NoC-MPU: a secure architecture for flexible co-hosting on shared memory MPSoCs
Data protection has long been a major issue for embedded systems, but it is becoming even more challenging with increasing adoption of multicore technology.
The processors in these systems are often heterogeneous, which prevents deployment of a common, trusted hypervisor across all of them. Multiple native software stacks are thus bound to share resources without protection operating across them. NoC-MPU is a memory protection unit (MPU) designed to support the secure and flexible co-hosting of multiple native software stacks running in multiple protection domains, on any shared memory multiprocessor (MP) system-on-chip (SoC) using a network-on-chip (NoC).
For many embedded systems, especially those handling protected content, data protection is a major issue. Only a few years ago, bi-partitioning techniques were considered sufficient. For example, ARM had the TrustZone feature, which allowed a ‘secure world’ to live alongside a ‘non-secure’ one. Nowadays though, such binary co-hosting does not meet emerging security requirements and challenges.
For example, recent consumption models promote the convergence of traditional video and Internet-based content. This leads to a significant increase in security complexity. Devices such as set-top boxes today provide a multitude of services (e.g., user interface, conditional access, digital rights management, personal video recorder, etc).
Each service finds its physical representation in a mixture of hardware and software components, ranging from small security-critical software stacks running on basic processors or accelerators, up to commodity OSs on complex application processors. Although these highly heterogeneous software stacks each contain internal sensitive information that must be protected, all of them also need to collaborate.
A. Co-hosting and virtualization
New techniques are emerging to co-host multiple native software stacks in parallel and to transparently partition available platform resources among them. First intended for mainframe servers and later for desktop systems, virtualization is now reaching embedded systems. Existing pure software approaches rely on the use of a memory management unit (MMU) to set the barriers between native software stacks, but this technique is soon expected to be superseded by dedicated virtualization hardware support within embedded processors.
In both cases, isolation is always achieved at the processor level. This processor-centric property makes the sharing of processing and memory resources efficient on symmetric multiprocessor architectures that can be controlled on a common trusted basis (e.g., a virtualization hypervisor). However, it is not efficient for heterogeneous multiprocessor shared-memory embedded systems-on-chip (MPSoCs).
To offer one example, multimedia-oriented MPSoCs are often composed of a small number of general purpose processors, assisted by specialized programmable processors and dedicated coprocessors that frequently have direct memory access (DMA) capability. The specialized programmable devices and coprocessors cannot support virtualization since they are mostly MMU-less, and sometimes do not even offer inherent ways of establishing several privilege levels.
Setting up a common trusted platform for such heterogeneous systems is difficult as long as, for example, a software stack running on a specialized processor is able to access the whole address space, bypassing completely any virtualization layer.
B. Software stacks and protection domains
As described by Porquet, Schwarz and Greiner [1], MPSoC heterogeneity must be addressed by a platform-global protection mechanism, covering the full communication infrastructure, instead of a processor-centric mechanism. We define such a protection domain as a set of specific access rights to a shared address space. We assume that each software stack is running in a specific protection domain, with rights-overlaps possible between them. Figure 1 illustrates the ideal co-hosting of several protection domains where software stacks transparently share all the platform’s resources: memory, processing, and peripheral resources.
