Floorplanning complex SoCs with multiple levels of physical hierarchy
How to work with multiple levels of physical hierarchy when floorplanning multicore, multiport, multi-million gate SoCs
The complexity of modern multicore, multiport, multimillion-gate SoCs demands that their planning, design and implementation is handled hierarchically. Designs are broken down into sub-designs, which in turn may also be sub-divided, to create multiple levels of physical hierarchy (see Figure 1). This makes it easier to manage the work, and can also help reduce the risk that an issue in one area of a design will adversely impact another.
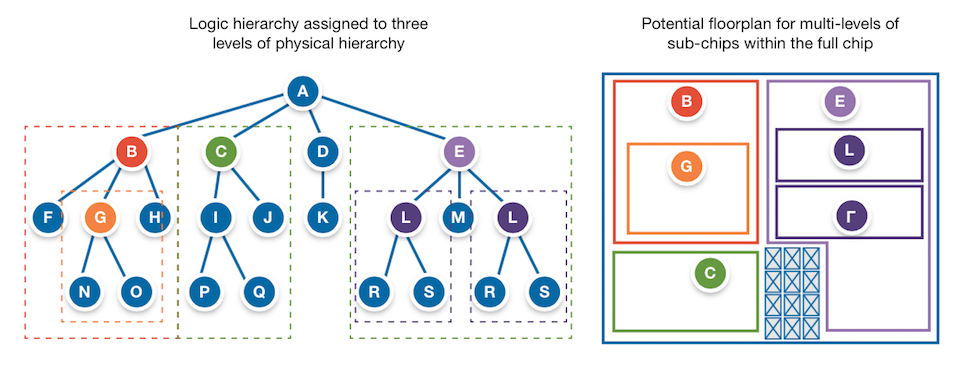
Figure 1 Using multiple levels of hierarchy to ease physical implementation (Source: Synopsys)
The limits of a two-level physical hierarchy
Physical planning place and route tools that only handle two levels of physical hierarchy – top and block – force designers to apply a recursive, two-level-at-a-time implementation approach that complicates both the flow and the related design data management.
Teams must set block shapes, block pin placements, and budgets for block timing constraints one level at a time. The shapes, pin placements, and budgets set at one level become hard constraints for the next level down the design’s hierarchy. Changes to lower-level blocks that impact parent levels, such as increasing a sub-chip size, can ripple back to the top level. Sub-teams working on the design have to negotiate among themselves how to deal with such changes with the least effort and impact to the rest of the design.
Design teams also face data management tasks. For example, to manage complexity and minimize memory use, teams will convert the child blocks of one level into black boxes, even if they have the netlist data. Area requirements are estimated. Any constraints on block shapes or sizes needed to accommodate hard macros have to be dealt with manually. Teams must create black-box models to represent blocks that are still progress, and then replace them with real netlist data once those blocks have been elaborated and synthesized.
Designers working at the child level can easily create issues for others. Consider two designers, working on separate sub-chips connected through logic at a parent level. Each designer may move content within their sub-chip to improve its routability and timing, without realizing the timing issue this creates in the full-chip context (see Figure 2.)
