DVCon Europe best paper assesses clock design
At DVCon Europe last year, engineers from Qualcomm received the best paper award for their work on the energy aspects of SoC clock design and how changes to RTL design affect them. Michele Chilla and Leonardo Gobbi, working at the company’s facility in Ireland, analyzed three approaches to clock for area, power, flexibility and routing congestion, basing the work on logic used in the Snapdragon 855+ SoC.
The logic used for the assessment is based on a real example design that employs more than 300,000 flops together with features such as the bus infrastructure used to internal cores. The RTL assessed also includes all the DFT logic. The choice of target reflects the trend for SoCs to move from a single clock to being an array of independently clocked subsystems that can be clock gated, powered down to save more power and possibly also frequency-scaled depending on what software workload they are running at the time. As well as being potentially more energy efficient, the multiclock approach can also help design closure as it relaxes the timing constraints in many circumstances.
The multiclock approach calls for the development of dedicated clock-control units (CCUs) to generate their internal clocks, calling on clock driver firmware to program the internal clock multiplexers, PLLs, and clock dividers of individual domains. How the CCUs interact with their downstream clock domains has a major effect on energy consumption both in terms of switching and leakage. To test out those effects, the Qualcomm team built three RTL variants for taking clock signals from the oscillators and PLLs controlled by the CCU and, in turn, driving their internal clock domains through trees of dividers:
- Low-Opt: All clocks are synchronous and generated from the same clock mux. This implementation provides poor support for dynamic frequency scaling because all the clock branches are derived from a single clock mux. This in turn leads to tight timing constraints needing to be handled in design closure.
- Mid-Opt: All clocks are again generated from a single clock mux but are grouped into different clock domains. Because of the use of fixed dividers, the frequency-scaling flexibility remains as limited as the Low-Opt. But the structure allows more relaxed timing constraints at the back-end stage which may be used to reduce routing congestion and the need for large numbers of clock buffers.
- High-Opt: The clock for each domain group is generated from a dedicated clock mux, an approach that allows for granular dynamic frequency scaling as well as more relaxed timing constraints and a lower requirement for buffers than the Mid-Opt structure as well as a lower fanout per clock branch.
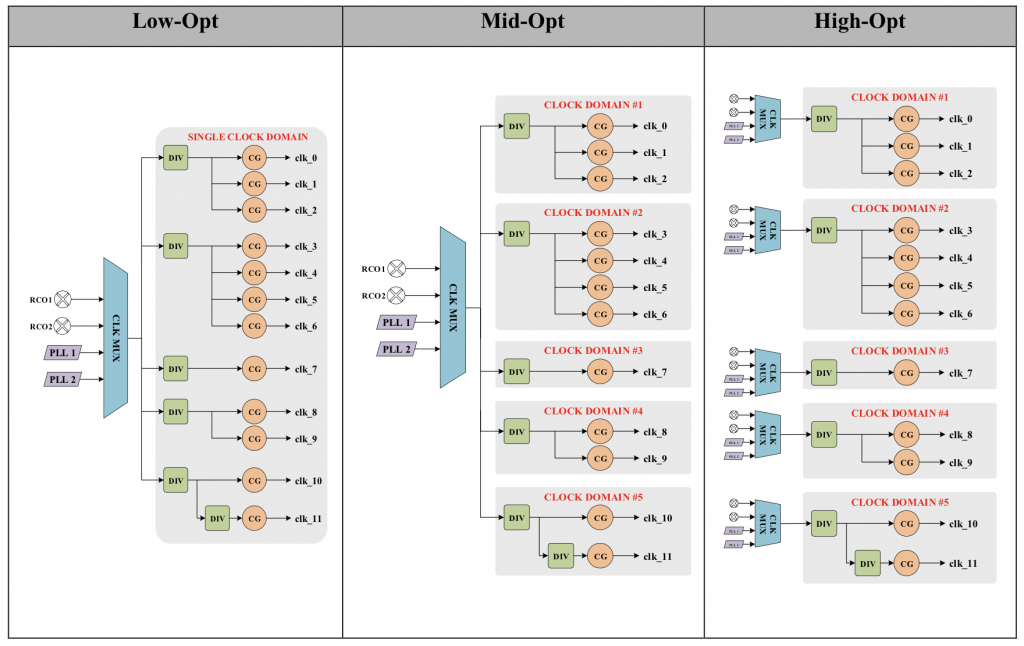
Image Clock distribution options assessed in the paper
To evaluate how the different structures perform, the team gathered data from the Synopsys Design Compiler tool, with the power information generated using its Power Compiler subsystem. Congestion information came from the Design Vision tool, which extracts a topological view of clock branches across a subsystem down to six levels of connection, which provides a way of predicting post-layout timing and area use.
Overall the analysis found the Mid-Opt approach reduced power by 16.4 per cent compared to the Low-Opt, thanks to a switching power reduction of a little over 20 per cent balanced slightly against increased power required by the extra RTL logic Mid-Opt structures need. Buffer insertion fell slightly but routing congestion did improve, according to Qualcomm.
High-Opt increased total power consumption, rising slightly above Low-Opt but 21.6 per cent ahead of Mid-Opt. However, routing congestion improved significantly because the layout tool had much greater flexibility in placing and routing the clock tree components, though the number of buffers only fell slightly compared to Mid-Opt. Though the clock power does increase slightly compared to Mid-Opt, this does convey the benefit of more granular frequency control which may pay off in system-level energy efficiency.