Parallel simulation of SystemC TLM 2.0 compliant MPSoCs
Simulation speed is a key issue for the virtual prototyping (VP) of multiprocessor system-on-chips (MPSoCs). The SystemC transaction level modeling (TLM) 2.0 scheme accelerates simulation by using interface method calls (IMC) to implement communication between hardware components. Acceleration can also be achieved using parallel simulation. Multicore workstations are moving into the computing mainstream, and symmetric multiprocessor (SMP) workstations will soon contain dozens of cores. In this context, the centralized scheduler used by the standard SystemC simulation engine has become a bottleneck to parallel simulation.
This article describes two techniques that can help to address this challenge. The first is a general modeling strategy for shared-memory MPSoCs, TLM-DT (transaction level modeling with distributed time). The second is a truly parallel simulation engine, SystemC-SMP. Experiments using a 40-processor MPSoC VP running on a dual-core workstation showed a 1.8X speedup in comparison with a traditional sequential simulation.
Introduction
Even though they are relatively new themselves, multiprocessor system-on-chips (MPSoCs) containing several cores are already being replaced by massively parallel MPSoCs (or MP2SoCs) that integrate potentially hundreds of cores interconnected by a network-on-chip (NoC). The consequent increase in processing power and parallelism has created the need for faster simulation tools for generating virtual prototypes (VPs), supporting functional verification and performance evaluation.
Several industrial and academic frameworks have been used to aid the modeling, simulation and debug of multiprocessor architectures, with the SystemC hardware description language providing their backbone. The SystemC library of C++ classes allows the description of hardware at various levels of abstraction, ranging from synthesizable RTL to transactional-level modeling (TLM). However, as we begin to simulate architectures that contain hundreds of processors, even the simulation speed provided by TLM is not enough.
Meanwhile, although multicore workstations are becoming mainstream and symmetric multiprocessor (SMP) workstations will soon contain dozens of cores, the fundamental SystemC simulation kernel is sequential and cannot fully exploit the processing power provided by this incoming generation of computers.
In response, this article proposes a general modeling strategy for shared memory MPSoCs, called TLM-DT (transaction-level modeling with distributed time), and describes the first implementation of a parallel simulation engine, called SystemC-SMP.
The proposed TLM-DT scheme
TLM accelerates simulations by using interface method calls (IMC) to implement communication between hardware components. Another source of speedup can be exploited through parallel simulation. Anticipating trends cited above in desktop computing, TLM-DT is proposed as a way of continuing to gain these benefits. It is an extension of the work presented in [1].
A SystemC TLM is generally a collection of ‘SC THREADs’ modeling various hardware components in the simulated architecture. These SC THREADs are good candidates to be executed in parallel on the cores of an SMP workstation. The main difficulty with parallel simulation here is that SystemC, like most hardware description languages, relies on the discrete event simulation (DES) algorithm. In most event-driven engines, the simulation is controlled by a central scheduler that contains a list of time-ordered events and a global simulation time. Consequently, in the standard SystemC simulation engine, all SC THREADs are controlled by the same central scheduler, clearly creating a bottleneck for parallel simulation.
Several parallelization techniques have been used to get around this. TLM-DT implements parallel discrete event simulation (PDES) where the system is described as a set of logical processes that execute in parallel and communicate via point-to-point channels. In this approach, there is no longer a global simulation time; rather, each logical process has its own local time and the processes synchronize themselves through timed messages. In a ‘conservative’ PDES, a logical process is allowed to increase its local time only if it has the guarantee that it cannot receive a message on any of its input channels with a timestamp smaller than its local time. This constraint can be violated in an ‘optimistic’ PDES, but a rollback mechanism is needed to restore a process to a previous state in case of violation. This mechanism is expensive and cannot be used for MPSoC projects. To solve this issue, the conservative PDES algorithm uses null messages that contain no data, but only timing information. These null messages must be sent by each process at regular and bounded time intervals to prevent deadlocks.
TLM-DT compliance with TLM 2.0
The TLM-DT simulation models use the generic payload and phase, the initiator and target sockets, and the non-blocking transport functions defined by the TLM 2.0 standard. Although TLM-DT models are compliant with TLM 2.0, shifting from global time to distributed time does introduce some differences.
In TLM 2.0, the synchronization between the hardware components is accomplished by yielding control to the SystemC central scheduler that executes sequentially each process, respecting the general evaluate-update paradigm that is the basis of the DES algorithm. Regarding the time representation, TLM 2.0 suggests two coding styles: approximately timed (TLM-AT) and loosely timed (TLM-LT).
The TLM-AT style is a strict implementation of the DES algorithm. Timed processes (implemented as SC THREADs) are annotated by specific delays, and synchronize with the central scheduler using the ‘wait()’ primitive. Processes are therefore unscheduled at each synchronization point. This allows an accurate description of the timing behavior of shared memory MPSoCs, but the simulation speed can be very low as the number of context switches is very large.
