An industry-as-laboratory approach to dependability for high-tech systems
The dependability of high-volume embedded systems, such as consumer electronics devices, is threatened by a combination of rapidly increasing complexity, decreasing time-to-market, and strong cost constraints. This environment poses challenging research questions that are being investigated in the Trader Project, following an industryas- laboratory approach. This paper describes the vision behind the project and reviews some of the latest results.
High-tech systems are by definition constructed using cutting edge technology. Consequently, embedded systems play a major, often decisive role in such systems today. The integration of embedded hardware and software into much larger systems has reemphasized issues surrounding dependability. Now system dependability is measured not merely by the dependability of individual components within it, but also by the interactions between these components and the overarching environment. Controlling the complexity of these interactions is one of the bigger challenges facing system design today.
This paper describes a model-based approach to system dependability. To date, industrial adoption of model-based design techniques for complex embedded systems engineering has lagged behind that of the academic community. Consequently, research is now following an ‘industry-as-laboratory’ approach. Concrete case studies are used in an industrial context to promote the applicability and scalability of the design strategies they illustrate within relevant and practical constraints.
The case study discussed here is based on collaborative research into high-volume systems involving the Trader Project. Such systems are characterized by the fact that their production in large quantities means that the cost-per-item should be (very) low. This seriously restricts attempts to address dependability issues by classical means (e.g., over-dimensioning critical components). Thus, the project attempts to use concepts from model-based control strategies to achieve that dependability instead.
The Trader Project
Trader is a collaboration between academic and industrial partners to optimize the dependability of embedded systems for high-volume applications such as consumer electronics. Partners are NXP Semiconductors and NXP Research, the Embedded Systems Institute, TASS, IMEC, Twente University, the Technical University of Delft, the University of Leiden, and the Design Technology Institute (DTI) at the Eindhoven University of Technology. The project started in September 2004 and has a fi veyear duration. NXP is the carrying industrial partner (CIP). It provided the initial problem statement and proposes relevant case studies. In Trader’s case, these have been taken from the TV domain.
The problem statement is based on the observation that the combination of increasing complexity in consumer electronics and decreasing time-to-market makes it extremely diffi cult to produce devices that meet customers’ expectations for dependability.
Today’s high-end TVs are complex devices that receive analog and digital inputs from potentially many sources and in many different coding standards. The TV can be connected to various input devices (e.g., VCR, set-top box, DVD player/ recorder, etc.) and has many internal features (e.g., picturein- picture, sleep timer, child lock/TV ratings, programming guide, etc.). There is also demand for features traditionally associated with (or which can be shared with) other device classes (e.g., MP3 playback, USB connectivity, networking, etc.). As a result, the software content of TVs has risen from 1KB in 1980 to 20MB in today’s high-end models.
Hardware complexity is also increasing. There are requirements for the real-time decoding and processing of HD images for large screens and multiple tuners, for example.
To meet hard real-time demands, today’s TVs are designed as systems-on-chip with multiple processors, various types of memory and dedicated hardware accelerators.
At the same time, time-to-market is shrinking. Realizing highly featured products quickly requires the integration of third-party components, particularly given today’s plethora of audio and video standards. Moreover, there is a clear trend towards the use of downloadable components to increase product fl exibility and to allow new business opportunities (e.g., the online sale of features, games or movies).
Given the vast number of possible user settings and input types, exhaustive testing is impossible. Also, the product must be able to cope with certain faults in the input. Customers expect products to cope with deviations from coding standards and poor image quality. Thus, while companies continue to invest a lot of attention and effort in avoiding faults in released products, some further measures are needed if both internal and external issues are not to remain serious threats to dependability.
Trader’s main goal, therefore, is to raise users’ perceptions of dependability for high-volume products by developing techniques that can mask and/or compensate for faults in end products. This needs to be achieved without extending development times, at minimal additional hardware cost and without running any risk of degraded performance. Therefore, classical fault tolerance based on redundancy is not suitable in this case.
We have adopted the terminology used by Avizienis et al [1]. A ‘failure’ is an event that occurs when a state change leads to a run that no longer satisfies the external system specifi cation. An ‘error’ is the part of the system state that may lead to a failure (e.g., a wrong memory value or a wrong message in a queue). A ‘fault’ is the adjudged or hypothesized cause of an error which is not part of the system state (e.g., programming mistakes, unexpected inputs).
