OVM testbench API for accelerating coverage closure
Constrained random testbenches excel at quickly hitting the majority of coverage but their effectiveness trails off as coverage closure nears completion. This paper describes a testbench API that sits on top of OVM sequences allowing the existing constrained random infrastructure to be guided, enabling faster, more efficient coverage closure. Design and verification engineers can use this API to write both constrained random and directed random testcases to quickly close coverage. Additionally, tests can easily be modified to simplify debugging or to duplicate interesting test scenarios found through constrained random testing.
FPGA intellectual property (IP) is markedly different in how it needs to be verified and tested from other types. It is inherent that programmable devices will have no one use-case, although reference designs and platforms are built around them. Rather, customers tailor what comes in the box to their own needs and end-applications.
The devices offered by Xilinx therefore have highly parameterizable source code and all configurations must be capable of being tested, including those where end-users may decide to swap in their own technology. Consider the Serial RapidIO Core Architecture in Figure 1. At its heart are the three LOGICore IP layers (logical, buffer and physical functionality). The top-level wrapper provides a high-level, low maintenance interface for most use-models while allowing control of sub-components where necessary. Test strategies must allow the cores to be independently verified as well as in all possible combinations. In addition, the company will refresh its IP usually multiple times a year along with software drops including updates, enhancements and bug fixes.
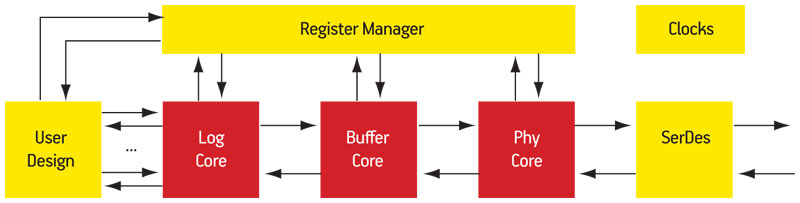
Figure 1
Serial RapidIO Core Architecture
Finally, testcase creation normally requires a number of skills and deep insight into such areas as the Open Verification Methodology (OVM), and the SystemVerilog language. The key objective in this project was to allow testcases to be developed by engineers who do not necessarily have these skills in depth.
Given these challenges, this article describes an API-based testbench strategy based on an extension of OVM. These APIs encapsulate multiple tasks that can be easily chosen, assigned and configured. They have been designed to automatically determine which testcases to run from a library instantiated in the top-level of the API, and are sufficiently flexible to be changed as IP is updated or modified.
In delivering this capability, the testbench API harnesses the capability of OVM in delivering rapid coverage closure in a format that can be used by virtually any engineer on an FPGA project.
The OVM challenge
A typical top-level OVM testcase is ‘empty’. It usually calls a specific virtual sequence that is the testcase in practice which then calls and orders other sequences. This requires a range of skills in addition to a basic understanding of the core architecture and how to control it via the testcase. These can initially be summarized as:
- a knowledge of which sequences and virtual sequences are available;
- a knowledge of how to configure the sequences;
- a knowledge of how to create a virtual sequence; and
- an understanding of how sequences behave.
There are also issues related to testcase and sequence maintenance overhead. When creating targeted sequences for new testcases, you need to copy/paste/edit the setup routines while specifying specific values. While working to debug an existing testcase, it can also be difficult to force specific behavior in a sequence, which might be buried in layers of sequences within the testcase.
Verification engineers will continue to require their specific skills, but to demand them of others in the design flow risks overburdening project resources. Nevertheless, the very specific nature of FPGAs does require that as many team members as possible should be able to run tests for testbench development and bring-up, as well as for regressing and debugging the core. Even during development, engineers may want to write their own testcases when developing code or even just be able to modify what is in an existing testcase when debugging code.
Inside the API
An API is essentially a function or task that starts sequences within a testbench. It hides underlying and redundant details and is agnostic to the testbench configuration. It should allow any user to quickly create tests but have low-level controls for use when needed (for example, when closing coverage) and very closely defined defaults. Details and calls must be published, since they are the ‘public access port’ into the testbench architecture.
The following code depicts the run task inside a specific buffer testcase, as it might appear using the Xilinx API. It is set up to cover TX response priority bumping and back-to-back packets in the RX. While the actual functionality is specific to the Serial RapidIO protocol and Xilinx implementation of the buffer, you can see that the function calls all read in a very straightforward way. Note that only the fields of interest are set with values—all others are left to their default values, which normally means “randomize these”. This allows the testcase to only constrain the fields necessary to focus behavior. Also, every field within the API calls can be set of left random, independently of the other fields. This means that only one API definition is needed, rather than maintaining a suite of sequences, each of which focuses on different behavior.