The TLM-LT style supports temporal decoupling, where processes can run ahead of the global simulation time (without unscheduling) for a bounded quantum of time. Transport interface methods are annotated with delays that are interpreted as local time offsets relative to the global simulation time. The style improves simulation speed by reducing the number of synchronization events, but it does not ensure system synchronization.
In TLM-DT, the synchronization between timed processes is no longer centralized in the scheduler, but distributed by annotating all messages with timing information. For this reason, TLM-DT requires its own coding style. Here, each SC THREAD has an absolute local time and sends it as the third argument of the transport interface method. This absolute local time is set to zero at the start of simulation and is increased during it. It can still be interpreted as an offset relative to the SystemC global simulation time because this time is never incremented in TLM-DT. Only three synchronization primitives are allowed: wait(sc event), wait(SC ZERO TIME) and sc event.notify(SC ZERO TIME). Any TLM-DT description can be simulated using standard SystemC and TLM 2.0 specifications, as provided by the OSCI consortium. As illustrated below, dispersion between the various local times is limited, and timing error for a TLM-DT simulation is low (compared to a cycle-accurate simulation), largely thanks to the intrinsic properties of the PDES algorithm.
Components modeling
In most cases, a complex MPSoC is structured in several subsystems (or clusters). Each cluster can contain several initiators, several targets and a local interconnect. A global interconnect manages the communications between clusters. Figure 1 (p. 25) depicts a typical shared memory, clusterized architecture.
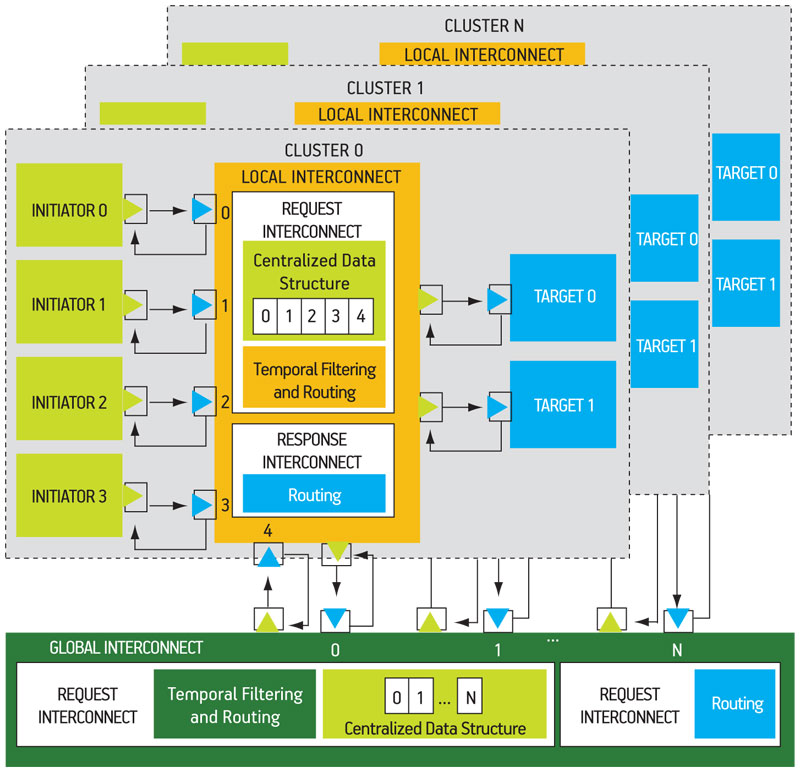
Figure 1
TLM-DT system example
A TLM-DT VCI-OCP initiator contains at least one initiator socket and one SC THREAD. An initiator SC THREAD runs until it reaches an explicit synchronization point or consumes a predefined time quantum. For explicit synchronization (e.g., a memory access), a transaction object is initialized and sent by means of the nb transport fw() method. Later, the corresponding SC THREAD is unscheduled by an explicit wait(rsp event) and waits for the response. When that is received via nb transport bw(), the initiator local time is updated, and the SC THREAD is resumed by a rsp event.notify() primitive.
The local time of an initiator is updated in two cases. First, it is directly increased by the initiator itself (processing time). Second, it is updated with the return time of the nb transport bw method (communication time).
Whenever the local time is updated, the TLM-DT VCI-OCP initiator checks if its time quantum has been reached. If this is the case, it sends a null message with its current local time and is unscheduled.
A TLM-DT VCI-OCP target has at least one target socket and one SC THREAD. A target is reactive. That is, the SC THREAD remains asleep until it receives a request transaction by means of nb transport fw() that executes a req event.notify(). Then the transaction is processed, the target local time is set to the transaction time value, and the response transaction is returned to the initiator by calling the nb transport bw() method.
