Memory focus for specialized 32bit MCU
For a new 32bit microcontroller family, FTDI Chip has decided to not follow the crowd into the ARM camp but go it alone with its own proprietary architecture that the company believes is better for I/O-intensive display and bridging applications by adding support for large memory moves into the core instruction set.
Dave Sroka, product director at FTDI describes the FT900 as a “true zero wait state” architecture. Typically, 32bit processors are somewhat faster than the memory that serves them so that, unless a data fetch can be served by a cache – if the budget allows for a cache in the first place – the processor’s pipeline has to stall while it hangs around. However, the no-wait-state approach goes further than simply loading variables into the processor’s registers. As video and graphics tend to rely on large movements of 2D arrays, the FT900 was designed around streamlining these operations.
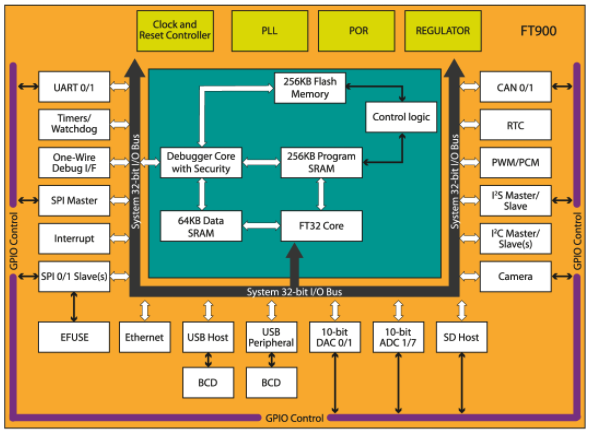
Image The FTDI FT900 is designed to bridge a number of I/O standards
FTDI product development manager Lee Chee Ee says: “We have implemented a structure called streaming. In conventional instruction set, if you want to move data from area to area, you need to perform multiple moves or set up a DMA [direct memory access] a couple of instructions before you execute the transfer.”
In contrast to most RISC architectures that devolve memory transfers to the DMA controller, the FT900 brings that into the core instruction pipeline. “On the FT900, if want a similar transfer I issue just one instruction. For the processor it takes one instruction cycle and removes a lot of overhead,” Lee claims.
“On the FT900 architecture we focused a lot on the peripherals,” says Lee, which include network peripherals such as Ethernet or USB . “Most of those functions operate using the streaming instruction. Although conventional processors claim very high throughputs, when they execute an access to a peripheral, they get wait states. Here both peripherals and memory achieve zero wait states.”
To balance out the speed of the different peripherals’ interfaces, each one has its own area of dedicated memory to support fast transfers, so that the streaming performs mainly memory-to-memory moves at high speed.