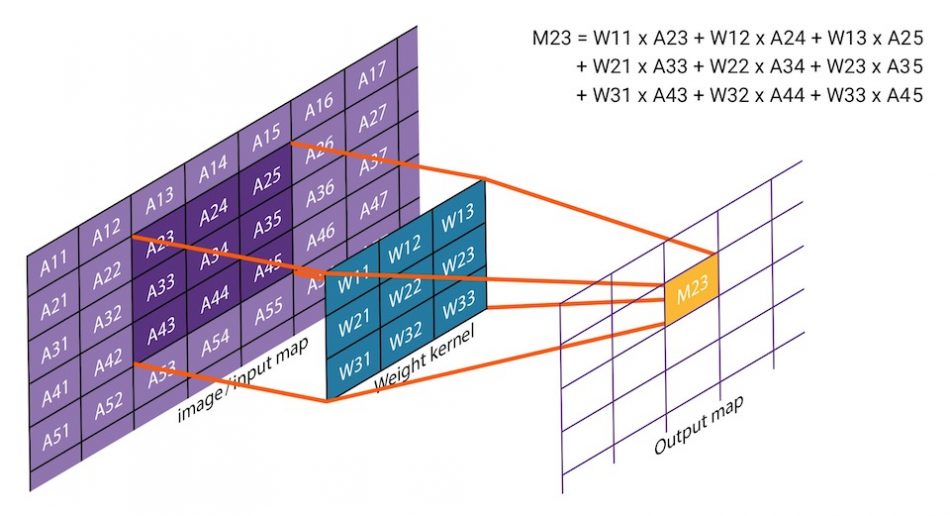
Figure 1 2D convolution applies weightings to input data to calculate an output value (Source: Synopsys)
There follows a discussion of the architecture of various machine-learning algorithms. This includes a discussion of the computational implications of various common aspects of these architectures, such as pooling layers that downsample input data to reduce the complexity of further calculations.
The paper moves on to discuss the impact of different forms of number representation in machine learning algorithms. A widely used approach to date has been to represent input values and weighting factors as 32bit floating-point data during network training, to capture as much detail as possible, and then to shift to lower resolution (16bit) fixed point representations during inferencing, to reduce the amount of computing needed in embedded applications. Work is also going on to explore the impact of using even lower-resolution number representations on the quality of the resultant inferencing, and on varying the levels of precision used in different neural network layers.
It’s at this point that the white paper starts to link the abstract requirements of machine-learning algorithms with the impact this has on real-world implementations, especially in power-aware IoT devices. There then follows an exploration of the way in which features of the Synopsys 32bit DSP-enhanced ARC EM9D processor core IP can be used to efficiently implement machine learning algorithms. Features such as dedicated address generation units, which can be set up with an address pointerto data in memory and a modifier to update the pointer in a particular way when data is accessed through it allow operands to be accessed from memory and results stored back into memory without explicit load or store instructions.
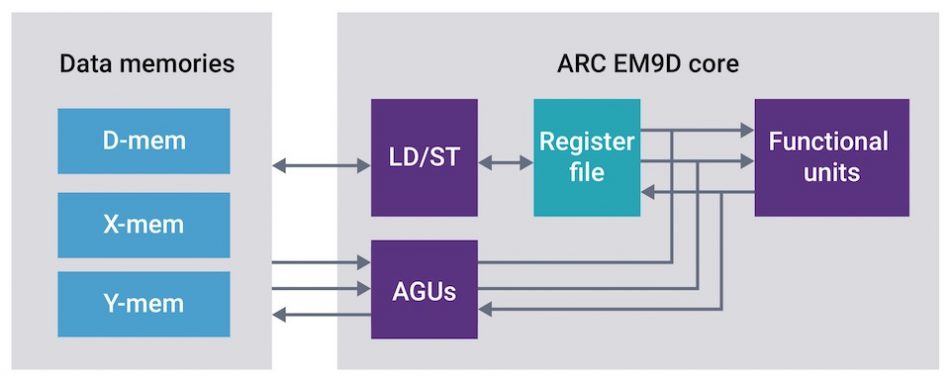
Figure 2 ARC EM9D processor with XY memory and address generation units (Source: Synopsys)
ARC EM9D processor with XY memory and address generation units
The ARC EM9D processor has other DSP capabilities that enable efficient implementation of other functions, such as pre-processing and feature extraction, including:
- Zero-overhead loops
- Fixed-point arithmetic with saturation and rounding
- Wide accumulators with guard bits
- 2×16 and 4×8 vector support
- 16+16 complex arithmetic & butterfly support
- Circular and bit-reversed addressing
Having discussed the relationships between the computational needs of machine-learning algorithms and how these can be reflected for greatest efficiency in processor architectures, the white paper then explores how programmers can be helped to use these facilities through the availability of optimised software libraries.
For example, the recently introduced embARC Machine Learning Inference software library is a set of C functions and associated data structures for building neural networks. Library functions implement the processing associated with a complete layer in a neural network, so that a complete neural network graph can be implemented as a series of MLI function calls.
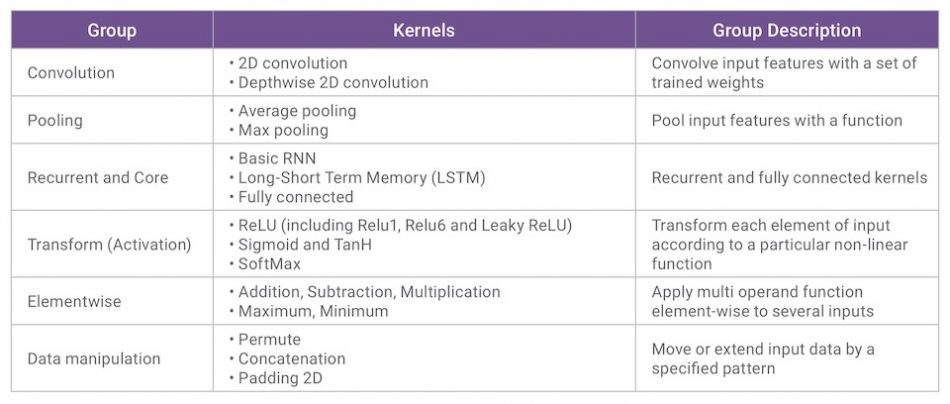
Table 1 Key elements of the embARC MLI library (Source: Synopsys)
The white paper goes on to discuss how these functions can be configured and invoked, and how they can be used to take advantage of processor features such as the dedicated address generation units. Code samples are provided.
The white paper wraps up by exploring how the combination of machine-learning frameworks, dedicated hardware and supporting software libraries can be brought together to serve some real-world applications. One of these is the CIFAR-120 objection recognition task, which I snow widely used as a benchmark.
The CIFAR-10 dataset holds 60,000 low-resolution RGB images (32×32 pixels) of objects in 10 classes, such as ‘cat’, ‘dog’ and ‘ship’, and is widely used as a ‘Hello World’ example in machine learning and computer vision. The objective is to train the classifier using 50,000 of these images, so that the other 10,000 images of the dataset can be classified with high accuracy. We used the CIFAR-10 CNN graph shown below for training and inference.

Figure 3 CNN graph of the CIFAR-10 example application (Source: Synopsys)
The CIFAR-10 example application can be built for all supported embARC MLI library data representations: 8bit for both feature data and weights, 16bit for both feature data and weights, and a combination of 16bit for feature data and 8bit for weights. The white paper shows some of the assembly code used in the implementation, as well as a set of benchmarks that relate each layer to the amount of computation it demands, the number of coefficients used and the number of processor cycles it took to execute.
The white paper is available here.