Optimizing cloud computing for faster semiconductor design
How Cadence, Intel and Xuropa accelerated the semiconductor design process by squeezing 15% more capacity out of a virtualized server farm
Companies have been virtualizing their data centers since the 1990s to increase the utilization of their servers, automate the provision of computing power and cut costs.
Virtualisation is a key technique in ‘cloud computing’, which is defined by the National Institute of Standards and Technology [1] as:
“a computing model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.”
The ability to access large amounts of computing resources on demand could help chip designers accelerate compute-intensive jobs such as verification and so get chips to market more quickly. Using the optimizations described in this feature could squeeze even greater utilization out of cloud resources, further reducing their time to market.
Using the cloud
There are two main forms of cloud computing:
- private clouds, which dedicate a set of servers to an organisation. This model has been in use in enterprises for years, labelled as client-server or grid computing.
- public clouds, enabled by fast Internet connections, over which companies can move data to an external provider, have it do the computation and return the results at a cost which is competitive with internal data centers. [Public clouds can achieve higher utilizations and hence lower costs than private clouds by running jobs from multiple customers on the same hardware [2].]
Benefits
Some key characteristics [3] of cloud computing include:
- automated provisioning and data migration [4]: users don’t have to think about buying a new server, loading an OS and copying on the data when they need more computing resources. So long as the cloud provider can meet demand, computing resources can be ordered and put to work at short notice, almost like a utility such as water or electricity.
- Seamless scaling: users only pay for what they use [5].
- Increased multi-tenancy: virtualization and multi-core computing means that several customers can share a server, which improves the provider’s utilization and so cuts their costs and prices.
Risks
Despite these benefits the semiconductor industry has been slow to use the public cloud, despite their potential advantages over private cloud offerings. Here are three reasons for this reluctance:
- Security [6]: This issue has been addressed technically through the use of firewalls and the encryption of data as it traverses the open internet. The greatest threat to cloud security is the people who can access the intellectual property (IP) of an organisation from within. This threat exists irrespective of cloud technology and can only be addressed through hiring, management and monitoring processes.
- Liability [7]: When a semiconductor vendor puts their IP on servers outside of their control, a liability issue opens up. If something goes wrong, who is liable?
- Performance guarantees: It’s hard to offer performance guarantees when a set of servers, arranged as a cloud, have been virtualized and are running a constantly changing population of thousands or millions of jobs. This lack of predictability makes it more difficult to commit to using public cloud resources for critical projects.
Optimizing cloud performance using real-time state information
While virtualization has delivered benefits by abstracting away the complexities of the hardware, this abstraction also makes it difficult to guarantee computational performance metrics such as CPU, memory, and I/O bandwidth, because the real-time state of the underlying hardware is unknown. Without that state information it is hard to predict performance and impossible to match the demands of a particular job to the resources of a particular server.
You can make a ‘best effort’, setting initial scheduling policies for a particular server so that it has enough CPU, memory and I/O bandwidth to run a set of jobs simultaneously. As soon as the jobs start running, however, their resource demands may change. For example, one job may need more memory bandwidth than forecast, starving other jobs of the resources they need to run at the same time. Meanwhile another job may be under-using its allocated memory, releasing resources that could be reapplied if the hypervisor was aware of the opportunity and able to manipulate the resource allocations appropriately to match the dynamic requirements.
Building a resource-optimizing cloud framework
Cadence Design Systems, Intel, and Xuropa have jointly built an experimental cloud-computing infrastructure to solve this problem. It uses EDA tools from Cadence, HP servers based on Intel processors, the OpenStack cloud stack software, and a cloud platform from Xuropa.
Figure 1 shows the main components used in our experiments. Each Intel-powered HP server runs a Ubuntu distribution of Linux, with the OpenStack software installed on top. The OpenStack cloud operating system includes a ‘kernel virtualization machine’ to create and control multiple virtual machines (VM1, VM2, VM3…). The Cadence tools are installed on the virtual machines. Xuropa’s cloud-management and abstraction platform handles access security, license management, and cloud instance automation.