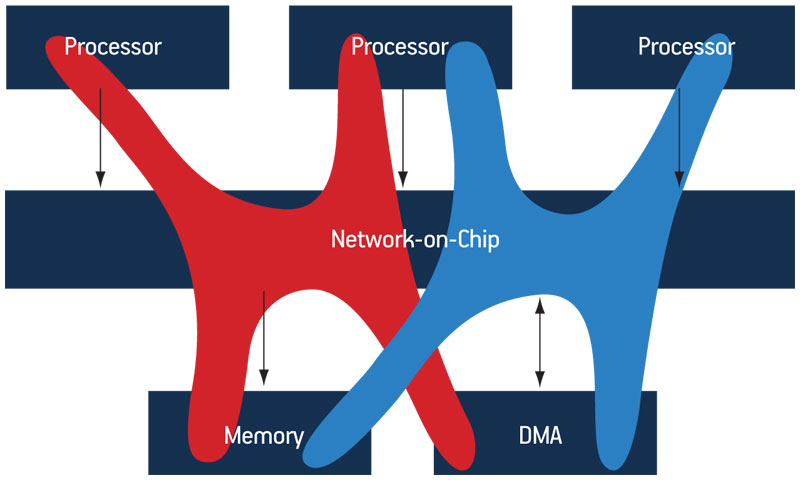
Figure 1
Co-hosting of protection domains, sharing processing and memory resources as well as a DMA device
Source: LIP6/STMicroelectronics
As a given initiator device (e.g., processor or coprocessor) can be working for various software stacks, a global protection mechanism requires that all transactions released by that initiator are tagged by an identifier defining which software stack is issuing the transaction. This information is already supported by standard communication protocols: The Virtual Component Interface (VCI) standard from the VSI Alliance and the Open Core Protocol (OCP) from the OCP-IP Alliance respectively define the TRDID field and the MThreadID field. While they have been specified to support—out-of-order—simultaneous transactions issued by multi-threaded processors, they can be used to tag the transactions with a ‘protection domain identifier’.
In this context, we base ‘multi-protection-domain’ capability on an initiator device that can tag the transactions with a protection domain identifier. We then assume that all initiator devices in the platform have this multi-protection-domain capability.
Porquet et al [1] also introduced the concept of a global architecture mechanism to support the secure and flexible co-hosting of multiple software stacks running in multiple protection domains. This paper proposes a possible hardware/software implementation of this mechanism called NoC-MPU (Network on Chip with Memory Protection Unit) that can be used in any shared address space MPSoC using a NoC.
Related work
NoC technology has been widely studied during the last decade, but the security aspects of such architectures have only recently come under close scrutiny.
Diguet et al [2] may have been the first work to tackle the idea of directly integrating a security mechanism with the NoC. The proposed mechanism checks the transactions between physical devices, authorizing them only if they comply with a predefined configuration (e.g., a given processor is allowed to access a given memory bank). As a result, the granularity of the access control is defined by the hardware device. This static assignment does not support different access rights to memory areas within the same physical memory bank. Besides, this filtering method is also incompatible with co-hosting, where several protection domains are able to share the same initiator devices.
Fiorin et al [3]–[5] proposed a solution for data protection in MPSoC architectures based on NoC technology. Their secure NoC architecture is composed of a set of data protection units (DPUs) implemented within the network interface controllers (NICs). The DPUs can check and limit the access rights of initiator devices accessing various regions in a shared address space (e.g., a given processor is allowed to access a certain address region) with no performance overhead. The access rights are defined for each physical device, except for processors where the DPU can actually distinguish between the two operating roles (kernel/user). However, this is not sufficient to support several protection domains sharing the same processing resources. Finally, the DPU implements a segmentation approach without any caching mechanism: the access rights tables are directly embedded within the DPUs. It seems difficult for this strategy to support the flexible co-hosting of multiple protection domains potentially requiring access to multiple memory regions, since the access rights tables would be too large.
The NoC-MPU approach
We will now describe the hardware/software architecture of the proposed memory protection unit (MPU) for NoC-based architectures, which is itself the key to supporting a flexible co-hosting of several protection domains on a multiprocessor platform.
For the purpose of this discussion, we use the term ‘compartment’, as introduced in [1], to refer to a software stack associated to a protection domain. The compartment identifier (CID) allows the association of any transaction issued by a multi-protection-domain device with the corresponding compartment.
A. Principle of operation
Protecting compartments from one another means actually preventing the misuse of elements such as their code, data, and exclusive access to peripheral devices. In a shared address space architecture, these assets typically address regions accessible through read or write transactions in that space. Therefore, the access control must define a set of access rights on various address regions for each compartment. When a compartment is executing on a processor, the CID information is attached to each transaction. Isolation is achieved in the NoC by checking all the transactions against the set of access rights defined for this CID. As a result, the granularity of the access control becomes the compartment—a flexible, logical construct—instead of a physical device.