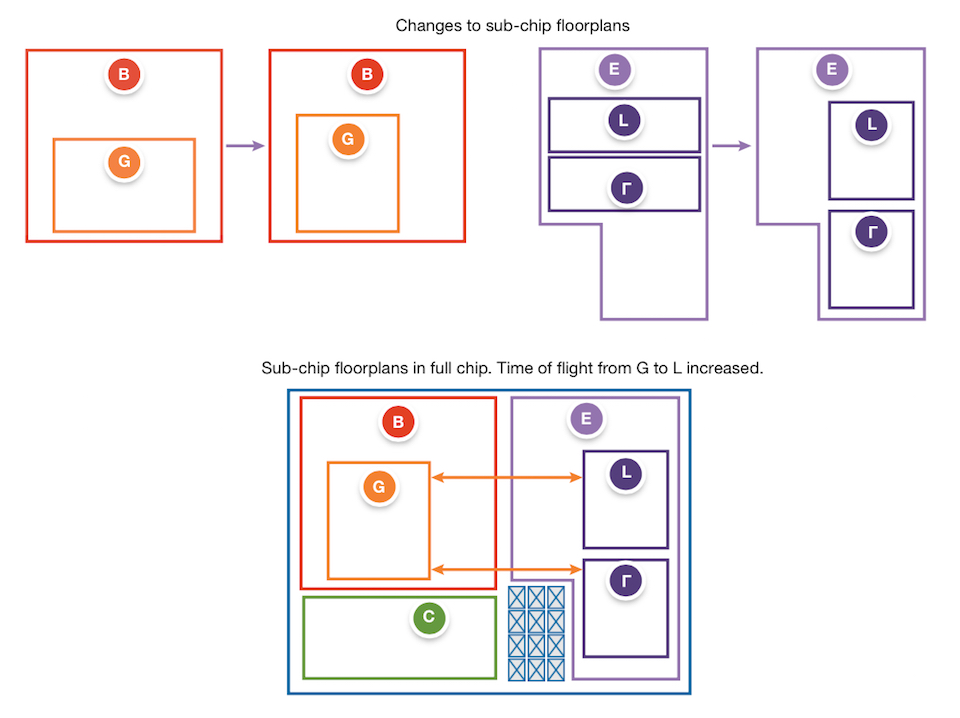
Figure 2 How sub-chip changes can make top-level closure more difficult (Source: Synopsys)
Multiply-instantiated blocks (MIBs), which are used in multiple contexts on the same chip, also create issues. The fact that these blocks’ designs are fixed means that using them in sub-chips introduces a set of shape, size, pin placement, and timing constraints. Making a change to an MIB because it doesn’t work in a particular sub-block usually demands a lot of negotiation with the block’s owner – and may impact other sub-blocks using the MIB.
Moving to multiple levels of physical hierarchy
A better way of dealing with complex designs is to plan at multiple levels of hierarchy concurrently, with strong feedback about the impact of each choice on the full-chip context. To achieve this, a tool should shape sub-chips, place macros and standard cells, route power, place pins, and generate timing budgets at all levels – automatically. This needs to happen quickly enough that complex designs can be planned overnight.
The planning flow should use netlist data where possible, to improve decisions about issues such as area requirements, macro content, and interfaces, while accommodating black boxes as necessary. It should support various design styles, including channelled or abutted approaches, multiple voltage areas, and designs containing MIBs. Teams should be able to define requirements, such as target utilizations of sub-chips and voltage areas, or let the tool determine these based on the required die size. And the tool should automatically create feedthrough routes for abutted designs, with manual control of how specific nets and busses are implemented.
The broad application of MIBs within a design means they need special handling. Tools need to consider the context of each instance, and work out which version of the MIB will work best for all of them, considering their shapes, pin placements, and timing budgets.
Creating feedthroughs for MIBs being used in abutted designs is another challenge. It’s unlikely that the same nets will cross all instances of a MIB, let alone in the same place (see Figure 3). One way to address this is to create generic feedthroughs that cross an MIB, and then assign different nets to each feedthrough as required in each instance. Unused feedthroughs must be tied off to power or ground, depending on the MIB’s context.
