Scaling applications from one to eight cores and beyond
Before the widespread adoption of multicore systems, designers had been accustomed to the operating system managing resource allocation. It has been quite a challenge for engineers who now find themselves faced with the prospect of having to take direct control of these management tasks themselves. In response, the Multicore Association has established the Multicore Resource Management API (MRAPI). It provides a system-wide means of managing resources, regardless of the arrangement of OSs on cores.
An embedded system architecture has historically been treated as static. It typically centers around a processor that is supported by memory and peripherals, and interconnected by a bus. Embedded system design then consists of the choice of processor, bus and components. Once that is in place, software can be written for execution on the system.
The static nature of such an architecture helps software engineers because they can make fixed assumptions about the hardware, optimizing accordingly. A software image footprint, for example, can be targeted if there is a known amount of memory available.
Modern embedded systems, however, have become far more complex. This complexity has come in two waves. The first wave was the replication of processors, manifested originally as multiple instances of the same core. This has progressed to the point where sophisticated system-on-chips (SoCs) will have numerous processors, and the processors may all be selected individually for their value in solving specific problems. In such a heterogeneous multicore system, it is possible for all the processors to be different.
Memory and peripherals may also be associated with specific processors or may be shared between many or all of the processors. This complexity means that a programmer cannot be as carefree about writing software without considering the available system resources. In addition, multiple operating system (OS) instances are required, meaning that the software designer may not be able to rely on the OS to manage resources if the required resources are under the purview of a different OS.
Figure 1 shows one example architecture. This system has six processor cores, two of one type, four of the other. The first two are managed together under Linux SMP; the other four are running without an OS (‘on bare metal’). It is not uncommon for some critical functions to be accelerated in hardware and the example shows encryption and decryption, which are implemented in hardware in many chips.
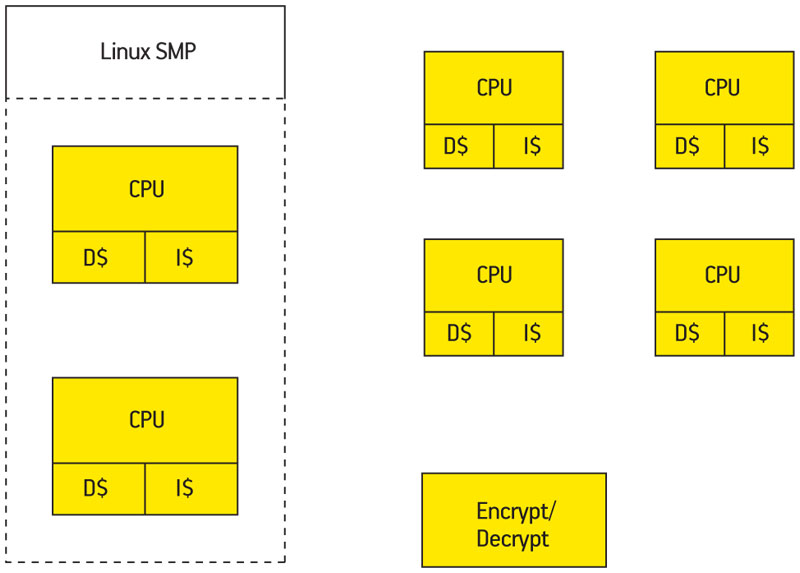
Figure 1
Heterogeneous multicore example
The second wave of complexity goes one step further. In an effort to reduce power, the system may be able to power down various resources when idle. If the main processor has four cores, for example, then in times of low activity, three of those might be powered down to eliminate the power they draw. Therefore the architecture of the system is not only complex, it is also dynamic. It is not enough for software engineers to know which resources have been provisioned: they must account for the fact that those resources may not always be available at any given moment.
Any or all of the cores in Figure 1 could be powered down if activity warrants. Any software relying on things to happen on these cores or on resources controlled by those cores must be able to account for the fact that a desired resource might be powered down, making resource allocation particularly difficult. For an engineer used to letting an OS manage resources, it will come as a rude surprise to have to manage those directly. There has been no standard way of solving that problem. So, in an effort to address it, the Multicore Association has established the Multicore Resource Management API (MRAPI).
Figure 1
Heterogeneous multicore example
MRAPI provides a system-wide means of managing resources, regardless of the arrangement of OSs on cores. It is layered on top of the OSs or hypervisors (or implemented directly on the core for a bare-metal core). It therefore does not bypass the OSs, but uses them when necessary to allocate resources while maintaining a scope greater than what the OS can provide. This ensures that the OSs and MRAPI never disagree on the use and availability of resources.
