Optimizing power and performance trade-offs in CNN implementations for embedded vision
 Gordon Cooper is a product marketing manager for Synopsys’ embedded vision processor family. Cooper has more than 20 years of experience in digital design, field applications and marketing at Raytheon, Analog Devices, and NXP.
Gordon Cooper is a product marketing manager for Synopsys’ embedded vision processor family. Cooper has more than 20 years of experience in digital design, field applications and marketing at Raytheon, Analog Devices, and NXP. High-performance, low-power embedded vision processors are used in many applications: face recognition in mobile phones; identifying hands and room layouts to enable augmented or mixed-reality headsets to incorporate them into game-play; and in self-driving cars to see and interpret the road ahead.
These applications demand the use of deep-learning algorithms, such as convolutional neural networks (CNNs), which demand a lot of processing power yet need to operate at the lowest possible power consumption. As in many other areas of computing, such as digital signal processing, achieving the best trade-off between power and performance demands the use of dedicated CNN engines.
Figure 1 Object detection and classification algorithms, such as this TinyYOLO CNN graph, demand optimized processor architectures (Source: Synopsys)
Chip options for deep learning
The computational power of GPUs has provided the horsepower needed to explore different deep-learning algorithms and train the best candidate architectures on real-world tasks. However, these processors, originally built to handle graphics, have limited utility in power-sensitive embedded applications.
Vector DSPs – very large instruction word SIMD processors – were designed as general-purpose engines to execute conventionally programmed computer-vision algorithms. A vector DSP’s ability to perform simultaneous multiply-accumulate (MAC) operations allows it to run the two-dimensional convolutions needed to execute a CNN graph more efficiently than a GPU. Adding more MACs to a vector DSP will allow it to process more CNN calculations per cycle, enabling higher frame rates, but even greater power and area efficiency can be gained by adding dedicated CNN accelerators.
The best of both worlds can be achieved by using a vector DSP for pre- and post-processing of video images, and then closely coupling it to a dedicated CNN engine, designed to support all common CNN operations such as convolutions and pooling, at minimum die area and power consumption.
Such a dedicated CNN engine, optimized for memory and register reuse, is as important as increasing the number of MAC operations that the CNN engine can perform each second. If the processor doesn’t have the bandwidth and memory architecture to feed those MACs, the system cannot achieve optimal performance.
Even lower power can be achieved with a hardwired ASIC design, which may become desirable when the industry agrees on embedded vision processing standards, as happened when the video industry settled on the H.264 compression standard. At the moment, though, CNN architectures are evolving so quickly that designers are better off building flexible solutions.
Measuring in-system power before silicon
For the most power-sensitive embedded vision applications, its important to be able to predict power consumption before silicon is available.
Consider an application with a tight power budget, such as a battery-powered IoT smart home or mobile device running a facial-recognition algorithm that may require several hundred GMAC/s of processing power. The power budget for all this computation may be limited to several hundred mW.
Comparing different vision processor IP blocks is complex. Bleeding-edge IP solutions often haven’t reached silicon yet, and every implementation is different, making it difficult to compare their power and performance. There aren’t any standard benchmarks for comparing CNN solutions, and although an FPGA prototyping platform might provide accurate performance benchmarks it won’t provide accurate power estimates.
One way to calculate power consumption is to run an RTL or netlist-based simulation to capture how all the design’s logic is toggled. This information, using the layout of the design, can provide a good power estimate, and for smaller designs, the simulation may complete in hours. However, a simulation of a high frame-rate CNN graph could take weeks to reach a steady state in which to measure power. There is a risk that when IP vendors skip such detailed power analysis in favour of using estimates based on smaller simulation models, the resultant power problem will be pushed downstream to the SoC vendors to sign-off on the IP vendor’s power analysis claim.
Synopsys’ ZeBu Server can help both IP developers and SoC designers by supporting advanced use modes including power-management verification, comprehensive debug and Verdi integration, hybrid emulation with virtual prototypes, and architectural exploration and optimization. ZeBu has additional facilities to compute power accurately for hundreds of millions of clock cycles, in hours instead of months. Access to a ZeBu emulator therefore makes it easier to explore power/performance tradeoffs in running application software on various candidate hardware architectures.
Systemic optimizations for lower power
There are various other ways to cut systemic power, for example by moving to a denser processing node, lowering the operating frequency of the design, or applying near-threshold logic techniques to greatly reduce the energy needed to switch a transistor. Another approach is to minimize the amount of external bus bandwidth the design needs, by increasing the amount of on-chip memory. Designers can also minimize bandwidth requirements by applying compression techniques to the key parameters of their CNN graphs.
Reducing energy use is obviously important for battery-powered applications, but even designs for autonomous vehicles need to take care of power consumption. An autonomous vehicle, running multiple 8Mpixel cameras at 60frame/s, could require 20 to 30 TMAC/s of computational power – within the lowest possible power budget.
In this context, designers need access to an optimized CNN engine whose performance can scale up. In Synopsys’ EV6x family, this is done in two ways: by scaling the number of MACs in each CNN engine, and also by allowing multiple instances of the CNN engine to share a bus fabric. You can see this in Figure 2, which shows (at top) an EV61 processor with an 880 MAC CNN (which can be scaled up to 1760 or 3520 MACs), and (below) multiple EV processors on an AXIbus or other network-on-chip fabric.
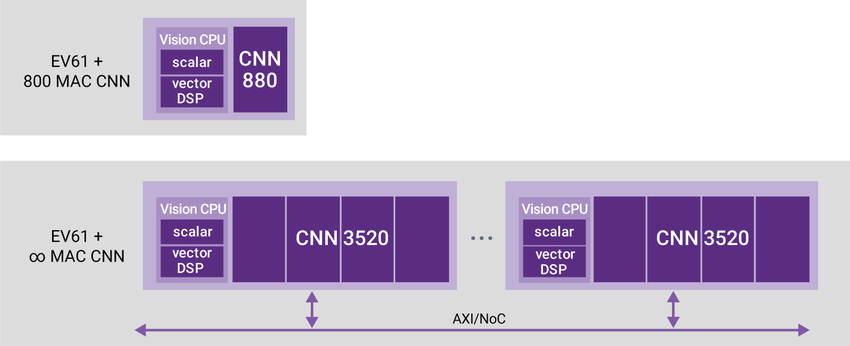
Figure 2 The EV6x processors can scale in both the number of CNNs, and the number of processors that share a bus (Source: Synopsys)
Deep-learning algorithms for embedded vision are developing very rapidly at the moment. Dedicated CNN engines can provide power-efficient implementations of such algorithms, especially when tightly coupled to supporting vector processors as in the DesignWare EV6x Embedded Vision Processor family. Embedded system developers can use tools such as the ZeBu Server to compare power consumption between embedded processor offerings.
Author
Gordon Cooper is product marketing manager for EV processors at Synopsys.
Company info
Synopsys Corporate Headquarters 690 East Middlefield Road Mountain View, CA 94043 (650) 584-5000 (800) 541-7737 www.synopsys.comSign up for more
If this was useful to you, why not make sure you’re getting our regular digests of Tech Design Forum’s technical content? Register and receive our newsletter free.