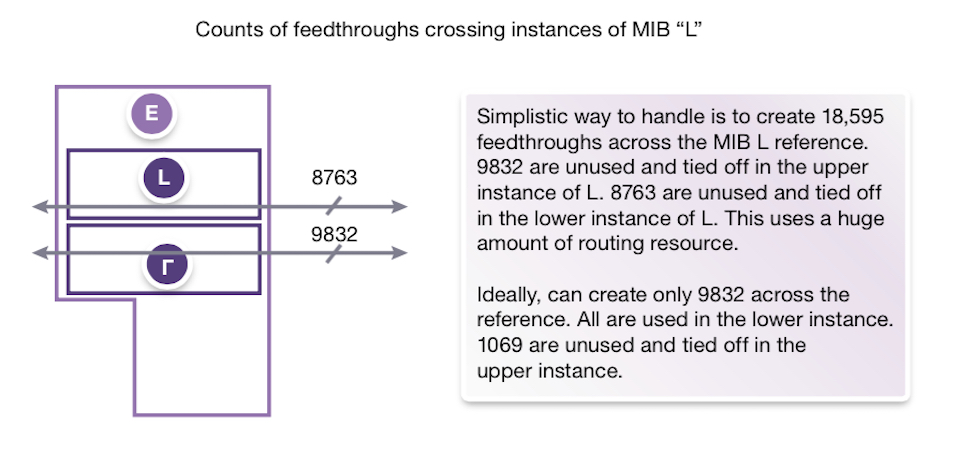
Figure 3 Nets can be assigned to generic feedthroughs in a MIB, depending on how it is being used (Source: Synopsys)
Most importantly, teams need to be able to explore a design at any level of its physical hierarchy and see what impact their changes have at the full-chip level. This eases the design process, improves consistency, reduces the time it takes to negotiate changes that impact multiple blocks, and should improve the quality of the floorplan.
The IC Compiler II approach
Synopsys’ IC Compiler II uses a data model that recognizes physical hierarchy as part of its native structure. This means that all the ‘engines’ handling issues such as shaping, placement, routing, and timing can easily access the data they need to do their work within the constraints of the physical hierarchy.
Making shapes
Consider shaping. In Figure 4, the shaper needs to know the target area for each sub-chip, any aspect-ratio constraints dictated by hard-macro children, and any interconnects at sibling-sibling, parent-child, and child-parent interfaces. If the design is a multi-voltage design, the shaper also needs to be constrained with target areas for any voltage islands.
Shaping constraints set for the lower-level sub-chips translate up the hierarchy into shaping constraints on parent sub-chips. The shaper does not need to know about the full netlist within each sub-chip or block. For multi-voltage designs, IC Compiler II reads UPF and stores appropriate data within sub-chip levels. The engines will also draw data from the database to calculate targets based on natural design utilization, or user targets.
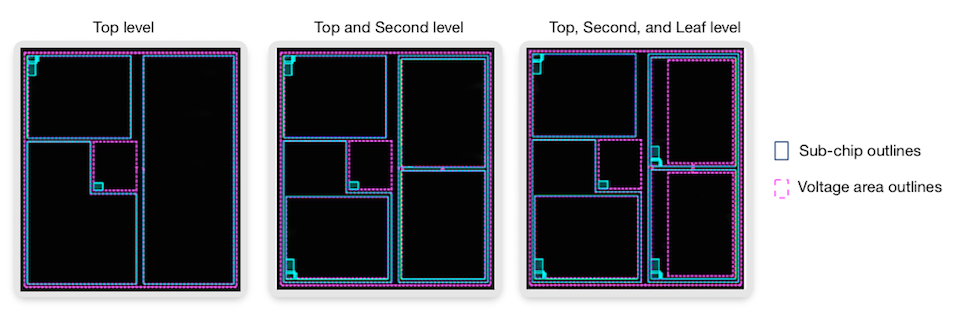
Figure 4 IC Compiler II multi-level shaping results (Source: Synopsys)
The new data model also supports distributed processing, so IC Compiler II engines can split their work across multiple computer processes.
Placing
After shaping, the placement engine sees a global view of dataflow interconnect paths at physical hierarchy boundaries, as well as any connectivity to macro cells. It uses this information to place macros for each sub-chip at each level. Understanding where interconnect paths need to be at boundaries ensures there are resources at the adjacent sub-chip edges to accommodate them. The placer also anticipates the needs of hierarchical pin placement, and places macros so that interconnect paths don’t need much buffering to drive signals across them.