MRAPI allows software running under one OS to directly access resources unavailable to that OS. At present, these resources consist of synchronization elements and memory.
Synchronization is provided by three elements of increasing complexity.
1. Mutexes provide simple lock/unlock capability and operate close to the hardware.
2. Semaphores allow for lock counting and read/write locks, which allow multiple readers along with a single writer.
3. Memory is supported in two forms: ‘shared’, operating much like POSIX, but across multiple OSs; and ‘remote’, allowing access to private memory that’s managed by a different OS instance (or none at all).
MRAPI also standardizes a system metadata tree describing the resources of the system (where ‘metadata’ is defined as data providing information about one or more aspects of data—in this case, the structure of the system). For many systems, this resource tree would be constant throughout the system’s operation. For a system whose resources may change over time, the resource tree provides a way of knowing what resources exist at any given time. There are at least three ways to keep the tree current: by periodic refreshing; by refreshing before any decision that might depend on the tree; and by using callbacks.
The latter method is specifically provided by MRAPI. A software designer can register system events for callback. This is a highly system-dependent activity: different systems may have different events; some may have none. If a system issues an event when a resource is powered down, the programmer can register a callback for that event. When a resource is powered down, the application will find out about it and can refresh the resource tree to ensure that it is current. Figure 2 (p. 33) provides a simple schematic representation of this capability.
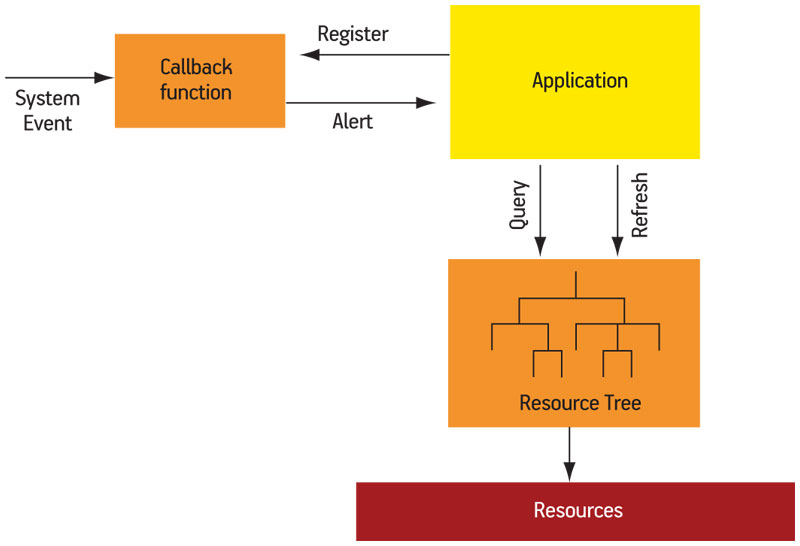
Figure 2
Using callbacks to monitor system events
Designers have broad latitude when building an MRAPI implementation for a given system. The full API must be covered so that any program can compile and run, but individual features can remain unimplemented (though still gracefully handled).
For example, MRAPI provides ways of dealing with dynamic changes to the architecture, but systems having no such dynamic characteristics need not implement them (other than handling any attempts by a programmer to use them). Thread-safety is assumed, but is only necessary in threaded environments, allowing simpler code where possible.
The system designer also has great flexibility in how the resource metadata tree is to be populated. Designers can rely on a static file format, like XML, for a static system; or they can include a means of interrogating the system if it has dynamic characteristics. The intent of MRAPI is to provide a thin, light layer that balances interoperability and portability with minimal implementation requirements.
A packet processing example can illustrate one way in which MRAPI adds value. Packet subsystems are typically structured with a ‘fast path’ or data plane for processing most typical packets, and a ‘slow path’ or control plane for handling management functions and the occasional unusual packet. In order to maximize performance, the fast path cores often run on bare metal. The control plane will typically run under Linux. The architecture of Figure 1 can be used in this example.
Figure 1
Heterogeneous multicore example
Packet processing is usually set up as a pipeline to achieve the greatest throughput. Figure 3 (p. 33) illustrates one such pipeline (with functions labeled generically as F1-F9). Note that most of the packets would be processed by this pipeline, but if F1 detected a management packet or some other unusual situation, it would be sent to the control plane where more sophisticated (but slower) computing would handle the task.