The API function names, their arguments (with the default and all possible values), and a degree of Verilog expertise are sufficient to write a testcase that has some very specific behavior in order to target corner-case coverage needs.
01 fork
02 //drive clocks and issue resets
according to configuration
03 setup_clk_rst_all()
04 //write 5 resps in the tx path with
random stalls between pkts
05 write_packets(.dir(DIR_TX), .num(5),
.ftype(FT_RESP));
06 //auto read packets out with default
stalls (none)
07 auto_read(DIR_TX)
08 //write 10 random b2b packets in
the rx path
09 write_packets(.dir(DIR_RX), .num(10),
.idles(0));
10 //auto read rx packets with random
stalls between reads
11 auto_read(.dir(DIR_RX), .min_idles(0),
.max_idles(4));
12 //nak ~50% of the time with an implicit
ack rate on naks of 5%
13 auto_packet_sched(.num(5), .pna_rate(50),
.jump_rate(5));
14 join
In this example, the calls are run in parallel and execute on multiple sequencers. There is a setup clock restart that does some basic testbench maintenance. Figure 2 shows more detail of the arguments that can be applied to and the default values for ‘write_packets()’, one of the main commands in the API (the naming is not relevant other than that it reflects the way the testbench is structured in terms of reads and writes—you should choose whatever names make sense for your design and protocol).
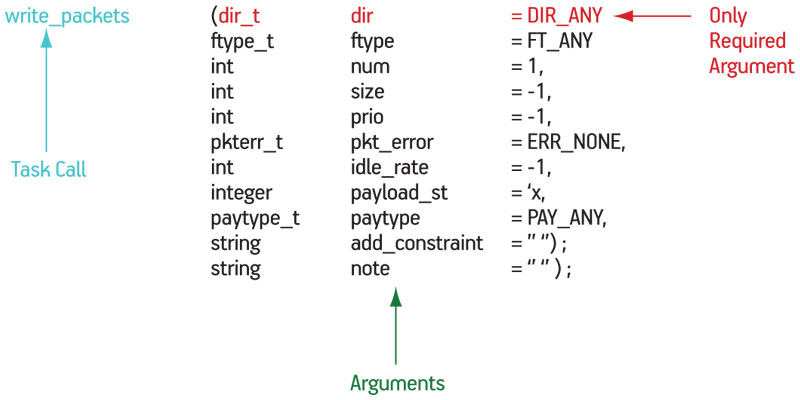
Figure 2
write_packets() API
So what’s under the hood? The API itself is actually built in the Serial Rapid IO test base, which is itself built using OVM. It is extended to focus on the specific design-under-test submodules. It holds all the sequences and sequencers at the top level, partly to control the code size. If the sequences and sequencers were put in the extended test base, all of the APIs would have to be copied to all of the subsidiary testbenches.
With these elements in place, a further critical element is a configuration object. This object contains all the configurable and parameterizable settings of the core, including which submodules are active. In this role, it is used by the API calls to route the test commands to the appropriate sequencers from their placeholder calls in the top level. This routing is handled automatically by the API calls using a case statement in the Serial RapidIO test base, which directs the call to the appropriate sequencer driving the appropriate interface.
Figure 3 shows three routing scenarios—buffer-only, phy-only and buffer-and-phy—and where write_packets goes in each of these.