Using sub-chip shapes, locations, and the global macro placements, the placer engine models the context seen at the boundaries of child and parent sub-chips. The placer then uses this model to create cell-placement jobs for each sub-chip at each level of hierarchy. Each job creates placement for the standard cells in each sub-chip. Splitting this into multiple processes for the sub-chips saves time and maximizes the use of compute resources.
Power routing
IC Compiler II uses an object-based methodology for power routing. Patterns describing construction rules – such as widths, layers, and the pitches necessary to form rings and meshes – are applied to floorplan objects such as voltage areas and groups of macros. The tool associates a pattern or multiple patterns with each area, according to strategies defined for the full chip. IC Compiler II characterizes the power plan and generates strategies for sub-chips at all levels, so a complete power plan can be produced using distributed processes. Because the characterized strategies are defined in terms of objects at each sub-chip level, power plans can easily be re-created to accommodate floorplan changes at any level.
Placing pins
With shapes formed, macros placed, and power routed, IC Compiler II’s pin-placement engine accesses interface data for all levels of the design and applies a dedicated global router to decide where to place hierarchical pins. The router recognizes physical boundaries at all levels, to ensure the efficient use of resources at hierarchical pin interfaces. Pins are aligned across multiple levels where possible. The router understands MIBs and so will intersect the edges of all MIB instances identically. The pin-placement algorithm will also work out the best (and identical) pin placement for all instances of the MIB. The pin placer creates feedthroughs for all sub-chips, including MIBs, throughout the hierarchy (see Figure 5). The global router plans feedthroughs across MIBs, determines the re-use of feedthroughs and ties off unused feedthroughs.
Figure 5 The results of pin assignment and feedthrough creation steps in IC Compiler II (Source: Synopsys)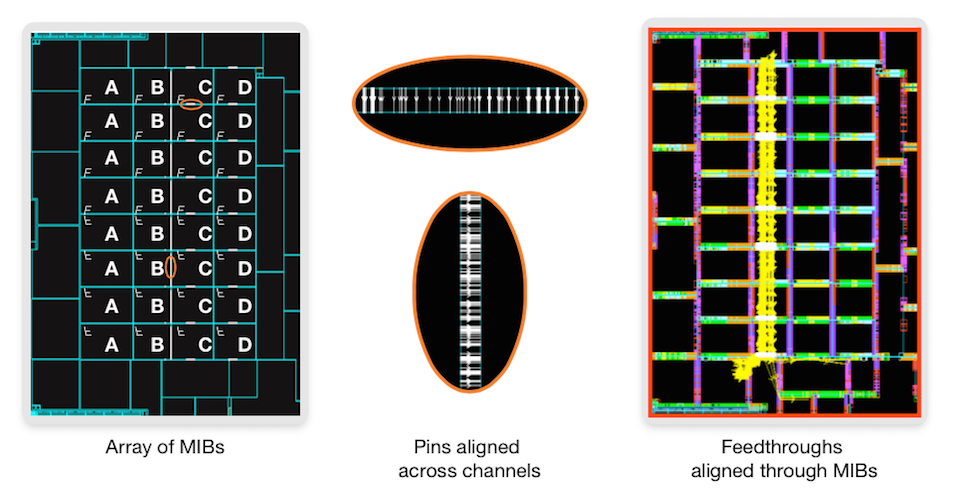
Once hierarchical pins are placed, IC Compiler II estimates the best timing at hierarchical interfaces and creates timing budgets for sub-chips.
Most budgeters create timing constraints for the main hierarchical input and output pins of sub-chips. The input and output delays of the budgeted constraints represent timing-path segments within the parent to each sub-chip. This enables sub-chip designers to place and optimize ‘flat’ sub-chips by modelling the external timing environment seen at their main input and output pins. However, there are no constraints to represent the timing path segments that exist in the child sub-chips, as seen from their parents.