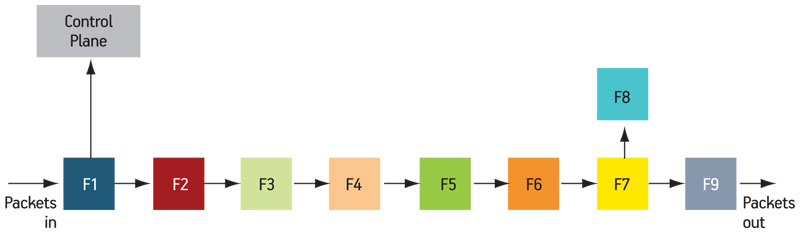
Figure 3
A packet processing pipeline
A software designer would profile the packet processing operation to decide how to partition the different stages and how to allocate resources. Given the pipeline profile of Figure 4, F2 and F4 are clearly hotspots, so parallel instances of each could be created—say, three F2s and two F4s. F1 would handle the load balancing of packets shipped to the F2 instances; similarly, F3 would balance the load to the instances of F4.
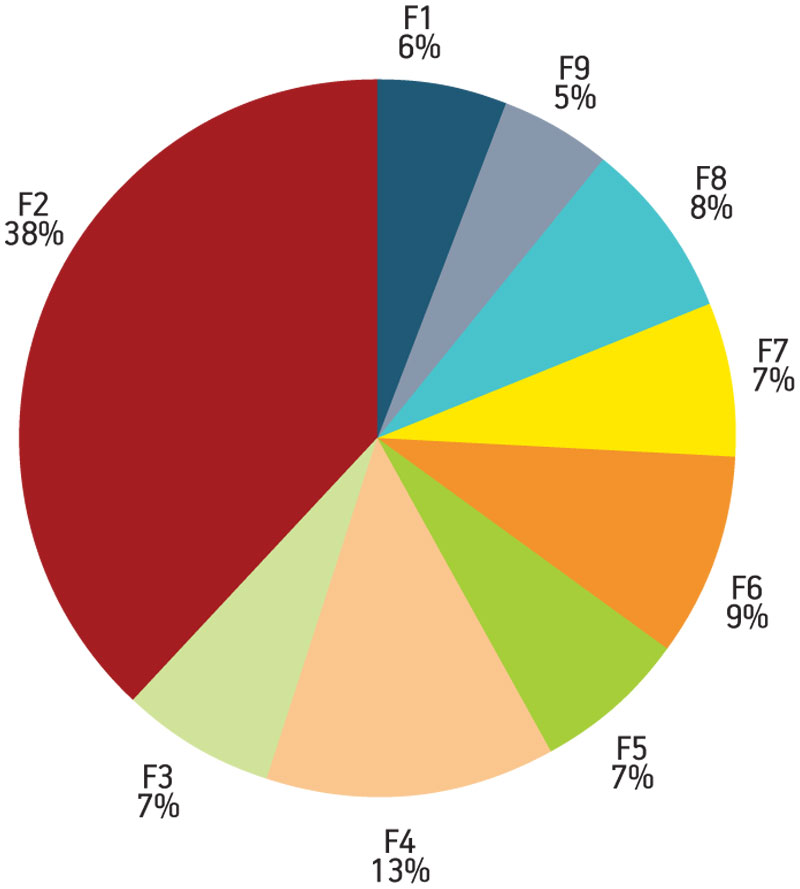
Figure 4
Profile results of the packet processing pipeline functions
Alternatively, if a hardware accelerator were available for the F2 function (say, decryption), then the instances of F2 could be replaced by a single faster hardware version. A mapped version of the pipeline according to this scenario is shown in Figure 5. Note that each of two instances of F4 has its own core; F2 is mapped to the accelerator.
