Implementing a unified computing architecture
Netronome offers a range of programmable Network Flow Processors, which deliver high-performance packet processing and are aimed at designers of communications equipment whose requirements extend beyond simple forwarding.
Many network processors and multicore CPUs lack L4-L7 programmability or cannot scale to 10Gbit/s and beyond. Netronome’s flow processors are powered by 40 programmable networking cores that deliver 2,000 instructions and 50 flow-operations-per-packet at 30 million packets-per-second, enabling 20Gbit/s of L2-L7 processing with line-rate security and I/O virtualization. This article describes the tool flow for the development of a high-end application using the processor.
Unified computing architectures (UCAs) bring together networking, computing, storage access and virtualization in systems that aim to streamline data center resources, scale service delivery, and reduce the number of devices within a system that require setup and management. They must deliver powerful packet processing (e.g., thousands of applied processing cycles per packet, and more than 30 million packets per second); high levels of integration (e.g., I/O virtualization, security and encryption); and ease of both implementation and use.
In adopting UCAs, system architects seek to avoid costly, lengthy and risky custom ASIC developments and instead favor merchant silicon providers that offer highly programmable network processors. Such devices give them the ability to develop and deliver innovative, differentiated products while conforming to industry standards—standards that are themselves often in flux. Meanwhile, performance, power and space budgets are fueling the popularity of multithreaded, multicore architectures for communications systems.
Such a range of technologies is encapsulated within our company’s Netronome NFP-3200 processor. Our experience here suggests that comprehensive suites of intuitive and familiar software applications and tools are fundamental to the success of next-generation communications processing projects.
Source: Netronome
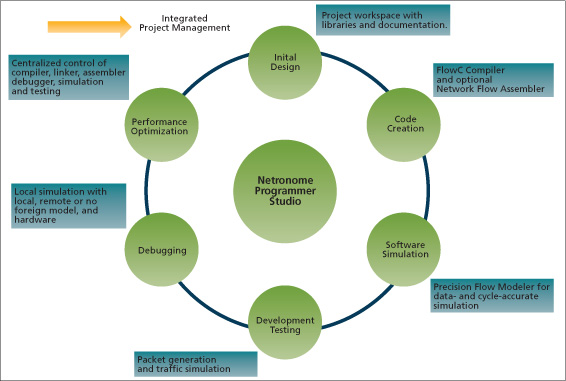
FIGURE 1 Comprehensive tools for all design phases
The application development suites must be based on a familiar GUI and act as the easy-to-use gateway to a software development kit that contain the tools needed for all phases of a project (e.g., initial design, code creation, simulation, testing, debugging and optimization). A command line interface with flexible host OS requirements will speed interactive development tasks. You also need a power simulation environment that allows the software and hardware teams to develop the next-generation platform simultaneously and thereby take fullest advantage of the capabilities available in highly programmable UCAs. Other requirements for effective development that work within this model include:
- The ability to switch between high-level programming languages and assembly code at a very granular level. C compilers provide a familiar high-level programming language with isolation from hardware specifics for faster time-to-market and optimum code portability. Assembly code can also be used to fine-tune portions of an application to maximize performance, and should be embedded in the C code for optimal results.
- The appropriate use of legacy architectures. Architectural choices backed by technologies that can boast years of market leadership and success are inherently both safer and more stable. Such legacy technologies also provide access to and thus take advantage of available pools of talent and experience. Meanwhile, most customers will expect full backward-compatibility with existing architectures.
- A choice of development platforms. Access to multiple development platforms and an ability to debug applications on internally developed platforms will enable accurate simulations of real-world performance in hardware during the system design process.
- Access to advanced flow processing development tools. Cycle- and data-accurate architectural simulations are vital to the rapid prototyping and optimization of applications and parallel hardware/software development. Flexible traffic simulation and packet generation tools reduce testing and debugging time.
Applications enabled by unified computing architectures
Enterprises and service providers alike are using various network-based appliances and probes across a widening range of important activities. These include the test and measurement of applications and services, and deep packet inspection to provide billing, accounting and the enforcement of acceptable-use policies.