As illustrated in Figure 2 (p. 25), the MPU is a hardware module embedded in the NoC, supplying services similar to those offered by a firewall in local area networks.
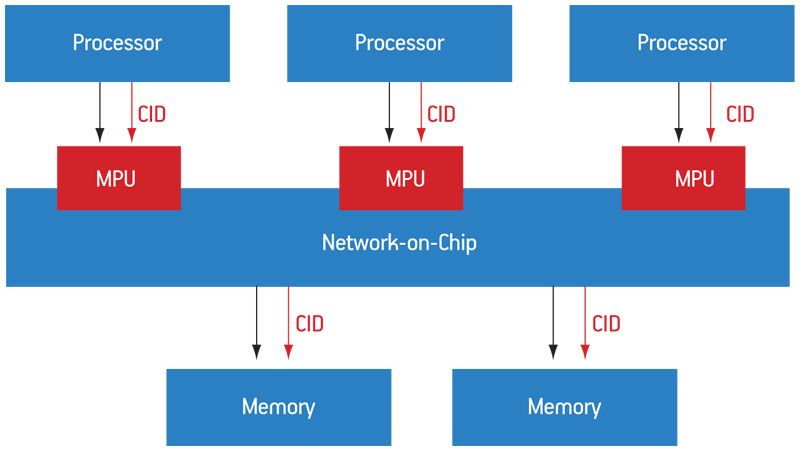
Figure 2
Example of a NoC-based architecture equipped with MPU modules
Source: LIP6/STMicroelectronics
The filtering algorithm performed by the MPU is defined by a permission table, indexed by the memory address of a transaction request and its associated CID, and containing the access rights for each combination of these two entries. To provide for a large number of compartments, sharing the same address space with different access rights, this table cannot be stored within the MPU (contrary to the DPU mechanism [3]), but in the memory. On the other hand, the permission table must be stored in on-chip memory, for both performance and security reasons. Similar to a standard MMU, the MPU module contains a small cache (called the ‘permission lookaside buffer’, or PLB) and a dedicated finite state machine (FSM) to fetch the required entry from the permission table in case of a PLB miss.
As shown in Figure 3, each new transaction triggers a PLB look-up. Depending on whether the PLB contains the permission information for the interrogated pair (address, CID), the transaction is granted or denied accordingly. Otherwise, the hardware FSM accesses the permission table in memory, located at the address hold by the permission table base, and refills the PLB with the missing information.
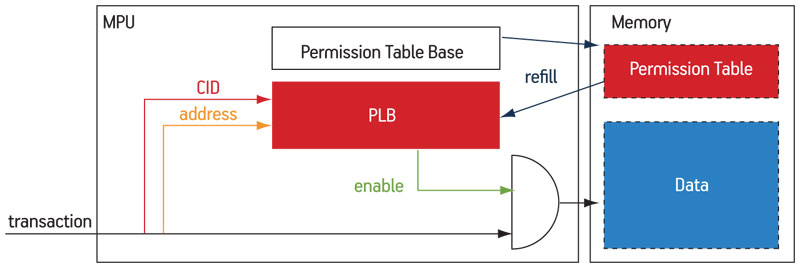
Figure 3
Abstract architecture of the MPU module
Source: LIP6/STMicroelectronics
Witchel et al [6] discussed alternative layouts for the permission tables. The two basic approaches are segmentation and pagination.
In the segmented approach, the permission table is a linear array of segments ordered by segment base address. Although this method supports variable segment sizes, the lookup time can be extremely long, as well as that for the update, whenever the number of segments is too high. We preferred the paginated approach, where the address space is decomposed in fixed size pages, and the access rights are defined for each page. The worst-case lookup is deterministic and the management is quite straightforward.