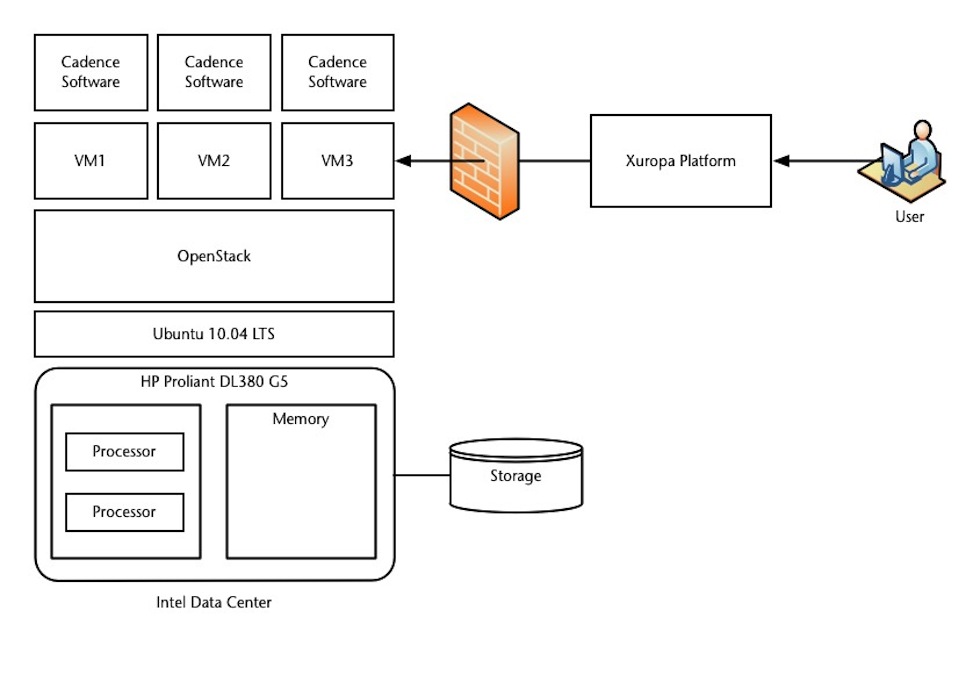
Figure 1
Abstracted cloud system (Source: Xuropa – click image to enlarge)
Users log in to the system through the Xuropa platform, and run jobs using scripts that control the Cadence tools. The idea is to simulate a chip design engineer using a browser to access the cloud and execute jobs without the need for IT coordination and support.
Framework details
The key component in the overall cloud framework is its intelligent monitoring capacity.
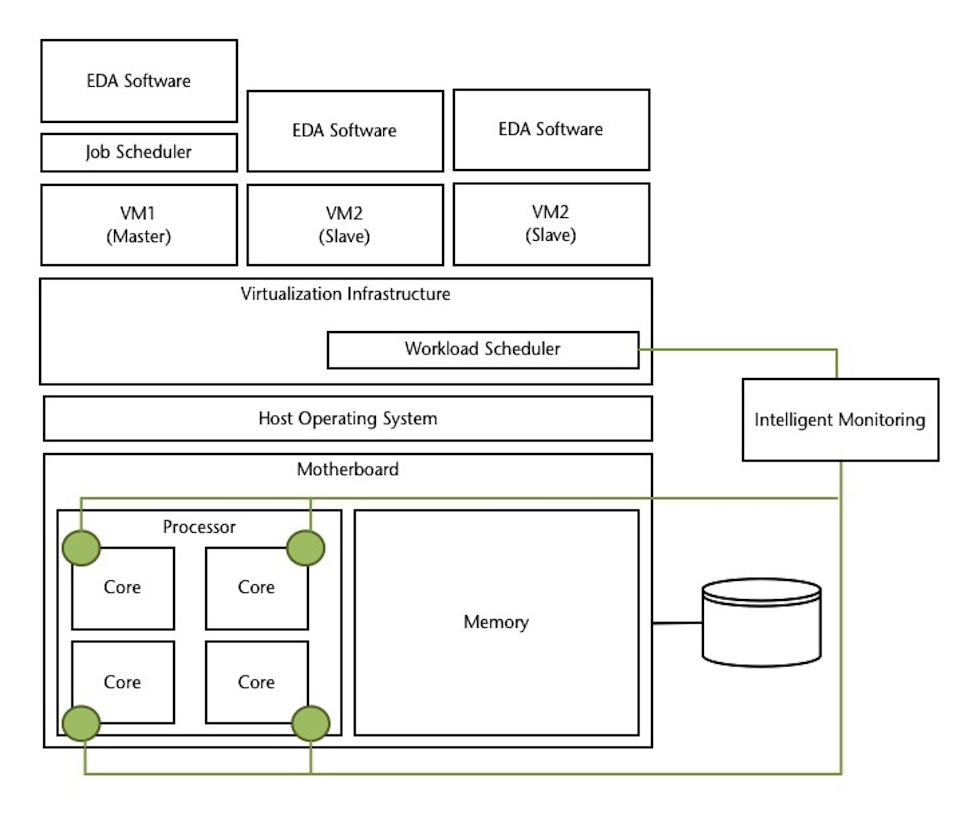
Figure 2
Abstracted cloud stack with intelligent monitoring (Source: Xuropa – click image to enlarge)
The intelligent monitoring system extracts hardware statistics from system counters and monitors on each processor core in each processor in each server. The framework uses this information, along with the characteristics of each workload, to work out where each job should run and the best way to configure the overall cloud to meet the demands placed on the hardware resources.
These calculations are also guided by appropriate policies. After characterizing a number of EDA workloads using software and semiconductor designs provided by Cadence, we developed a policy based on memory bandwidth to guide the OpenStack nova scheduler to allocate workloads to the compute nodes that best met the needs of each workload.
