High-resolution visual recognition needs high-performance CNNs
 Gordon Cooper is a product marketing manager for Synopsys’ embedded vision processor family. Cooper has more than 20 years of experience in digital design, field applications and marketing at Raytheon, Analog Devices, and NXP.
Gordon Cooper is a product marketing manager for Synopsys’ embedded vision processor family. Cooper has more than 20 years of experience in digital design, field applications and marketing at Raytheon, Analog Devices, and NXP. Every month seems to bring new papers and techniques that can be applied to deep learning for embedded vision systems. When it comes to the application of machine learning to embedded imaging tasks, it’s understandable if many companies are still feeling their way. Technology in this area is moving fast. Algorithms that were widely regarded as world-beating one year are set aside the next when a new algorithm emerges. The ImageNet Large Scale Visual Recognition Challenge, an annual competition for best-in-class object category classification and detection benchmarks, provides a great example of this. AlexNet, the breakthrough winner in 2012, achieved a large improvement in performance over more conventional techniques. AlexNet was overtaken in 2014 by an algorithm called GoogLeNet, which was overtaken by ResNet the following year. All of these were based on convolutional neural network (CNN) techniques.
Despite the dog-eat-dog world of deep-learning algorithm development, CNNs have become the standard way for machines to extract various forms of information out of an image. Neural networks are loosely based on the human brain, and so are organized conceptually as a set of layers of artificial neurons, each of which undertakes a series of operations and communicates its results to adjacent layers. There are various forms of layers, including input layers, which take in the image data, output layers which deliver the specified results (such as recognition of objects in an image), and one or more hidden layers between the input and output which help refine the network’s answers. Having hidden layers defines the network as “deep.”
For a CNN, layers are set up to perform different tasks, such as the convolution of an image with a filter, normalization to scale elements of the image for better recognition, pooling layers that effectively simplify the image, or fully connected layers in which each node in the network is connected to every node in the previous layer.
Exploring the best way to structure a CNN to achieve a particular imaging result is a complex task, since there are many variables to consider such as the number of layers, what each one does, how they are connected, and so on. Running CNNs can also take large amounts of computing power, so there’s a balance to be struck between implementing the absolutely most effective CNN and implementing the CNN that offers the best tradeoff between computational needs (and related energy consumption), and performance.
Many companies want to take advantage of the newest CNN algorithms and so need flexible hardware whose computational power can be scaled to deliver the right balance of cost, energy consumption and imaging performance. Synopsys started down the road to satisfying this need in 2015 with our first generation CNN engine. Last year, we introduced the EV6x embedded vision processor IP cores, which included a second-generation CNN engine to handle convolution and classification tasks.
Designers have begun building bigger CNN ‘graphs’ (the combinations of layers and interconnects that make up the network) than previously expected, in part because they want to work at higher image resolutions. In advanced driver assistance systems, for example, moving to higher resolutions (e.g., 8Mpixel and 60frame/s) effectively allows the system to “see” further ahead than lower resolutions would make possible, improving their ability to help drivers drive more safely.
This year Synopsys is enabling the use of these graphs by quadrupling the amount of CNN computing power that designers can specify in their embedded vision implementations. In practice, this means that an engine that could deliver up to 880 multiply-accumulate (MAC) operations per cycle last year can now deliver up to 3520 MAC per cycle. In a 16nm finFET process, the most fully specified CNN engine can deliver up to 4.5 TeraMAC per second. This third-generation CNN engine is also highly optimized for area and power consumption.
The DesignWare EV6x processor family also integrates up to four vision CPU cores, each of which has a 32bit scalar processor and a 512bit vector DSP. It supports both coefficient and feature-map compression/decompression to reduce data bandwidth requirements and decrease power consumption.
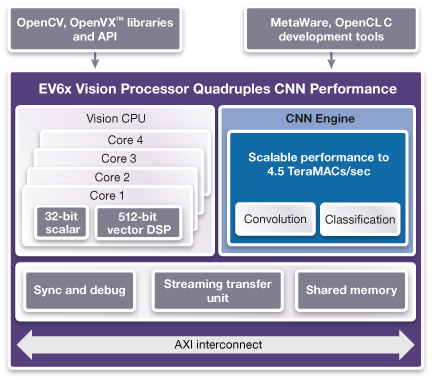
Figure 1 The updated EV6x architecture (Source: Synopsys)
To make it easier to explore different approaches to image processing, the EV6x dedicated and programmable CNN engine supports all CNN graphs, including popular networks such as AlexNet, VGG16, GoogLeNet, Yolo, Faster R-CNN, SqueezeNet and ResNet.
The EV6x processors are supported by a comprehensive set of tools and software based on the OpenVX, OpenCV and OpenCL C embedded vision standards. These include the DesignWare ARC MetaWare EV Development Toolkit, which includes a CNN mapping tool that analyzes neural networks trained using popular frameworks such as Caffe and Tensorflow, and automatically generates the executable for the programmable CNN engine. The CNN mapping tool automatically converts the 32bit floating-point graphs output by Caffe or TensorFlow into an 8bit or 12bit fixed-point format that is compatible with hardware on the EV6x’s CNN engine, saving area and power while maintaining the same levels of detection accuracy. The tool can also distribute computations between the vision CPU and CNN resources to support new and emerging neural network algorithms as well as customer-specific CNN layers.
The philosophy of the design is to try and keep as much of the CNN processing within the CNN engine. However, if users want to develop their own custom layers with complex internal computations, the code for these can be run in the vision CPUs.
Further information
The MetaWare EV Development Toolkit is available now. The DesignWare EV61, EV62 and EV64 processors with the updated CNN engine will be available in August. Support for the TensorFlow framework in the Toolkit’s CNN mapping tool is due in October.
DesignWare EV6x processor family
Author
Gordon Cooper is a product marketing manager for Synopsys’ embedded vision processor family. Cooper has more than 20 years of experience in digital design, field applications and marketing at Raytheon, Analog Devices, and NXP. Cooper also served as a Commanding Officer in the US Army Reserve, including a tour in Kosovo. Gordon holds a Bachelor of Science degree in electrical engineering from Clarkson University.
Company info
Synopsys Corporate Headquarters 690 East Middlefield Road Mountain View, CA 94043 (650) 584-5000 (800) 541-7737 www.synopsys.com