IC Compiler II’s budgeter creates timing constraints for all child interface pins in the full chip, the parent and child interfaces for mid-level sub-chips, and the primary pins of the lowest-level sub-chips. The entire design can then proceed with placement and optimization as a concurrent set of distributed processes.
As the design matures and sub-chips are finalized, teams can specify which must not be physically modified. This helps when design teams have to update their netlist data and are told, for example, that one sub-chip will have to grow in size. IC Compiler II can update the floorplan considering both the full-chip context and which sub-chips cannot be modified.
The tool also offers interactive viewing, analysis and editing of any level of the design in a full-chip context. This can be useful, for example, for hand-routing a timing-critical signal that passes through multiple levels of the hierarchy. Interactive routing is performed as if the design is flat, and when the editing is complete the routes are pushed down into the child sub-chips and hierarchical pins are automatically added (see Figure 6).
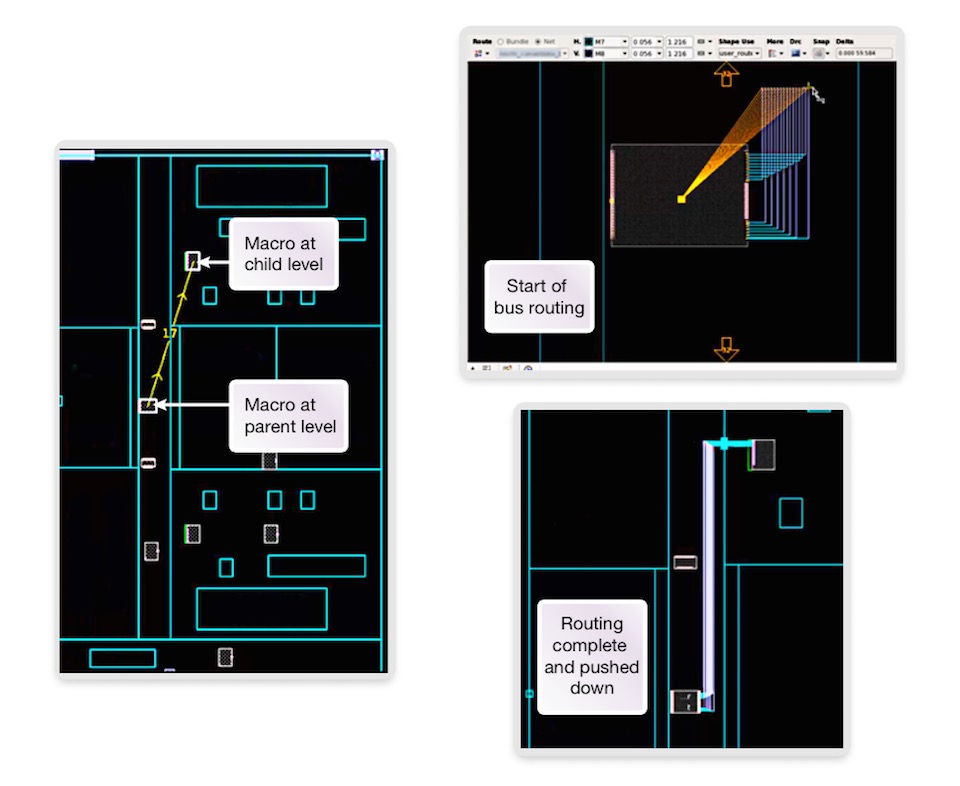
Figure 6 Interactive multi-level route editing (Source: Synopsys)
Author
Steve Kister is a technical marketing manager supporting place and route design planning tools in Synopsys’ Design Group. Kister has been in the ASIC design and EDA industry for 35 years, having spent the past 20 years at Synopsys. He received a BSEET from the DeVry Institute of Technology, Phoenix, AZ.
