Doc Formal: Harness the power of invariant-based bug hunting
 Ashish Darbari is CEO of formal verification consultancy and training provider Axiomise.
Ashish Darbari is CEO of formal verification consultancy and training provider Axiomise. What’s the biggest design you can verify with formal?
It’s a question I get asked a lot. The short answer I always give is it is not the size that matters but the micro-architecture of the design – and yes, design configuration does play a role, but it is not the only thing that rules the proof complexity.
In the last decade, I have pioneered some fundamental abstraction methods and showed how they can be used for controlling proof complexity – my passion over the years has been in understanding how to obtain proof convergence and build exhaustive proofs. Some of this work has been published by me and my colleagues in papers in DAC 2014, CDNLive EMEA 2014, Cadence Jasper User Group 2015, and Formal Verification conference 2016. Recently, Iain Singleton from Synopsys and his collaborators presented aspects of this in a tutorial at DVCon USA 2018.
Though I have always emphasized the value of this work in the direction of building exhaustive proofs I have not explicitly mentioned before the value of this methodology for bug hunting.
In this article, I would like to elaborate on that and show how one can find bugs in less than 10 minutes in designs with 1039,452 states running on a machine with 8GB RAM and a single Intel i5 7300U CPU core. That number for states is greater than the number of stars in the universe.
I will cover the core details here, but those who want to take a deeper dive are referred to other prior-published papers or can contact me. We cover such methods in detail in the training program offered by Axiomise.
A pivotal example
I have a weakness for the FIFO. I often say light-heartedly that everything can be reduced to a FIFO (well, with enough abstraction). FIFOs are considered simple components often used for storage and ensuring that objects received first are transferred out first – hence first-in-first-out (FIFO).

Figure 1. A FIFO and its expected behavior (Axiomise)
Although the design is conceptually simple, FIFOs can often have all kinds of corner case bugs. These reside mostly in control logic and especially when the implementation is anything more complex than a shuffle FIFO. Here’s a classic one: a read issued into an empty FIFO causes Xs to be read out and crashing a CPU boot loader in an FPGA.
In many ways, a FIFO also represents a microcosm of different design types. It has arrays, addresses, pointer calculations using counters, and FSMs controlling empty and full states. So, in a way it combines the complexity of verifying designs with big arrays, counters, and FSMs, all rolled into one design. All of this has an impact on verification complexity.
Formal verification
Formal verification of FIFO-type designs is interesting. One cannot just use another FIFO model to verify an underlying FIFO DUT because this causes an enormous state-space explosion. That is due to the cross product of states between the design model and the verification model. We have to start by thinking differently about how we should carry out simulation-based verification.
In simulation, we send a huge number of combinations of 0s and 1s and control the push and the pop; in formal we do not do this. For starters, we use symbols and not 0s and 1s, and we do not control the inputs the way simulation does. Rather, we declare “what we need to observe” and state that as a claim using an assertion over the symbols. In fact, the only thing we constrain is that we cannot push on a full FIFO and not read on an empty FIFO unless the FIFO is designed to work like that – in which case we assert these conditions as well as opposed to constraining them.
The basic proposition we use to verify a FIFO using formal is to establish that for any two symbolic data values, d1 and d2, that arrive in a predetermined order at the input ports, they leave the output port on a read in the same order in which they were received. We state this proposition using two symbolic variables and the formal tool will check across all possible data values and time points.
A higher-order logic property for checking correctness of ordering is shown below. In this example, ‘sampled_in_d1_before_d2‘ and ‘sampled_out_d1_before_d2‘ are predicates that indicate when one event happens before the other. The following requirement needs to hold for all (∀) d1 and d2.
∀d1 d2. sampled_in_d1_before_d2 => sampled_out_d1_before_d2
Using our method, the above requirement can be turned into the following SystemVerilog assertion (SVA), shown here with default clocking.
assert property (sampled_in_d1 && sampled_in_d2 && !sampled_out_d1 |-> !sampled_out_d2)
The above property needs to have the following constraint that enforces d1 to be sent into the DUT before d2.
assume property (!sampled_in_d1 |-> !sampled_in_d2)
In the SVA syntax shown above, we model ‘sampled_in’ and ‘sampled_out’ events using registers. When the watched value ‘d1‘ (resp. ‘d2‘) appears on the input data port of the FIFO, we set the ‘sampled_in_d1‘ (resp. ‘sampled_in_d2’) registers, which are on reset have the value 0. The ‘sampled_out’ registers get set when the watched value is ready to appear at the output port. The ‘sampled_out’ registers are more interesting in the way that they rely on a pair of tracking counters (one each for d1 and d2), ‘tracking_counter_d1‘ and ‘tracking_counter_d2‘.
