IP hardens up again

Richard Goering
System-on-chip designers who work with third-party silicon intellectual property (IP) will see some significant changes at 32nm and below. Physical IP will be highly optimized to specific processes, following intense collaborations between large IP providers and foundries. Processor IP may become less synthesizable and make more use of hard macros.
On the plus side, commercial IP will take better advantage of the power and performance benefits of advanced process nodes. But it may not be as portable as it was in previous process generations, and the development costs will be higher. Independent IP development will give way to deep and lengthy partnerships, possibly reducing the number of third-party IP providers over time.
Such are the conclusions to be drawn from presentations and interviews at the October ARM Developer’s Conference (ADC), which closely followed a press release in which ARM and members of the Common Platform alliance (IBM, Samsung and Chartered Semiconductor Manufacturing) announced their intent to develop a physical IP ‘design platform’ based on the alliance’s 32/28nm high-k metal gate (HKMG) technology. Under this agreement, ARM will work with the platform’s three members to develop physical IP including logic, memory and interface components, providing a foundation for future Cortex processor IP products that take fullest advantage of the technology.
ARM already works with foundries to provide physical IP including standard cells, I/Os and memories. So what’s different about the 32nm announcement? “Normally, we would take the PDK [process design kit] and run,” said Simon Segars, general manager of ARM’s physical IP division. “Here, we’ve had engineers working with the guys at Common Platform for the past six months. We’re engaging at a much earlier point, and by engaging earlier, there’s much more room for optimization.”
It’s a significant shift in the way IP is developed, according to Segars. “Historically, all physical IP was designed in complete isolation from what the actual system people were trying to build,” he said. “Here, what we’re putting on top of the foundation IP platform is enhanced IP, including memories and special cells that enhance performance, and then we’re building an application platform on top of that.”
Kevin Meyer, vice president of industry marketing and platform alliances at Chartered, noted that previous foundry collaboration with IP providers has focused only on developing libraries of physical IP. “The difference at this [32nm] node,” he said, “is that ARM is going beyond just working with us on low-level libraries and memory compilers. They are adding value on top of that with enhanced IP, specialized memory compilers, and other elements. Additionally, they’re going to optimize some of their [processor] cores to take full advantage of high-k metal gates. So that’s three layers of IP, where historically we have only worked together on libraries and compilers.”
It’s a new level of cooperation, Meyer said, and this “interdependence” is essential to deliver fully optimized libraries, memory compilers and other IP that can take full advantage of the power and performance benefits of HKMG. “We’ve got to engage earlier and take feedback from IP providers,” he said. “We want to make sure we optimize the process to meet the needs of the IP companies.”

Meyer: emphasizing high-k, metal gate
With the Common Platform announcement, ARM is focusing on physical IP building blocks rather than announcing any new Cortex processor cores optimized for 32nm HKMG technology. But ARM will be able to optimize its cores based on what it learns from the Common Platform alliance. “Certainly as we keep the processor line going, we’ll talk about the power and performance advantages you can achieve based on the implementation flow for this particular process,” Segars said.
Why HKMG? “It brings better scaling, lower leakage, lower dynamic power and better performance,” Segars said, noting that the cost should be “pretty much the same” as ordinary bulk CMOS technology. In a presentation at ARM DevCon, Meyer said that HKMG can provide 40% better performance and a 100X reduction in gate leakage compared to non-HKMG
processes, with better manufacturability and reliability. It is, he said, Chartered’s “go to market” strategy for 32nm. Meyer expects to see prototype chips for this process starting in late 2009, with full volume production in 2011.

Segars: more structured flows for performance at 32nm
The IP business gets “harder”
Behind the ARM/Common Platform announcement lie some trends that may influence all star IP development at 32nm and below. One is a “pendulum” shift back to hard cores, Meyer said.
At 0.35 and 0.18um, he noted, most processor cores were hard cores that were tuned specifically to the process in order to get the required performance. ARM7 cores, for instance, were originally hard cores. Customers would choose the core closest to their requirements, and it would be hardened to meet performance demands.
As the industry moved to 0.13um, a variety of optimized transistors became available, and IP providers began a shift to synthesizable cores. “Even though you might leave 25 to 30% on the table by being synthesizable, the cores were much more flexible,” Meyer said.
But now, Meyer continued, the momentum is “moving back to hard IP. It can’t be a ‘least common denominator’ thing any more.” ARM, he noted, is “working with us to optimize the next generation of their cores. These will take full advantage of the benefits of HKMG through an intimate understanding of the process.”
While he agreed with the general trend, Segars said there will always be a place for fully synthesizable process cores, even at 32nm. “But for high-end performance,” he noted, “you will see a more structured flow for putting your processor together, where you will take some custom blocks and some logic that’s been synthesized.” For example, a register file could be implemented as a hard macro to get the best possible power and performance.
Segars pointed to the Cortex-A8 as a ‘trailblazing’ example. It can be implemented as a soft core, but also with custom blocks to obtain 25% better performance. With hard macros, IP is less portable. A mitigating factor, Segars said, is that there will be fewer available processes with advanced process nodes.
Another possible shift at 32nm is the earlier availability of optimized IP. “If we can offer IP solutions earlier in the process than before, customers can consider them, especially if they’re proven and optimized for the process,” Meyer said. “Our relationship with ARM speaks to promising that silicon IP is optimized as early in the process as possible.”
Segars noted that 32nm physical IP will have to be delivered with detailed models. “There are very complex power and noise models,” he said. “The amount of data just goes up enormously.” On the processor side, he foresees a trend toward “fast but inaccurate” architectural-level models for system-level design and high-level software development.
Source: ARM
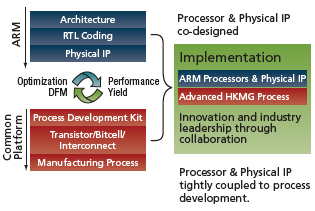
FIGURE 1 Implementation requires partnership
Segars also noted that the cost of developing IP rises with each process node. “Engaging early requires a greater investment from ARM, but the benefit is better optimization and a better product,” he said. Higher costs may bring about more consolidation of the third-party IP market. “There are a lot of small guys at the moment,” he noted. “The greater the cost becomes, the fewer the people who can afford to do it.”
Reinventing the IDM model
In his DevCon presentation, Meyer noted that the semiconductor industry went from an IDM model in the eighties to a fabless model in the nineties, and that today, “there is chaos in the value chain” following this disaggregation. This chaos results from complexity, new materials, and more IP from multiple providers. The antidote, he suggested, is the development of collaborative ecosystems.
“By working with ARM to optimize their physical IP,” he said, “they are going to be able to offer their customers the kind of performance that IDMs are able to deliver.” The ARM/Common Platform alliance, Meyer said, points to “complete collaboration from invention to implementation, which you would not otherwise get unless you bought a chip from Intel.”
Meyer later commented that Intel’s recent move into systems-on-chip is a “game change” in the semiconductor industry. Intel is looking to move down from PCs into mobile devices, he said, while ARM is planning to build PC-like capabilities into mobile devices.
Intel’s shadow looms large at ARM. “To get the best performance, collaboration is required,” Segars said. “We want to put processors into the market that mean Intel never gets a foothold in the mobile space, and we can’t do that alone.”
At 32nm and below, it now seems large IP providers and foundries must work together to provide process optimization on par with IDMs. That requires a new level of collaboration that will profoundly impact the semiconductor industry.
Richard Goering is editor-in-chief of SCDsource (www.scdsource.com)