These appliances must therefore offer high performance. They must be sufficiently programmable that they can adapt to the evolving networking landscape. And they must have extremely low latency to avoid inserting any delay into applications and services that measure or protect system activity. Simple configurations will not suffice. Evolving standards, government oversight and regulation, and technological innovation require not only UCAs but also powerful and flexible tools that give fast, easy access to those architectures.
Network-based threats, such as spam, spyware and viruses, identity theft, data theft and other forms of cyber crime have become commonplace. To combat these threats, a multi-billion-dollar industry of independent software vendors (ISVs) has emerged. These ISVs provide numerous categories of network and content security appliances such as firewalls, intrusion detection systems, intrusion prevention systems, anti-virus scanners, unified threat management systems, network behavior analysis, network monitoring, network forensics, network analysis, network access control, spam/spyware, web filters, protocol acceleration, load balancing, compression and more.
The ISVs desire tools and software libraries that deliver quick, easy access to the powerful UCAs built for deep packet inspection and the deployment of security applications in increasingly virtualized environments.
Another area where communications equipment manufacturers will see an impact from UCAs is in intelligent network interface cards for virtual machine environments within multicore Intel Architecture system designs by way of virtualized on-chip networks. Today, in single-core systems, an external network provides functions (e.g., VLAN switching, packet classification and load balancing) to direct traffic to one or more systems. As these systems are now combined within a multicore virtualized system, the server’s network I/O facility must provide the same functionality that would previously have been provided externally.
The Netronome Network Flow Processing software development kit (SDK) and related application code enables system designers to take such an integrated approach by employing high-speed network flow processing to intelligently classify millions of simultaneous flows and direct traffic to the appropriate core and/or virtual machine.
While unified computing systems (UCS) are extending to and through 10Gbit/s data rates, their very existence obviates merely configurable architectures, which offer little or no ability to differentiate in services or performance. Purpose-built processors designed to handle the growing and changing needs of UCSs through their programming flexibility and high levels of integration are the only way to achieve maximum performance efficiency. The NFP-3200 has 40 multithreaded packet processing microengines running at 1.4GHz, and in the next section we will use it as an example of how such high performance can be exploited by an appropriate toolset to develop a UCS.
Implementation flow
The NFP SDK provides the tools needed to implement next-generation designs. These are the main steps you would take to develop a UCS.
Source: Netronome
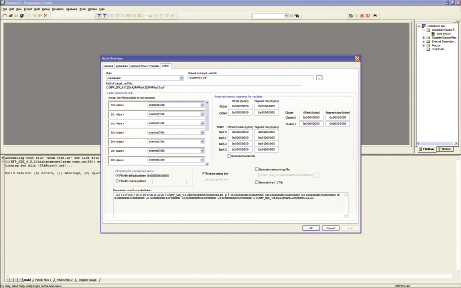
FIGURE 2 The Network Flow Linker interface
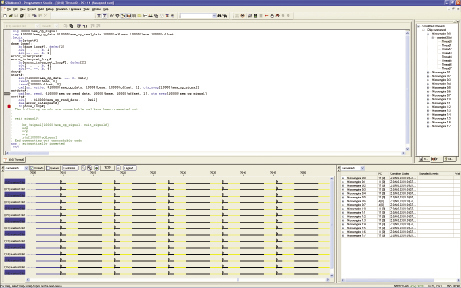
FIGURE 3 The Precision Flow Monitor simulation system
Configuration
The Netronome Programmer Studio is a fully integrated development environment (IDE) that allows for the building and debugging of networking applications on a unified GUI. Its graphical development environment conforms to the standard look and feel of Microsoft Windows, allowing developers to customize the workspace to fit their personal flows and comfort.
To enhance organization and multi-party access, ongoing development settings and files are managed through projects. Most projects are set up in a standard fashion that allows full assemble, compile and build control. There is also the ability to create a ‘debug-only’ project. This allows fast-track enablement to debug functionality on externally controlled projects. The Project Workspace, a window within the Programmer Studio, provides tabs with important project and development related information including a tree listing of all project files; a listing of all the Microengine cores in the NFP-3200 that are loaded with microcode when debugging; a listing of documents included in the SDK; and a tree listing of all microcode blocks that are found when opening a project.