Model-based approaches
It is often the case that when a consumer product fails, the user notices that something is wrong but the system itself is completely unaware. Systems are often realized in a way that corresponds to the ‘open-loop’ approach from control theory. For a certain input, a required action is executed, but there is no check as to whether this action has the desired effect on the system or whether the system is still in a healthy state after execution. The Trader Project proposes closing this loop by adding a feedback control to products.
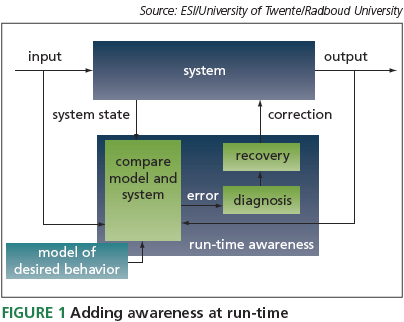
By having the system self-monitor command executions and compare the results against a model for desired runtime behavior, an awareness is introduced such that the system can detect when customer-observed behavior has (or is likely to) become erroneous. Then, the aim is to provide the system with a way of correcting itself. The main ingredients of such an awareness and correction approach are shown in Figure 1 and, maintaining reference to the example of a TV, can be described as follows:
- Observation: observe relevant inputs, outputs and internal system states. For a TV, we may want to observe key presses from the remote control, internal component modes (dual/single screen, menu, mute/ unmute, etc.), loads on processors and busses, buffers, function calls to A/V output, sound level, and so on.
- Error detection: detect errors based on system observations and a model of desired behavior.
- Diagnosis: when an error occurs, fi nd the most likely cause.
- Recovery: correct erroneous behavior, based on diagnostic results and information about the expected impact on the user.
The use of models at run-time is an important part of the strategy. It is not feasible to integrate a complete model of desired behavior into a complex system, however the proposed approach does allow for the use of partial models that concentrate on what is most relevant for the user. Moreover, this approach can be applied hierarchically and incrementally to parts of the system (e.g., third-party components).
Typically, a complex system will have several awareness monitors for different components, different aspects and different fault types.
Kokar et al have observed the analogy between self-controlling software and control theory [2]. Garlan et al developed an adaptation framework where system monitoring might invoke architectural changes [3]. Using performance monitoring, this framework has been applied to the selfrepair of Web-based client-server systems. Related work that also takes cost limitations into account can be found in research on the fault-tolerance of large-scale embedded systems by Neema et al [4]. They apply the autonomic computing paradigm to systems with many processors to obtain a healing network, also using a kind of controller-plant feedback loop. Related work on adding a control loop to an existing system is described in the middleware approach adopted by Parekh et al where components are coupled via a publish-subscribe mechanism.[5]
Current status of Trader
Observation
Both hardware and software techniques are used for system observation. Hardware-related work in Trader currently aims to exploit already available features – such as on-chip debug and trace infrastructure – to monitor values for range checking, call stacks and memory arbiters. The observation of software behavior is mainly done by code instrumentation using aspect-oriented techniques, partly based on results from the ESI’s Ideals project (www.esi.nl/ideals). A specialized aspect-printed framework called AspectKoala has been developed on top of the component model Koala, which is used at NXP.
Modeling desired system behavior
An important part of the model-based approach described in the previous section is the use of a model of desired system behavior at run-time. Such models are, however, usually hard to fi nd. Industrial practices are that system requirements will tend to be described and distributed over many documents and databases. Part of Trader therefore specifi cally addresses the concentration of this information in a single, high-level source.
For the TV case study, a high level mode of the end-product has been developed from the viewpoint of the user. It captures the relation between user input, via the remote control, and TV output, via images on the screen and sound from the speakers. Initial experiments indicated that the use of state machines leads to suitable models for the control behavior of the TV, but also showed that it was very easy to make modeling errors – causes include the fact that there are many interactions between features (e.g., dual screen, teletext, and on-screen messaging can all potentially remove or suppress one another).
To get rapid feedback for the user-perceived behavior and to increase confi dence in the model’s fi delity, Matlab/ Simulink and its graphical extension are used to obtain executable models. Stateflow is exploited for the control part, whereas the streaming part of a TV is modeled by means of the image and video processing toolbox of Simulink. External events can be generated by clicking on an external image of a remote control. Output is visualized by means of Matlab’s video player and a scope for the volume level. This visualization of the user view on input and output of the model turned out to be very useful for detecting modeling errors and undesired feature interactions. Also, we are investigating the possibilities of formal model-checking and test scripts to improve model quality.