The local time of a target is updated in two cases. First, it is updated to request transaction time only if this time is greater than the local time (this condition is satisfied when the interval between two consecutive request transactions is greater than the target processing time). Second, it is directly increased by the target itself (i.e., response processing time).
To avoid deadlocks, a TLM-DT VCI-OCP interconnect actually represents two fully independent networks for requests and responses, respectively. The request network is associated with the forward path and the response network is associated with the backward path.
The request network has two functions. First, it performs the conservative PDES algorithm (transactions must be processed in a strictly time-ordered manner). Second, it implements the routing function (the transaction address field is analyzed, and the transaction is routed to the proper target). The request network contains a centralized data structure, called ‘the PDES buffer’, to store the transactions and one SC THREAD. The PDES buffer has a reserved slot for each input channel (one target socket per input channel). When a target socket receives a transaction by means of the nb transport fw() method, it is stored in the corresponding slot. The interconnect SC THREAD is not activated until all slots contain at least one transaction. When this is the case, temporal filtering helps select the request with the smallest timestamp. If the selected transaction is a null message, it is deleted and not sent. In another case, the transaction time is increased by the interconnect latency and the transaction is sent on the correct initiator socket.
In principle, the response network can implement a similar approach to route the nb transport bw() calls. To increase the speed of the simulation, the contention is not modeled in the response network. There is neither SC THREAD nor temporal filtering, and the responses to different initiators can be sent out of order. In the response network, there is only a routing function that analyzes the transaction source identifier field to route the response to the proper initiator.
This modeling strategy supports hierarchical interconnects. In a two-level interconnect, the local interconnect connects the initiators to the targets that belong to the same cluster, and the global interconnect connects the different clusters. Both levels have the same structure and behavior.
When it uses the standard SystemC simulation engine, TLM-DT combines the advantages of the loosely timed coding style (i.e., simulation speed), and the approximately timed style (i.e., high accuracy). But the main advantage of the TLM-DT approach is that it no longer uses the SystemC global simulation time, and it becomes possible to use a truly parallel simulation engine.
Parallel simulation
The main idea of the SystemC-SMP simulation engine is to take advantage of the TLM-DT distributed approach to perform parallel simulation on SMP workstations. SystemC-SMP is dedicated to the TLM-DT coding style and does not require any modification in the simulation models running with the standard SystemC simulation kernel.
From the simulation kernel viewpoint, a TLM-DT platform can be seen as a set of communicating SC THREADs that use sc event objects to synchronize themselves. Regarding the SC THREADs scheduling, neither timed nor immediate notifications are used. This means that the evaluate-update scheduling algorithm is not adapted to the SystemC-SMP parallel simulation kernel.
Simulator software architecture
The SystemC-SMP engine uses a gang-scheduling approach by grouping related neighboring SC THREADs on the same physical CPU of the SMP workstation. Communicating SC THREADs must be executed on the same physical CPU to benefit the cache hierarchy. Moreover, gang scheduling can minimize the bottleneck. This approach can be used because the communication graph is fully determined by the MPSoC hardware architecture and can be statically analyzed by the system designer. The SC THREAD mapping can be explicitly controlled by the system designer through configuration directives that are described below.
The SystemC-SMP software architecture is represented in Figure 2. The TLM-DT VP is the user code after the elaboration phase. It is not part of the simulation engine. The SystemC-SMP kernel is responsible for the creation and termination of simulation objects. It implements shared objects visible to all local schedulers. A local scheduler is responsible for scheduling all SC THREADs that are executed on the same physical CPU. Each SC THREAD is implemented as a QuickThread, as in standard SystemC. The OS kernel is the host kernel that provides a POSIX-thread API. Each local scheduler of SystemC-SMP is executed in a POSIX-thread (pthread) of the host OS. With this software architecture, it is possible to use the CPU-affinity functions provided by the host OS to associate each pthread to a physical CPU. The SMP hardware implements a shared memory and several physical CPUs (with private L1 caches and shared L2 caches).