The location of the MPU modules in the platform is relevant. The major advantage of locating them at the initiators’ side is that these input modules are able to prevent a denial-of-service attack, where an initiator device tries to saturate the NoC by performing massive unauthorized accesses.
B. Hardware architecture
The proposed MPU module has been implemented in the DSPIN NoC [7], a packet-switching micro-network dedicated to shared memory multiprocessor architectures. Nevertheless, it could be embedded in any existing NoC supporting read/write transactions in a shared address space.
As shown in Figure 4 (p. 26), the architecture has a flat mesh topology: one single device (initiator or target) is connected to each NoC router, via a NIC. The NIC is in charge of adapting the packet-based DSPIN protocol to the device protocol (VCI/OCP in our implementation). Two types of NIC exist: one where a NIC connects an initiator device (NIC/I) and the other where it connects to a target device (NIC/T).
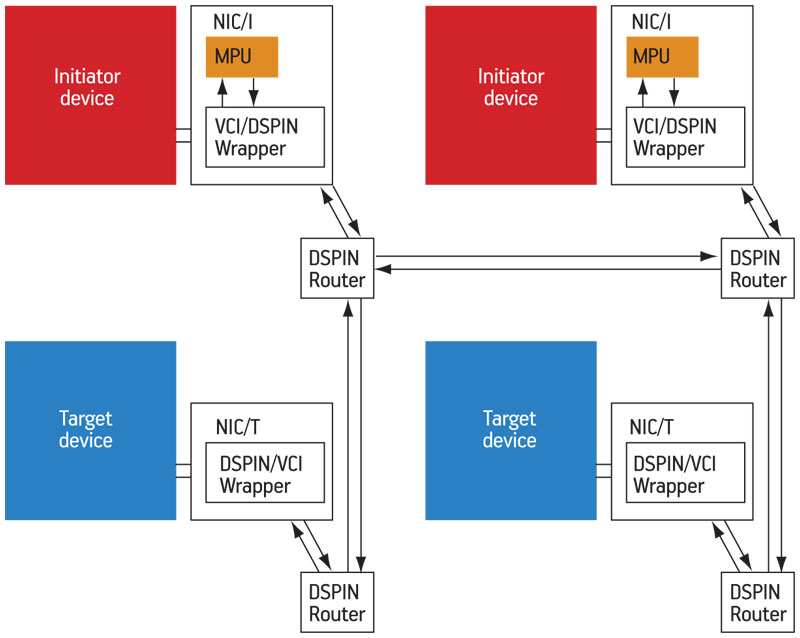
Figure 4
DSPIN-based architecture with MPUs embedded in NICs
Source: LIP6/STMicroelectronics
The MPUs are embedded inside NIC/I types, and work in parallel with the protocol conversion. The permission table is implemented as a hierarchical, two-level page table. There is one table per compartment. The page size is 4KiB (12-bit), and the 20 most significant bits (MSBs) of the address are used to index the page table (10-bit for each level).
As shown in Figure 5 (p. 27), we use three VCI/OCP signals to access the PLB and check the access rights: the transaction is defined by both the compartment identifier (CID, contained in the VCI/TRDID field), and the 20 MSBs of the VCI/ADDRESS field. Both types of information are looked up and access rights for read (R) and write (W) operations are supplied as output of the PLB. The VCI/CMD finally allows the system to check the transaction and to let it pass through the network or not.