Error detection
Various detection techniques are being investigated including hardware-based deadlock detection and range checking. An approach that checks the consistency of internal modes of components turns out to successfully detect teletext problems due to a loss of synchronization between components.
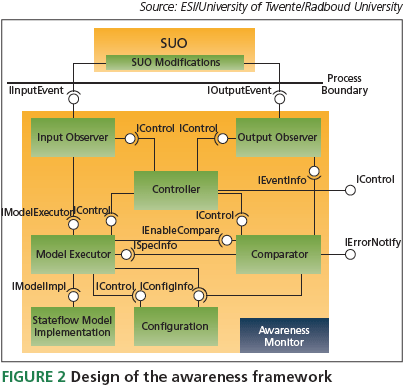
For quick experimentation with model-based error detection, we developed a framework that allowed for run-time execution. It has been implemented on top of Linux because of the trend towards open source software and the increasing use of Linux in TVs. It can include a particular system under observation (SUO) and a specifi cation model of the desired system behavior. Its design is shown in Figure 2.
The SUO and the awareness monitor are separate processes, and Unix domain sockets are used for inter-process communication. The SUO has to be adapted slightly to send messages with relevant input and output events (which may also include internal states) to input and output observers. An executable specifi cation model of the SUO can be included by using the code generation possibilities of The Mathworks tool Stateflow. The generated C code can be included easily, allowing quick experimentation with different models. It is executed using a model executer component, based on event notifi cations from an input observer. Information about relevant input and output events is stored in the configuration component. The comparator component compares relevant model output with system output that is obtained from the output observer. The controller initiates and controls all components except for the configuration component, which is controlled by the model executor.
Experiments with earlier versions of the framework indicated that the comparator should not be too eager to report errors. Small delays in system-internal communication might easily lead to differences during a short time interval. Hence, in the current framework, the user can specify for each observable value: (1) a threshold for the allowed maximal deviation between the specifi cation model and thesystem; and (2) a maximum for the number of consecutive deviations that are allowed before an error will be reported.
Another relevant parameter is the frequency with which time-based comparison takes place. This can be combined with event-based comparison by stating in the model specifi cation when comparison should and should not take place. We have to make a trade-off between taking more time to avoid false errors and reporting errors quickly to allow for timely repair.
In its monitoring of real-time properties, our system bears similarities to the MaC-RT system [6]. However, the main difference between that and the Trader proposed system is that MaC-RT uses a timed version of Linear Temporal Logic to express requirements specifi cations, whereas Trader’s version uses executable timed state machines to promote industrial acceptance and validation.
Diagnosis
Diagnostic techniques within Trader are based on program ‘spectra’ [7]. This approach has been applied in the TV domain. As an illustration, one of the fi rst experiments was conducted on TV software into which a teletext error had been injected.
First, the C code is instrumented to record which blocks are executed. In the example, there were 60,000 blocks. Next, for each sequence of key presses – a ‘scenario’ – we recorded whether the sequence executed or not between two key presses for each block. This provided a vector (or spectrum) for each block.
In the example, it turned out that during a scenario of 27 key presses, 13,796 blocks were executed. Then, based on an error detection mechanism, we recorded whether each press led to an error or not. This gave an error vector of length 27. Then, the similarity between the error vector and the spectra was computed and the blocks ranked according to their similarity.
In the experiment with the teletext error, the block containing the fault appeared at fi rst place in the ranking. Further trials with this technique have been similarly encouraging.
Recovery
Part of the recovery research has focused on load balancing. Project partner IMEC has demonstrated that it is possible to migrate an image processing task from one processor to another and improve overall image quality in the case of an overload (e.g., intensive error correction applied to a bad input).
NXP Research is investigating ways to make memory arbitration more fl exible so that it can be adapted at run-time to deal with problems concerning memory access. The University of Twente has developed a framework for partial recovery, addressing independent ‘recoverable units’. The framework includes a communication manager to control communication between these units and a recovery manager that executes such actions as the killing and restarting of units.
To realize these concepts, a reusable fault tolerance library has been implemented. Initial experiments in the multimedia domain show that after some refactoring of the system, independent recovery of parts of the system is possible without large overhead.