The tracking counters themselves simply increment on a push of any data value in the FIFO but stop incrementing when the respective watched data values are seen on a push. This way these counters keep count of “how many elements are ahead” of the watched data. On a pop, both the tracking counters decrement. When the tracking counters equal the value of 1, the watched values are ready to be seen on the output port, hence allowing us to set the ‘sampled_out’ registers at that time.
Once we use the formal tool to run the ordering assertion on varying depths of the FIFO, we see that beyond a certain depth of the FIFO carrying, say, 32-bit data, the proofs do not terminate with a definite pass/fail result, though we can go a lot deeper than anything before. At this stage, we add ‘helper properties’.
We call these helpers ‘invariants’ to distinguish them from our main check. An invariant is usually any property that is valid on all reachable states. However, our invariants are special because they establish the connection between the design and our abstract model built using tracking counters and sampling registers.
The key invariants we deploy in this example follow below. The most important one is the positional invariant, Inv_L5, so let’s explore them in reverse order.
Inv_L5
Positional invariant tells the formal tool where exactly in the DUT the tracked value is. This is calculated as a function of the read pointer (‘rptr’) and the tracking counter. It says that while the watched value is still in the design, it must be at the location pointed to by ‘iptr’:
assert property (sampled_in_d1 && !sampled_out_d1 |-> data[iptr] == d1);
The index ‘iptr’ itself is calculated as:
assign iptr = rptr + tracking_counter_d1 - 1'b1;
Inv_L4
Once the watched data is in the design then the tracking counter is in-between the read and the write pointers.
Inv_L3
Once the watched data is in the design then the tracking counter is greater than zero.
Inv_L2
If the watched data has not entered the design then the counts between the DUT and the abstract model agree.
Inv_L1
If the watched data has not entered into the design then it couldn’t have left it.
Typically, the proof of Inv_L5 is the hardest and that of Inv_L1 the easiest especially as design size grows. We therefore use assume-guarantee reasoning. What we do is to prove invariants with lower indexes first, then assume them to prove the invariants with higher indexes. In this case, the flow would be Inv_L1>Inv_L2>Inv_L3>Inv_L4>Inv_L5.
What is remarkable using these invariants is that the proof times scale linearly with exponential increases in FIFO depth. This is unheard of in any other kind of verification.
The other important point is that on assuming Inv_L5, we can prove the key ordering property in seconds/minutes even for very deep FIFOs.
These results are shown in the graph. You will notice that the proof time for ordering for a 2,048-deep FIFO is less than 20 minutes when running an experiment on a modest machine with 8GB RAM. Not bad for a design with 1019,726 states.
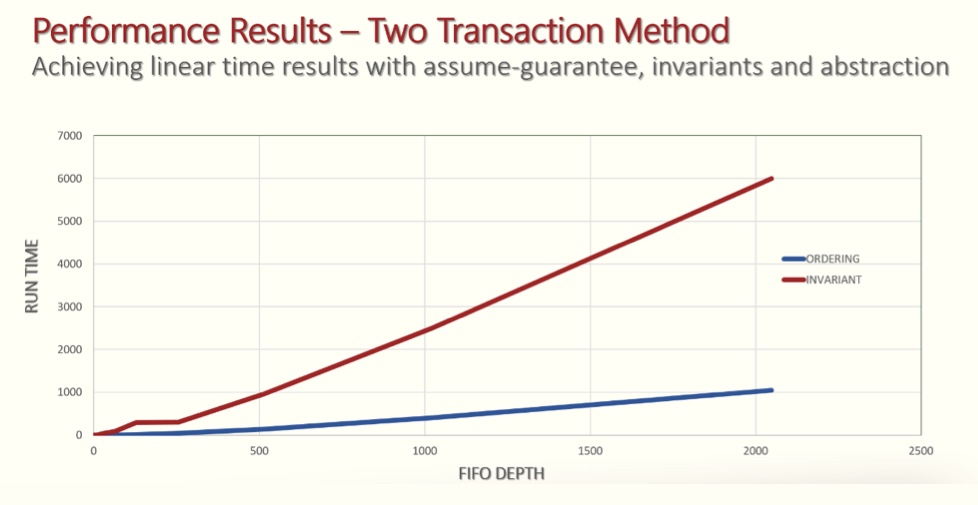
Figure 2. Proof times for experiment with 2,048-deep FIFO (Click to enlarge – Axiomise)
Bug hunting
Now let’s look at using the positional invariant for bug hunting. In most of my work, I have used hand-based mutations to assess the quality of formal verification test benches. In this case, I used the same strategy and systematically went about inserting mutations by hand in all kinds of ways. What I noticed when running the proofs of the positional invariant (Inv_L5) is that it can fail quickly even for very deep FIFOs even running the exercise on a modestly-configured machine with 8GB RAM and a single Intel CPU. The results shown were achieved using OneSpin Solutions’ 360 DV-Verify flow.