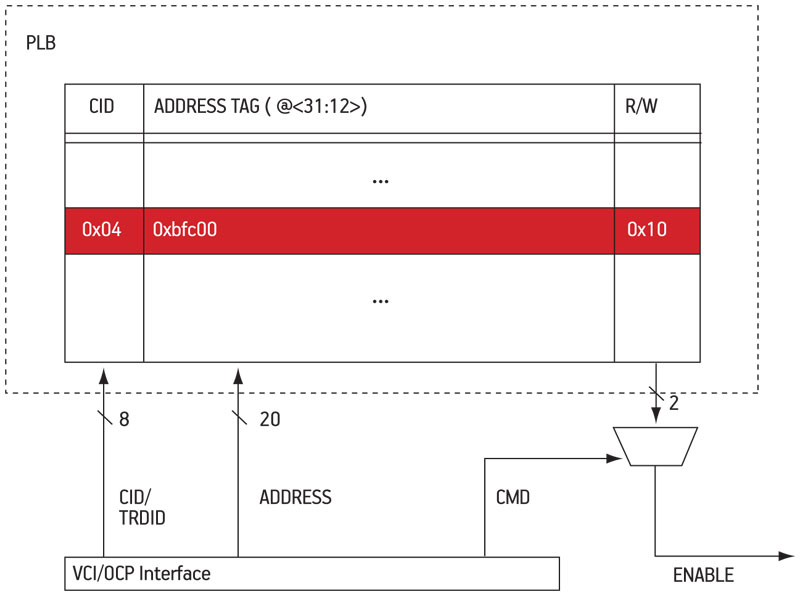
Figure 5
Internal architecture of the PLB
Source: LIP6/STMicroelectronics
Whenever the PLB does not contain the access rights corresponding to the current transaction, the hardware page ‘walk’ FSM supersedes the protocol conversion to retrieve the information in memory (Figure 6). A buffer of page directory pointers is indexed by the CID field to get the base address of the page directory associated to the compartment that issued the request. The 10 MSBs of the 32-bit address are used as an offset to find, in the first-level page directory, the base address of the second-level page table. The second-level page table is then accessed, using the next 10 address bits as an offset to find the access rights information (2-bit). This information is retrieved within the MPU, and added to the PLB, which can be consulted again for checking the access rights of the current transaction
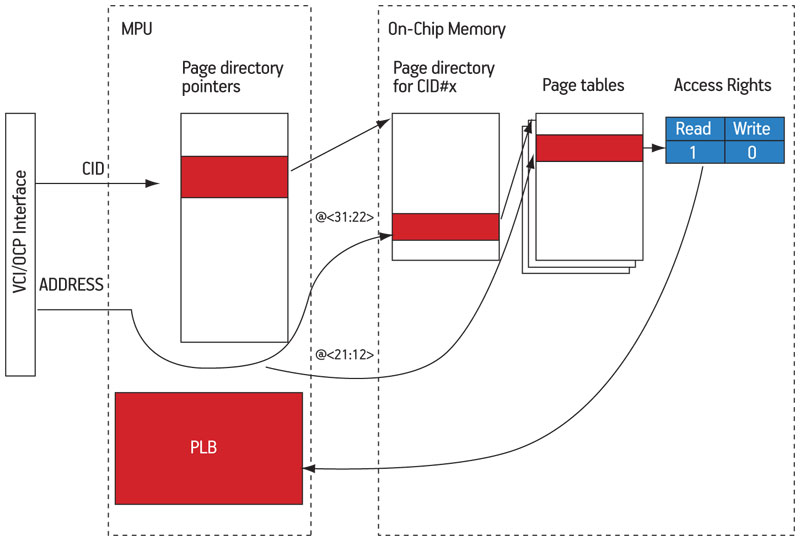
Figure 6
Hardware page walk mechanism
Source: LIP6/STMicroelectronics
The MPU performs these two memory accesses by reusing the same physical identity as the initiator device that issued the transaction (i.e., the device attached to the given NIC/I). The MPU then intercepts both responses when they come back via the NIC.
Since protocol conversion and MPU access are performed in parallel, embedding the MPU within the NIC ensures that no additional latency is provoked for PLB hits. A miss in the PLB, however, causes the transaction to be temporarily frozen while the PLB is refilled, which can increase the average latency.
C. Software architecture
The NoC-MPU protection mechanism nicely fits in the layered trust model proposed in the multi-compartment approach. Multi-protection-domain programmable processors are each locally managed by a software local trusted agent (LTA). The LTA is in charge of updating a range of CID values for both itself and the compartments (i.e., applications) running above it. The LTA itself is considered a compartment with additional privileges.