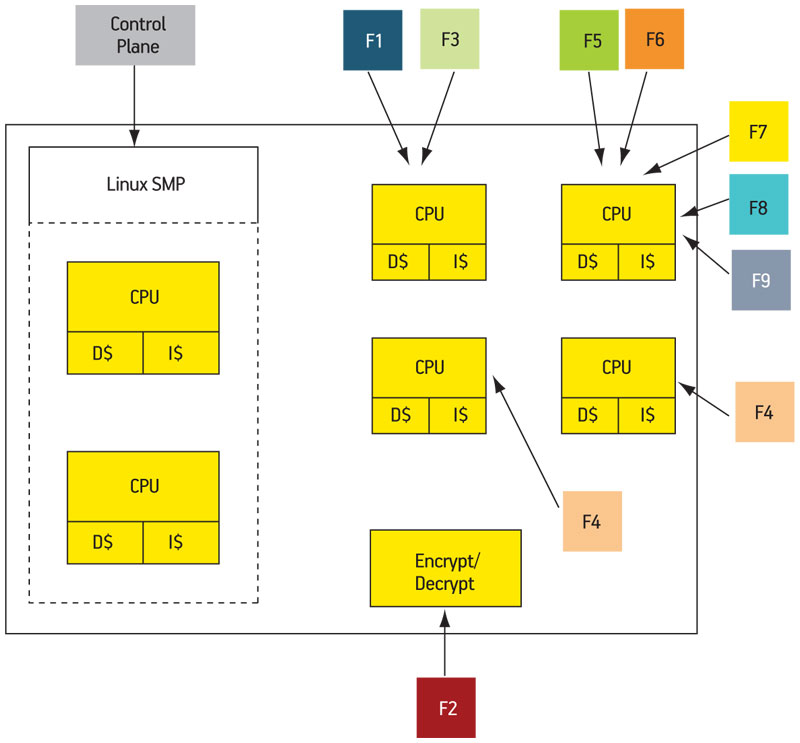
Figure 5
Packet processing pipeline mapped to hardware
If the packet traffic slows so that the parallel instances are underutilized, the system may power down some of the cores, leaving, for example, only one F4 instance. By refreshing the resource tree, F3 can take explicit account of the number of cores available and adjust its load balancing accordingly.
Likewise, it is possible that the accelerator could be powered down. F1 might then be able to run a software version of F2, allocated on another core (which would presumably have more room since this describes a low-traffic scenario). Again, it would be the resource tree that would let F1 make the decision as to how to run F2. Figure 6 shows the re-mapped situation.
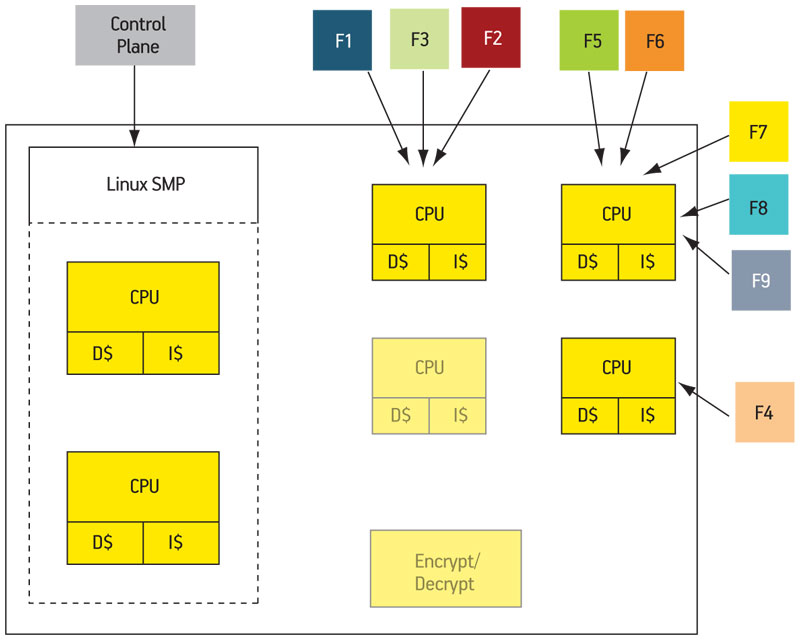
Figure 6
Packet processor remapped with elements powered down
This illustrates a means for strategizing power-down events. The same strategy can be used, however, to write a generic program that is unaware of the number of cores actually being used. The program can then query the actual resources available and set up its load balancing to match the structure available. Such a program would, within reason, be able to scale across a large number of possible core counts. This would be a very system-specific function, since an overall application-dependent mapping strategy would be needed to determine how many resources (and which specific ones) F2 and F4 could commandeer.
These examples show how programs can be written to take account of resources that may scale dynamically in complex heterogeneous multicore systems. All of the tradeoffs and strategies, as well as the means by which they are communicated throughout the system, will be particular to the system, and are not specified in the MRAPI standard. This gives designers a high level of flexibility (including the flexibility not to implement any dynamic features) while providing an underlying standard API that will allow software to be ported successfully across systems having very different hardware details.
The Multicore Association
PO Box 4854
El Dorado Hills
CA 95762
USA
T: +1 530 672 9113
W: www.multicore-association.org