The first bug shown manifests when one of the pointers get stuck. Specifically, it is about the read pointer being stuck. When it happens at runtime, the formal tool finds this quickly. The result is shown below for a FIFO with 4,096 entries carrying 32-bit data. This type of fault is common to analyze in the context of safety-critical verification mandated by the ISO26262 automotive functional safety standard.
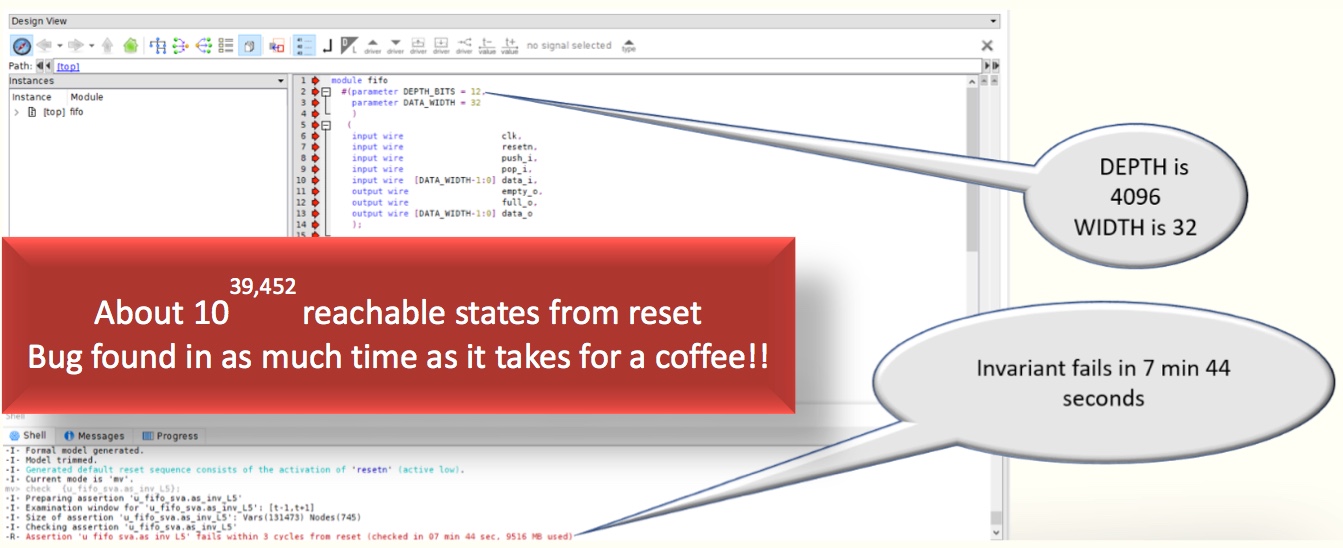
Figure 3. Invariant-based bug hunting – stuck pointer (Click to enlarge – Axiomise)
Let us now look at another type of bug that is difficult to catch in sequentially deep designs and whose occurrence depends upon some random events. In this case, the bug manifests itself when the write pointer ends up being a certain value that is determined by a function of the depth of the FIFO and an occurrence of an interrupt event. When the interrupt (‘intr0’) happens, the data at the location pointed by a value (‘var_l’) is overwritten by an unknown data (Xs in this case).