Experiments and results
The vast majority of cloud environments, especially in the public cloud, are not designed to support the kind of high-performance computing jobs used in semiconductor design and verification. EDA tools need a varying mix of CPU utilization, memory and I/O bandwidth as they run, and the mismatch between their resource needs and the architecture of the cloud results in lower application performance and less cloud efficiency than would be possible with some optimization.
We built our experimental set-up so that it modeled the heavy utilization found in most IT departments that are trying to maximize the return on their IT spend, so our results would be relevant to real EDA users.
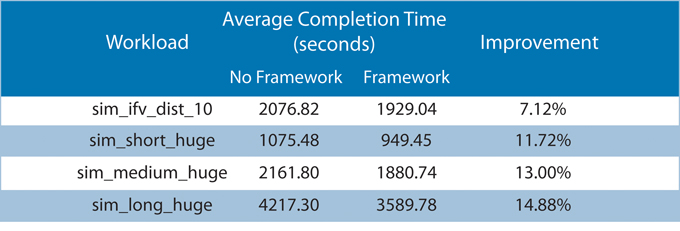
Table 1
Benchmark results with and without optimization (Source: Cadence/Intel/Xuropa – click image to enlarge)
We found that although the Cadence tools were better at managing memory bandwidth utilization than expected, our framework technology was still able to demonstrate up to 15% improvement in cloud throughput, when compared to the same workloads run on a cloud without the intelligent monitoring and scheduling technology.
Conclusions
It will take vast amounts of computing power to design and verify the billion-gate chips that are on the horizon. Technologies such as the framework we have described here can increase the efficiency of private clouds, and may also help make public cloud offerings more attractive by driving down the overall cost of design.
This framework and similar optimizations are also contributing to a trend that is driving the cost of computing towards zero. Under these economic circumstances, it is worth asking whether a semiconductor vendor could move their design work to the cloud and become a ‘CAD-less’ chip company, in the same way that chip companies gave up their manufacturing assets and became fabless in the last century.
References
[1] P. Mell and T. Grance. (2009). The NIST Definition of Cloud Computing (Version 15 ed.). Available: http://csrc.nist.gov/groups/SNS/cloud-computing/cloud-def-v15.doc
[2] G. A. Fowler and B. Worthen. (2009). The Internet Industry Is on a Cloud – Whatever That May Mean. Available: http://online.wsj.com/article/SB123802623665542725.html
[3] N. Sehgal, S. Sohoni, Y. Xiong, D. Fritz, W. Mulia, J. M. Acken, “A Cross Section of the Issues and Research Activities Related to Both Information Security and Cloud,” in Institute of Electronics and Telecommunication Engineers, vol. 28, pp. 279-291, 2011.
[4] G. Soundararajan and C. Amza, “Online Data Migration for Autonomic Provisioning of Databases in Dynamic Content Web Servers,” in Proceedings of the 2005 conference of the Centre for Advanced Studies on Collaborative research, Toranto, Ontario, Canada, 2005, pp. 268-282.
[5] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. Katz, A. Konwinski, G. Lee, D. Patterson, A. Rabkin, I. Stoica, and M. Zaharia, “A View of Cloud Computing,” ACM Communications, vol. 53, pp. 50-58, 2010.
[6] L. M. Kaufman, “Can Public-Cloud Security Meet Its Unique Challenges?,” IEEE Security & Privacy, vol. 8, pp. 55-57, 2010.
[7] M. Christodorescu, R. Sailer, D. L. Schales, D. Sgandurra, and D. Zamboni, “Cloud Security is not (just) Virtualization Security: A Short Paper,” in Proceedings of the 2009 ACM workshop on Cloud Computing Security, Chicago, Illinois, USA, 2009, pp. 97-102.
Authors
James Colgan – Xuropa, Inc., San Francisco, CA
James Colgan started his career as an embedded software developer for Panasonic in Japan. After six years in Japan defining and launching products (and reaching fluency in Japanese), James headed out to Silicon Valley where he spent the years prior to founding Xuropa in executive leadership roles (strategy, marketing, and business development) in high-tech, software and intellectual property companies.
Naresh K. Sehgal – Intel Corp., Santa Clara, CA
Naresh is a software manager at Intel, responsible for new architectural investigations. He has been with Intel for 22 years in various roles, including EDA development, silicon design automation, Intel-HP alliance management, and launching virtualization technology on all Intel platforms.
Naresh holds a PhD in computer engineering from Syracuse University, and an MBA from Santa Clara University. He holds 4 patents and authored more than 20 publications in the CAD domain.
Mrittika Ganguli – Intel Corp., Bangalore, India
Companies
Cadence Design Systems 2655 Seely Avenue San Jose, CA 95134Phone: 408.943.1234
Fax: 408.428.5001 Intel 2200 Mission College Blvd.
Santa Clara, CA 95054-1549
USA
(408) 765-8080 Xuropa 441 28th Street San Francisco CA 94131-2217