This local management is complemented by a global trusted agent (GTA), acting platform-wide. The GTA handles the creation/destruction of compartments and supervises the shared address space partitioning among them, particularly through on-the-fly definition of page tables. It also configures the different MPUs (i.e., the initialization of directory page pointers) based on the memory-mapped interface each MPU presents. The GTA typically receives and handles violation events (in the case of unauthorized accesses), which can be signaled by software interrupts.
This protection scheme enables the support of complex software architectures. For example, a standard hypervisor controlling several virtual machines on a general purpose processor and a real-time OS running user applications on a specialized processor can both act as LTAs. Both can schedule their user software stacks according to their policies and update respective CID values. Indeed, a software stack running on a dedicated processor can act as the GTA to administer the whole platform.
Conclusion
NoC-MPU is a novel, flexible, and adaptive solution for the secure co-hosting of several protection domains (‘compartments’) running concurrently on a shared memory MPSoC. The hardware module embedded in the NICs allows for a flexible partitioning of the shared memory address space among multiple compartments. The trusted software model then fits closely to this hardware protection scheme.
This complete hardware/software secure architecture is currently being implemented. First results concerning the performance overhead (i.e., due to PBL misses of the hardware protection modules) are encouraging, as are those for the silicon area overhead of the hardware modules.
The next logical step will thoroughly characterize this performance overhead, evaluating typical execution scenarios. This involves benchmarking applications on multiple compartments and measuring the silicon overhead after synthesis of the hardware modules.
References
[1] J. Porquet, C. Schwarz, and A. Greiner, “Multi-compartment: a new architecture for secure co-hosting on SoC”, SOC’09: Proceedings of the 11th International Conference on System-on-Chip, Piscataway, NJ, IEEE Press, 2009, pp.124–127.
[2] J.-P. Diguet, S. Evain, R. Vaslin, G. Gogniat, and E. Juin, “NOC-centric Security of Reconfigurable SoC”, NOCS ’07: Proceedings of the First International Symposium on Networks-on-Chip, 2007, pp.223–232.
[3] L. Fiorin, G. Palermo, S. Lukovic, and C. Silvano, “A data protection unit for NoC-based architectures”, CODES+ISSS ’07: Proceedings of the 5th IEEE/ACM International Conference on Hardware/software Codesign and System Synthesis, New York, NY, ACM, 2007, pp.167–172.
[4] L. Fiorin, G. Palermo, and C. Silvano, “A security monitoring service for NoCs”, CODES+ISSS ’08: Proceedings of the 6th IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, New York, NY, ACM, 2008, pp.197–202.
[5] L. Fiorin, G. Palermo, S. Lukovic, V. Catalano, and C. Silvano, “Secure Memory Accesses on Networks-on-Chip”, IEEE Trans. Comput., vol. 57, no. 9, pp.1216–1229, 2008.
[6] E. Witchel, J. Cates, and K. Asanovi?, “Mondrian Memory Protection”, ASPLOS-X: Proceedings of the 10th International Conference on Architectural Support for Programming Languages and Operating Systems, 2002, pp.304–316.
[7] I. M. Panades, A. Greiner, and A. Sheibanyrad, “A Low Cost Network- on-Chip with Guaranteed Service Well Suited to the GALS Approach”, First International Conference on Nano-Networks (Nano-Net), 2006.
Acknowledgments
This work has been carried out in the framework of a cooperation between UPMC/LIP6 and STMicroelectronics.
Laboratoire d’Informatique de Paris 6
Université Pierre et Marie Curie
Maison de la Pédagogie
Place Jussieu
75005 Paris
France
T: +33 (0)1 44 27 70 15
W: www.lip6.fr
Nagravision
Case Postale 134
Route de Genève 22
1033 Cheseaux
Switzerland
T: + 41 21 732 03 11
W: www.nagravision.com