The value of ‘var_l’ for our example and the specific mutation is shown below.
assign var_l = intr0 ? FIFO_DEPTH/409: FIFO_DEPTH/2;
always @(posedge clk)
if (wptr == var_l)
data[wptr] <= {DATA_WIDTH{1'bx}};
else if (push_i)
data[wptr] <= data_i;
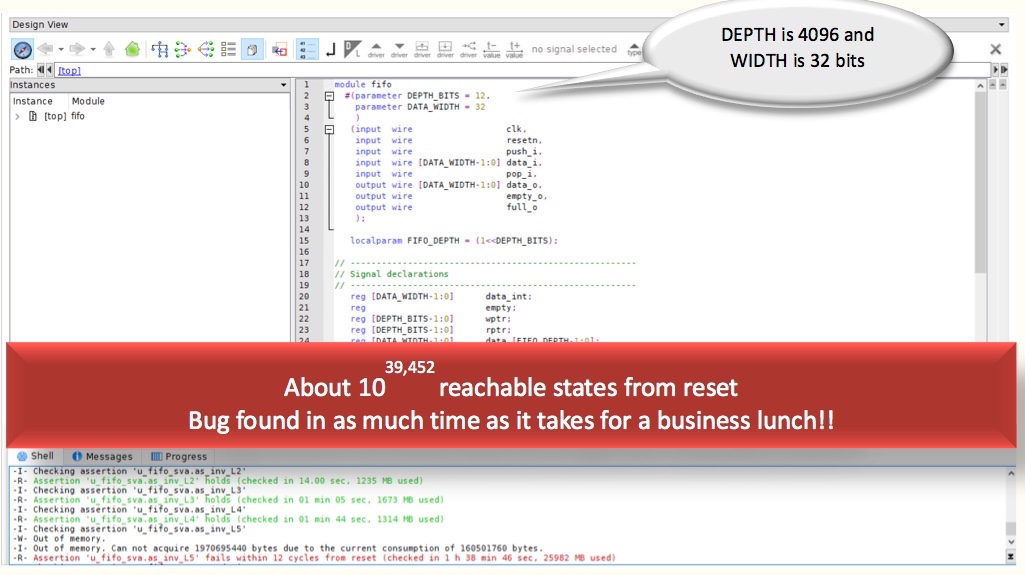
Figure 4. Invariant-based bug hunting – X overwrite (Click to enlarge – Axiomise)
The interrupt ‘intr0’ itself is left floating free and undriven in our design, causing it to be asserted at will by the formal tool. What is interesting when analyzing such bugs with formal is that though the FIFO itself is very deep, the actual detection of this bug takes only about 1 hour 38 minutes. Again, not bad for a design with 1039452 states.
The proofs of L1 to L4 do not take that much time, for this specific configuration it took less than four minutes to prove all the four invariants. Again, this experiment was carried out on a laptop with 8GB RAM running an Intel i5 CPU.
Bug hunting analysis
Formal tools are so efficient at catch such bugs because they tend to find the shortest path to the failure. In this case, it is when the ‘wptr’ is 10. This happens to coincide with the fact that the interrupt is high in the same clock cycle. The formal tool forces the interrupt to go high to fail the assert. Of course, if the depth at which the FIFO gets corrupted gets deep, it will take longer for the tool to find the bug.
What is indeed interesting about this kind of bug is that one can predictably find these despite the size of the design. In fact, run times are linear as FIFO depths increase even for finding such bugs.
So, although the design itself has about 1039,452 reachable states from reset, the formal tool can catch the buggy state in as much time as it takes to have a quick business lunch.
Summary
FIFOs are commonplace in all modern-day chip design. The invariant-based verification technique discussed here is also relevant to other kinds of serial designs. In the past decade, it has already been used to verify big, complex designs such as I2C, many-input arbitration schemes, schedulers, pixel blocks, and packet-based designs commonly found in networking routers.
If you use formal technologies aided with good methodology, then there is a high chance your verification schedule will become predictable, and you will also get higher assurance from the formal tool’s exhaustive analysis. This is something not otherwise possible with any other verification technology and is also the need of modern-day safety and security applications.
For more information, and to learn how to make this happen in your projects talk to us at Axiomise. We regularly run training programs where we teach such scalable formal verification techniques. We can help you sharpen your formal skills and make it possible to apply formal in a predictable and scalable manner.