Development
Application development can be broken into six phases: Initial Design, Code Creation, Software Simulation, Development Testing, Debugging and Performance Optimization (Figure 1). The process of architecting a system often entails an iterative series of requirements analysis, estimation (e.g., size, speed, resource cost), proof-of-concept implementation and test. Many blocks of code already exist for standard functions (e.g., packet classification, forwarding and traffic management) and can help during architectural development. In particular, they give an indication of the code and resource footprint for typical functions. This allows developers to focus on innovations that drive value to their users and differentiate the end system. Proof-of-concept and test are mini-develop/debug phases that can be accelerated by using the SDK’s code-building and simulation tools.
Powerful high-level language tools drive rapid code development. The Netronome Flow C Compiler (NFCC) provides the programming abstraction through the C language. It focuses on one given microengine within the NFP-3200, with threading and synchronization exposed at the language level. When a program is executed on a microengine, all its threads execute the same program. Therefore, each thread has a private copy of all the variables and data structures in memory.
The compiler supports a combination of standard C, language extensions and intrinsic functions. The intrinsic functions provide for access to such NFP features as hash, content addressable memory (CAM) and cyclic redundancy check (CRC) capabilities. Developers can configure the NFCC through the GUI or through a command line to optimize their code for size, speed, or debugging at the function level or on a whole-program basis. The compiler also supports inline assembly language, both in blocks and individual lines.
The Netronome Flow Assembler (NFAS) will assemble microengine code developed for the IXP2800 legacy mode or for the NFP-3200’s extended addressing and functionality (a.k.a. extended mode). Like the NFCC, it assembles on a per-microengine basis. Evoking that assembler results in a two-step process: preprocessing and assembly.
The preprocessor is invoked automatically by the assembler to transform a program before it reaches the assembly process, including the processing of files and replacement of certain literals. At this stage, developers can also invoke any or all of the following facilities: declaration file inclusion, macro expansion, conditional compilation, line control, structured assembly and token replacement.
The assembly process includes code conversion, optimization and register/memory allocation.
For single functions or entire applications, ready-to-build code can be partitioned and imaged using Netronome’s Network Flow Linker (NFLD). The NFLD interface allows users to manage the complexity of a multi-threaded, multi-processor architecture within an easy-to-use GUI (Figure 2). The user assigns list files output by the assembler and compiler into each of the microengines within the chip. Various memory reservation, fill options and build options are presented as well.
Debug and optimization
The Programmer Studio is backed by the Netronome Precision Flow Modeler (PFM), a cycle- and data-simulation model of the entire data-plane portion of the chip and its interfaces. Figure 3 shows the PFM in action. In the debug phase of the design, a customer can select and view the code and program counter position for any thread with code loaded in the build system. Using breakpoints is a standard tool for checking for code correctness, and the PFM allows them to be set not only on points in the code being run, but also on changes in internal registers and external memory locations.
In many communication applications, performance efficiency as it relates to power, cost and size are as important as performance. Competitive differentiation is often gained through the ability to apply increasing amounts of functionality to every packet in a high-speed data flow. In these cases, it is desirable to tune application code to maximize performance and functionality in the communications system. Because the PFM is a cycle-accurate simulation, developers can use it to see exactly how well their code is running as written for the NFP without actually loading it on the chip. In addition, Programmer Studio captures code coverage so the user can identify dead and highly executed code in an application. This allows performance improvements and iterative code development in parallel with hardware design and integration. Of specific use to developers in the optimization phase is the Thread History Window (seen at the foot of Figure 3). Color coding of cycle-by-cycle activity on each microengine thread gives a quick visualization of when the microengine is executing code or might be stalled and in need of a software switch to the next context in line. Performance statistics, execution coverage, and an ability to craft simulated customized traffic patterns into the NFP-3200 help developers see hot spots in their code where additional focus would bring performance gains in the application.
Netronome
144 Emeryville Drive
Suite 230
Cranberry Twp
PA 16066
USA
T: 1 724 778 3290
W: www.netronome.com