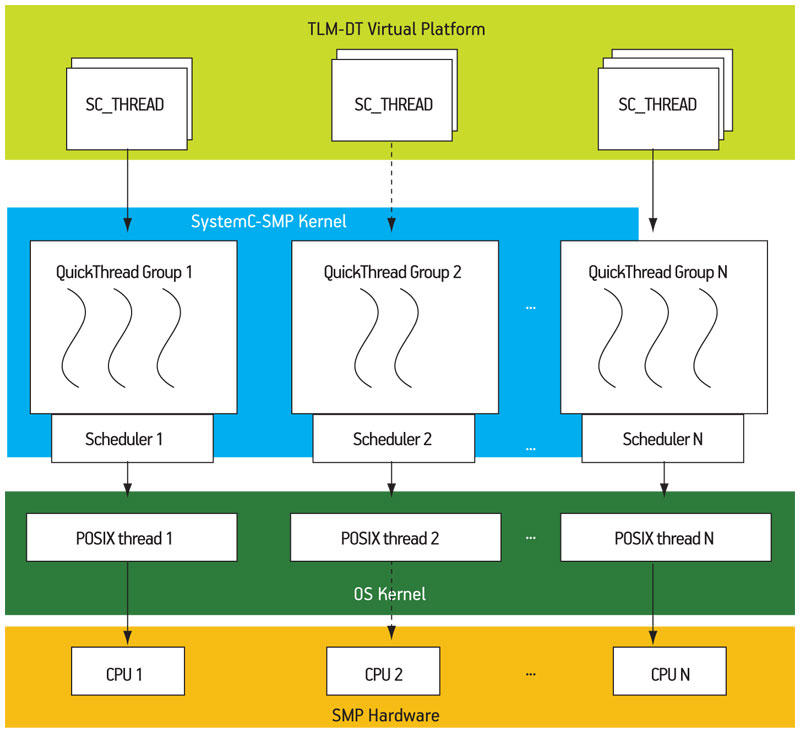
Figure 2
Simulator software architecture
Synchronization
The SC THREADs running in parallel on the SMP workstation use sc event objects to synchronize. As mentioned before, TLM-DT models use three primitives: wait(sc event), sc event.notify(SC ZERO TIME) and wait(SC ZERO TIME). Considering a certain sc event instance named e, two scenarios can occur in a SMP environment.
The first scenario is when e.notify() is executed after wait(e). This is the normal situation where a SC THREAD blocks and yields on behalf of another SC THREAD by calling the wait(e) primitive. It resumes when the e.notify() is called. The second scenario is when e.notify() is executed before wait(e). In this case, the SC THREAD executing the wait(e) must continue its execution without block.
An sc event can be in one of three states: IDLE, WAITING and NOTIFIED. The state of a sc event can be changed by different SC THREADs in the same time, therefore wait(e) and e.notify() have been implemented using atomic test-and-set instructions.
Configuration directives
SystemC-SMP provides a way to bind groups of SC THREADs to a physical CPU using the macro MAP CPU (cpu n, module instance). In this macro, cpu n is a CPU index and module instance is a hardware component instantiated in the simulated architecture (i.e., a sc module instance name). Using this macro, all SC THREADs within a certain module will be mapped to a specific scheduler, and it will be mapped within a CPU with the same index. These configuration macros can be included in the SystemC top-cell, using conditional compilation directives to keep fully compatible with standard SystemC.
Experimental results
Experiments can be broken down under three headings: Embedded Application (EA), Hardware Architecture (HA) and Simulation Engine (SE).
The retained EA is an integer implementation of the Smith-Waterman (SW) algorithm that performs sequence alignment in biocomputing. We used a parallel, multithreaded implementation of this algorithm, written in C language.
The HA is a shared-memory NUMA structured in clusters, as presented in Figure 1. This architecture contains 10 clusters interconnected by a global NoC supporting read/write communication primitives in the shared address space. Each cluster contains four 32bit processors (with data and instruction caches), a local memory and a local interconnect.
Figure 1
TLM-DT system example
The SE corresponds to the physical multicore workstation on which the simulation takes place. The experiments were performed under Linux 2.6.18 on a system equipped with a 2.3GHz AMD Athlon dual core processor with 128KB L1 cache, 512KB L2 cache and 1GB RAM.
The experimental results showed that a speedup equal to 1.9X can be obtained when the performance of the dual-core SystemC-SMP (263 secs) is compared to the single-core Standard SystemC (506 secs), which is very close to the theoretical upper bound given by Amdahl’s law. In order to evaluate the timing accuracy of the parallel TLM-DT simulation using the SystemC-SMP simulation engine, we performed a cycle accurate simulation for the the same EA. The HA was described using the CABA (cycle- accurate, bit-accurate) simulation models available from the SoCLib Project (www.soclib.fr). The cycle-accurate simulation took 68264502 cycles, while the TLM-DT simulation took 64400433 cycles, corresponding to a 6% timing error. The execution time of the cycle-accurate simulation (single-core) was 45X (11980 seconds) slower than for the dual-core SystemC-SMP.
References
1. E. Viaud, F. Pêcheux, and A. Greiner, “An efficient TLM/T modeling and simulation environment based on conservative parallel discrete event principles”, Proc. DATE 2006, pp. 94-99.
2. K. M. Chandy and J. Misra, “Distributed simulation: a case study in design and verification of distributed programs, IEEE Trans. on Softw. Eng, 5(5), pp. 440-452, 1979.
Laboratoire d’Informatique de Paris 6
Université Pierre et Marie Curie
4, Place Jussieu
Paris
France
W: www.lip6.fr