Using CCIX to implement cache coherent heterogeneous multiprocessor systems
The increasing use of GPUs, FPGAs and even dedicated machine-learning chips alongside standard CPUs in high-performance applications is creating demand for a better way to ensure that when these chips work together, they handle data in an effective and efficient way.
In order to speed-up access, we’ve long used caching to store key data closer to the processor than main memory. When multiple CPUs share a common memory space, they can achieve higher performance if they can use hardware to communicate the cached and/or cacheable state of pieces of that memory. By doing this, each CPU can safely work on a portion of a common dataset without having to use slow software semaphores to control access. If CPU A has cached a piece of memory, it can ensure that CPU B does not modify that same memory space or use an out-of-date copy of the data.
To better understand cache coherency, let’s look at a commonly used coherence protocol known as MESI, which refers to the four possible states of a cache line: Modified, Exclusive, Shared, or Invalid.
Modified means a cache line is only stored in the current cache, and is different from the data in main memory (it is ‘dirty’ in cache parlance). Any other agent attempting to read from an address marked somewhere in the system as Modified will cause the cache (which has the modified data for the address) to write the data back to main memory before the other agent’s read may proceed.
An Exclusive cache line is also only stored in the current cache, but matches the data in main memory (‘clean’ in cache parlance). If the agent owning that cache line changes it, the state will become Exclusive.
A Shared cache line is also ‘clean’, like an Exclusive cache line, but may also exist in other cache(s) in the system (where it would also be in the Shared state).
Finally, an Invalid cache line is an unused or no longer valid cache line.
To make this work, all the caches in such a system must communicate several pieces of information with each other. They must support ‘snooping’ or monitoring of bus transactions from other agents to determine when their cache state needs to change, and they must have a way to communicate state changes to other caches in the system.
A new approach to coherency
The increasing complexity of the multiprocessor systems that are being developed to address high-performance applications has created a demand for faster interconnects than are currently available. It is also creating demand for a more effective approach to cache coherency, to enable faster access to memory in heterogeneous multi-processor systems.
For this reason, a new industry standards body called the CCIX Consortium has been formed to develop specifications for Cache Coherent Interconnect for Accelerators (CCIX).
The standard focuses on enabling hardware accelerators to use memory shared with multiple processors in a cache-coherent manner. The CCIX protocol defines a set of cache states and associated messages and mechanisms to achieve this. CCIX’s coherence protocol is vendor-independent, so CPUs, GPUs, and other accelerators can participate equally and without onerous licensing restrictions.
CCIX for cache coherency
The CCIX specification builds on PCI Express, so its coherence protocol can be carried across PCI Express links with little or no modification.
As shown in Figure 1, adding some logic can extend an existing PCI Express controller to implement a CCIX transaction layer. The CCIX transaction layer carries the coherence messages, while CCIX protocol layer and link layer blocks implement the coherence protocol and act upon it. These blocks require tight integration with internal system-on-chip (SoC) logic for caching, and so will be very specific to each SoC’s architecture. SoC designers implementing CCIX typically partition the CCIX protocol and link layers from the CCIX transaction layer, so they can achieve tight integration with the internal SoC logic.
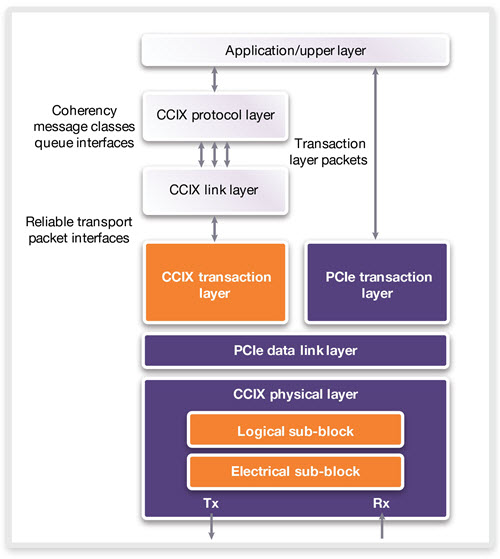
Figure 1 The CCIX specification builds on PCI Express to implement a CCIX transaction layer (Source: Synopsys)
Moving beyond 16GT/s
One of the biggest attractions of CCIX is its compatibility with PCI Express. CCIX’s cache coherency protocol can be carried over any PCI Express link running at 8GT/s or faster. The highest data rate specified by PCI Express 4.0 is 16GT/s, or about 64GB/s of total bidirectional bandwidth on a 16-lane link, but some members of the CCIX Consortium need to go faster. By raising the transfer rate to 25GT/s, a CCIX link can approach bandwidths of 100GB/s, in what is known as CCIX’s Extended Speed Mode (ESM).
The CCIX Consortium has had to find a way to make ESM-capable components compatible with PCI Express components. Two CCIX components that want to communicate with each other proceed through a normal PCI Express link initialization process to the highest mutually supported PCI Express speed. At that point, software running on the host system can interrogate CCIX-specific configuration registers to find out whether both components are ESM-capable and the highest speeds they support. That software then programs other CCIX-specific registers on both components to map PCI Express link speeds to CCIX ESM link speeds. From that point forward, the link negotiation process focuses on achieving CCIX ESM speed(s), by forcing the interface to retrain the link for ESM speeds. Doing this enables the two components to communicate at up to 25GT/s, some 50% faster than current PCI Express interfaces can support.
Conclusion
Designers looking for a cache-coherent interconnect with a relatively easy migration path from PCI Express should consider CCIX. Synopsys offers a complete CCIX IP solution that is based on its silicon-proven DesignWare IP for PCI Express 4.0, which is validated in over 1,500 designs.
Further information
Synopsys is an active member of the CCIX Consortium and PCI-SIG.
Author
Richard Solomon is the senior technical marketing manager for Synopsys’ DesignWare PCI Express Controller IP. He has been involved in the development of PCI chips dating back to the NCR 53C810 and pre-1.0 versions of the PCI spec. Prior to joining Synopsys, Solomon designed the architecture and led the development of the PCI Express and PCI-X interface cores used in LSI’s storage RAID controller chips. He has served on the PCI-SIG Board of Directors for more than 10 years, and is currently vice president of the PCI-SIG. Solomon holds a BSEE from Rice University and 25 US patents, many of which relate to PCI technology.
Company info
Synopsys Corporate Headquarters 690 East Middlefield Road Mountain View, CA 94043 (650) 584-5000 (800) 541-7737 www.synopsys.comSign up for more
If this was useful to you, why not make sure you’re getting our regular digests of Tech Design Forum’s technical content? Register and receive our newsletter free.