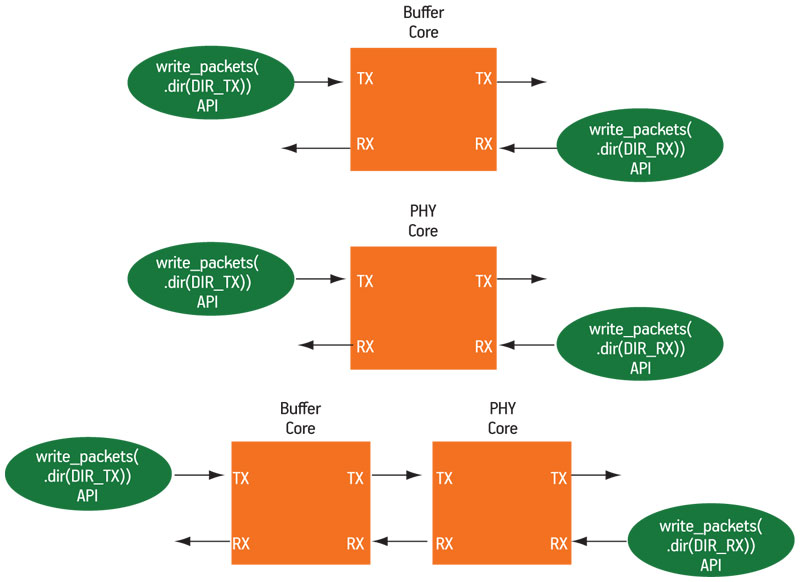
Figure 3
Routing scenarios
Once a destination has been determined, a write_packets command will always ‘do the right thing’. For an RX buffer path, the system monitors the buffer status and only writes packets when the buffer is not full; for a TX buffer path, it monitors a response_only signal and only writes responses when that signal is asserted (however, this is for normal operation where we want the buffer to be active—the user can override this behavior by forcing fields within the API call). In addition, there are denial macros so that APIs are only used where they are supported and unsupported cases are automatically flagged to the user.
The APIs are constructed from tasks rather than, as more typically happens, functions. This is because the calls are wrapped around sequences, and they take simulation time. Since functions in Verilog may not take time, the APIs must be implemented as tasks.
Because the APIs must be tasks, no return field is available. However, there is an easy workaround by creating an inout argument, which allows data to be passed by reference through the task call. Code for this would be:
01 task read_packets
(dir_t dir =DIR_ANY,
02 int num = 1,
03 int idle_rate = -1,
04 inout pkt_seq_item return_val);
Return values is one of the advanced features of the API. It comes into play when a testcase may require additional information from the core to target specific scenarios to close coverage. An example would be configuration register data that allows changes to testcase behavior on-the-fly.
For configurability, the API is easy to set up for ‘any’ or ‘specific’ instances but specifying a range of values is more difficult. However, as long as you have access to the call tree (including the lowest level seq_item), it can be adopted for anything by adding a mechanism to specify a constraint at the top level and by adding constraints to the lowest level seq_item. Note that the lower level sequences in the call tree must pass along these fields to the lowest level sequencer item. However, this work is well worthwhile—once you create this pipeline, it’s trivial to add more constraints if needed to close coverage, without having to create and maintain a library of sequences to constrain specific behavior.
01 add_constraint = “ “
02 constraint small_pkts;
03 function void constrain_other
(string oth_constr);
04 case (oth_constr)
05 “small_pkts”:
small_pkts.contraint_mode(1);
06 function void unconstrain_other
(string oth_constr);
The key
This environment depends on the creation of the API library illustrated in Figure 4. It collects the sequences and sequencers into a known situation that can be reused anywhere with a high level of control. Although constructed as a sequence in itself, the API is little more than a pointer. For a write_packet task, it forces any of the overridden fields, randomizes the others, starts the sequence, and converts the response to a return value.
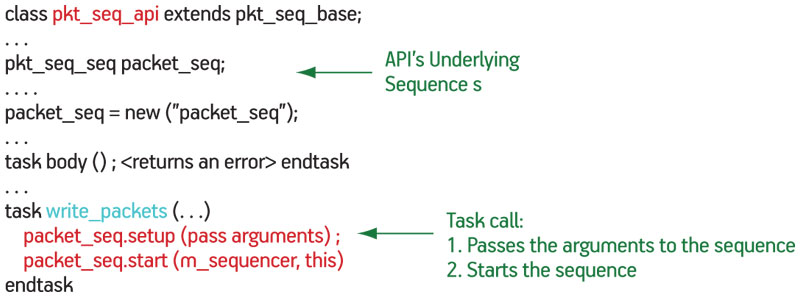
Figure 4
Simple API library
To get all that verification power still requires that the API be built by engineers with a close understanding of OVM, SystemVerilog and all the other aspects of their specialty to construct the elements that lie behind the interface. However, it does not require that the testbench user necessarily have that knowledge. The result is an abstraction that allows anyone to write tests and provides options for re-use which provides a lot more flexibility in scheduling work during coverage closure phases.
Xilinx
2100 Logic Drive
San Jose
CA 95124
T: +1 408 559 7778
W: www.xilinx.com