ARM aims for top-end phones with core pairing
ARM has combined a new high-end 64bit Cortex-A core with a reworked Mali graphics processor to support high-throughput applications such as virtual reality and machine learning on smartphones that are expected to start shipping in 2017.
The company launched the A73 and the Bifrost GPU architecture, of which the Mali-G71 will be the first implementation, at Computex this week (30 May). Although the GPU shares the name of a software API for nVidia’s own accelerators and an Autodesk rendering software package, the Bifrost name is simply a continuation of the Norse naming convention, leading on from Midgard, ARM adopted several years ago.
However, ARM’s Bifrost appears to share one conceptual similarity with nVidia’s task-chaining API. The ARM GPU has added what the company calls “claused shaders”, which allow a group of instructions to the execution units to be chained together more efficiently.
Jakub Lamik, vice president of product marketing at ARM, said: “It’s a technology where we combine instructions in groups that can execute in parallel. Using this we can optimize the way registers are used and pay less overhead for each instruction.”
Scheduling decisions are made at the boundaries between clauses. This potentially leads to greater opportunities for parallelism, the company claims, and the structure allows clauses to execute if all instructions are able to run and do not have to wait for resources or the outcome of a branch decision.
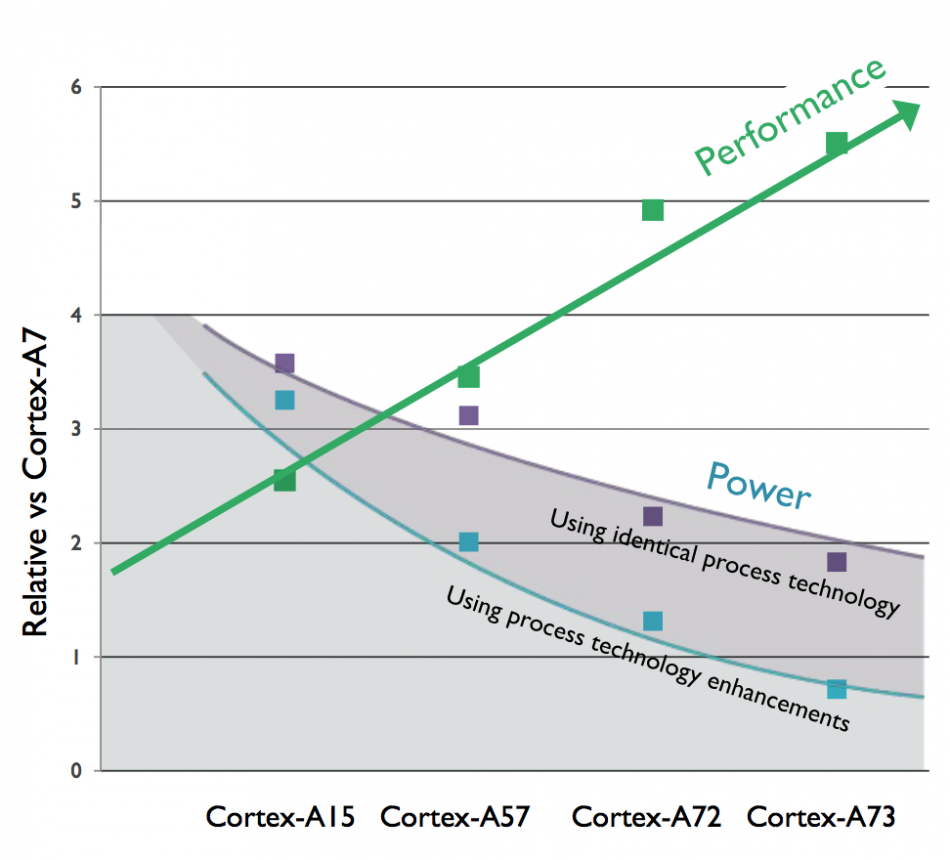
Image Claimed performance and power improvements for the four most recent high-end Cortex-A processors
Easier implementation
Lamik claimed the design team has worked on the interconnect between the shader cores to reduce the wiring complexity for large core counts, which should make the core easier to implement on leading-edge processes such as the 10nm finFET process that is the prime target for the core pairing. Wiring density has proved to be a problem on the most recent processes because it is harder to scale the back-end metallization without increasing parasitics.
“We’ve simplified the way that wires connect to each shader core and changed the way that the registers are organized and how the shader cores interconnect with the level-two cache,” Lamik said.
The register files for the shader cores have moved closer to the execution units and the shader cores used a redesigned messaging fabric that is less wiring intensive, the company claims.
A further change is the adoption of a deferred-rendering technique the company calls index-driven vertex shading, which Lamik says employs a form of deferred rendering to reduce memory bandwidth demands. The technique delays shading objects until unseen parts of them have been culled.
James Bruce, lead mobile strategist for ARM, claimed the A73 employs a different architecture to its A72 predecessor and is more efficient in terms of silicon area and performance on the same process. “There are significant differences to the A72,” he said.
Area reduction
The company has quoted an area of 0.65mm2 for the A73 assuming implementation on a 10nm finFET process. However, because of the reductions in transistor count, Bruce said: “It will be backfilled all the way back to 28nm. Let’s say you are doing a product like a digital still camera, where the volumes aren’t as high as in mobile phones. The A73 makes much more sense now because it’s more area efficient.”
The A72 has a shorter pipeline than the earlier A73 – 11 core stages versus 15 – and is a two-way superscalar rather than three-way but the company claims better overall performance per watt.
Because the A73 is aimed squarely at the mobile-phone segment, the company decided to not put error-checking into the caches, leaving the A72 as the current high-end processor for servers. “The A72 is still very appropriate for markets where you need that reliability.”
For Big.Little combinations, the company expects the A73 to be paired with the A53 although the A35 provides another option for lower silicon area, Bruce said.
The A73 and the GPU are expected to communicate using the CCI550 cache-coherent interconnect. To support machine learning and other high-performance compute algorithms running locally, the company expects applications to be spread across the CPU and GPU “and also using other types of accelerator,” Lamik said. “The mobile device is becoming the key compute platform.”
To support the company’s ambitions in vision applications for augmented reality that are supported by machine learning, ARM acquired Loughborough, UK-based Apical, a designer of image-processing cores, for approximately $350m in cash earlier this month.