User perception
Project partner DTI is addressing user perceptions of reliability. It aims to understand how users perceive the severity of failures and their resulting irritation. It is undertaking controlled experiments with TV viewers to measure various metrics based on functionality, usage and other factors. Results have thrown up some interesting contrasts. When asked, viewers tend to rank image quality and mechanical features (such as the motorized swivel of the TV) as being of equal importance, but when actual failures occur, show a great deal more tolerance for poor image quality.
Improvements during development
Part of the Trader project addresses achieving improvements in dependability from other sources during the development process. This includes the use of code analysis to prioritize the warnings issued by tools such as QA-C [8] and reliability analysis at the architectural level.
TASS is exploring a stress testing approach that takes away shared resources – such as CPU or bus bandwidth – to simulate errors or the addition of a resource user. The study of such overload situations has proved extremely useful in the TV space with regard to analyzing system behavior and fault-tolerant mechanisms. A so-called ‘CPU eater’, which consumes CPU cycles at the application level in software, is already included in the Trader development software package.
Conclusion
The Trader Project still has some ways to go, but its modelbased approach to system dependability looks very promising. The use of models as system components introduces the capacity for these high volume end products to model and correct their behavior. They illustrate the benefits of a closed-loop, control-based approach to high-tech system design over the traditional open-loop model.
The model-based system is also quite a fl exible approach. One can vary between lightweight models with limited corrective capacities and more elaborate ones with stronger feedback mechanisms. Whichever is preferred, the need to control the overhead is the main constraint on which direction is taken for a high-volume end-product.
This reemphasizes that much more research is needed to gain a more complete understanding of the potential and limitations of the model-based approach across a much greater range of applications.
Nevertheless, the decision to use the industry-as-laboratory model has meant that some of Trader’s intermediate fi ndings and innovations are already fi nding their way into commercial use. We fi rmly believe in the potential of this format to deliver a productive combination of research and innovation. Future Trader activities will continue to address the development of the awareness framework. The Linux-based framework has been validated by means of model-to-model experiments – the comparison of a specifi cation model with code generated from models of the SUO. Currently it is being used for awareness experiments on the open source MPlayer media player. Next, it will be deployed on TVs at NXP. The model-based run-time awareness concept is also being exploited in the printer/copier domain at Oce in the context of ESI’s recently launched Octopus project (www. esl.nl/octopus/).
References:
[1] A. Avizienis, J.-C.Laprie, B. Randell & C. Landwehr, “Basic concepts and taxonomy of dependable and secure computing”, IEEE Transactions on Dependable and Secure Computing. 1(1): 11-33, 2004.
[2] M. M. Kokar, K. Baclawski & Y. A. Eracar, “Control theory-based foundations of self-controlling software”, IEEE Intelligent Software 1999, pp37-45.
[3] D. Garlan, S. Cheng & B. Schmerl, “Increasing system dependability through architecture-based self-repair”, Architecturing Dependable Systems, LCNS, Vol.2677, pp61- 89, Springer-Verlag, 2003.
[4] S. Neema, T. Bapty, S. Shetty & S. Nordstrom, “Autonomic fault migration in embedded systems”, Engineering Applications of Artifi cial Intelligence, 17:711-725, 2004.
[5] J. Parekh, G. Kaiser, P. Gross & G. Valetto, “Retrofi tting automtic capabilities onto legacy systems”, Cluster Computing, 9(2): 141-159, 2006
[6] U. Sammapun, I. Lee & O. Sokolsky, “Checking correctness at run-time using real-time Java”, Proc. 3rd Workshop on Java Technologies for Real-time and Embedded Systems (JTRES ’05), 2005.
[7] P. Zoeteweij, R. Abreu, R. Golsteijn & A. van Gemund, “Diagnosis of embedded software using program spectra”, Proc 14th Conference and Workshop on the Engineering of Computer-based Systems (ECBS ’07), pp213-220, 2007.
[8] C. Boogerd & L. Moonen, “Prioritizing software inspection results using static profi ling”, SCAM ’06: Proc. Workshop on Source Code Analysis and Manipulation, pp149-160, IEEE Computer Society, 2006.
This paper is an edited version of ‘Dependability for hightech systems: an inustry-as-laboratory approach’, which was presented by the authors at the 2008 Design Automation and Test in Europe conference.
Embedded Systems Institute
PO Box 513 Building
LG 0.10 NL – 5600 MB
Eindhoven Netherlands
T: +31 (0)40 247 47 20 |
W: www.esi.nl