Hypervisors and the Power Architecture
The use of multicore processors is on the rise to meet inexorable demand for increasingly sophisticated functionality in embedded systems. Hardware virtualization technology provides a complementary and game-changing approach to maximizing the utility of that extra silicon horsepower.
The Power Architecture has included hardware virtualization support since 2001 in its server-based instruction set architecture (ISA). Last year’s launch of ISA 2.06 saw virtualization added for use in general-purpose embedded processors. This paper describes the hardware and software capabilities behind embedded virtualization for Power Architecture-based systems.
Multicore partitioning
To capture theoretical multicore processor performance gains, the first obvious approach is to use fine-grained instruction-level or thread-level parallelism. This has been the subject of years of research and investment, covering such techniques as parallelizing compilers, parallel programming languages (and language extensions, such as OpenMP), and common operating system (OS) multithreading. But this work has had limited success in unlocking the full potential of multicore horsepower.
Embedded system architectures in the telecommunication, networking, and industrial control and automation segments are already naturally partitioned into data, control and management planes. This separation has driven interest amongst OEMs in ways of mapping an entire system to a multicore system-on-chip (SoC) that simply integrate formerly standalone functions on a single device.
Such consolidation has many practical advantages, including minimizing the impact on the software architecture. After an entire system has been moved to a single multicore device, optimizations of coarse-grained parallelism can be applied gradually over time.
Another important enhancement has come in the partitioning and virtualization of system resources to minimize redundant hardware through consolidation. Multicore SoCs in the embedded space typically include a wide variety of hardware resources (e.g., processors, memory controllers, application accelerators and external I/O interfaces). Partitioning combines these resources to support various application requirements. Hardware is allocated to partitions as either shared or dedicated resources. A partition can contain one or more cores. Within each partition, software handles a particular function. This software can range from a single software program to a complete OS and all of its constituent programs.
A partition is more than just a group of resources available to applications. Partitioning implies a level of separation and protection that ensures software and hardware in one application domain cannot interfere with the operation of other domains. Partitioning often enables some higher-level features, such as initializing and restarting software in one partition while another continues to operate normally.
The consolidation of subsystems into a single robust system depends on the ability of the hardware and system software to enforce protection capabilities and faithfully reproduce previously discrete implementations in new virtual embodiments. For example, a networking device can use partitioning to sandbox a management plane Linux OS from high-criticality applications running in the data plane.
System virtualization
System virtualization is the process of emulating (or abstracting) a computer system (e.g., processor, memory and peripherals). The abstracted system is called a virtual machine (VM). A single VM runs on a single logical partition. Within each logical partition are some memory, one or more cores and a collection of accelerators and I/Os. Each resource may be actual dedicated hardware or be implemented in partially or completely virtualized hardware. It is not uncommon for a system to include more VMs than available cores.
A hypervisor is a low-level software program that presents and manages one or more VMs, scheduling them across the available cores. It appropriates the role in SoC hardware management traditionally relegated to the OS, pushing it up into the VM. OSs running in VMs are called guest operating systems, and they are permitted to access resources at the behest of the hosting hypervisor. An example of a hypervisor-partitioned multicore system is shown in Figure 1.
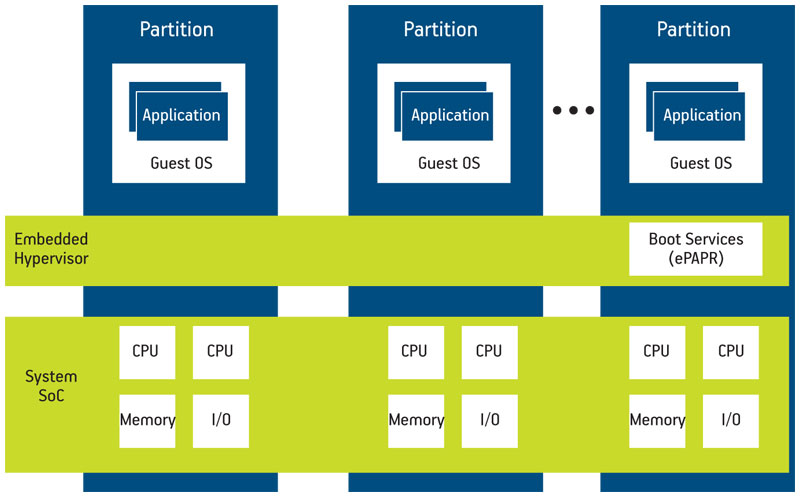
Figure 1
Multicore system virtualization
In addition to the flexibility and reduced size, weight, power and cost afforded by consolidating workloads and discrete computing elements, hypervisors also add security, protection and system management features. For example, sandboxing a less trusted OS or an externally visible management interface web server could substantially improve the robustness of a system.
I/O virtualization
I/O virtualization is a critical hypervisor function. Many embedded systems have stringent performance and/or latency requirements for I/O and thus are sensitive to any degradation resulting from virtualization. There are several ways to virtualize I/O devices.
A device may be fully emulated. Here all accesses to the virtual device by the guest are intercepted by the hypervisor, which then validates the I/O request and converts it to an actual hardware I/O operation. Emulation is sometimes required to share a single physical peripheral across multiple VMs. For example, two VMs can share a single physical Ethernet device if the hypervisor implements a virtual Ethernet device in each VM and performs the required packet switching between the physical and virtual interfaces. The virtual Ethernet device may or may not match the type and semantic operation of the real device.
On the other side of the spectrum is direct pass-through I/O virtualization. In this mode, a physical device is allocated (that is, mapped in) directly to a VM. While this maximizes performance, it can violate the partitioning. For example, a guest OS could program direct memory access (DMA) that overwrites memory allocated to another VM. Some Power Architecture processors provide an I/O memory management unit (MMU) that protects against improper DMA accesses.
A hybrid approach, mediated pass-through, provides the performance benefits of direct pass-through but uses a minimal hypervisor driver to ensure that the guest is unable to violate partitioning. In some instances, mediated pass-through may be required even if an I/O MMU is present.
Hypervisors are the glue between the available hardware and the VMs on which OSs run. They mediate access to and virtualize the hardware resources on behalf of the application-domain OSs.
Hypervisor performance is highly dependent upon hardware support for virtualization. With the advent of ISA 2.06’s Book III-E [1], this is now available in embedded Power Architecture-based processors. Without comprehensive hardware support, hypervisors must emulate more of the guest’s hardware environment, reducing performance. Alternatively, guest OSs can be heavily modified (called paravirtualization) to optimize the guest-
hypervisor interface. For example, instead of providing a virtual MMU in which privileged memory management operations are trapped and emulated, a paravirtualized guest OS can make an MMU hypercall, a hypervisor-optimized system call, requesting the MMU modification. Paravirtualization, however, reduces portability, requiring each guest OS to be modified to perform adequately. With Power Architecture virtualization support, hypervisors can realize the ideal combination of guest OS portability and minimal, efficient hypervisor implementation.
Power Architecture hypervisor support
ISA 2.06 embedded virtualization capabilities include a hypervisor mode, guest interrupt injection, efficient guest translation look-aside buffer (TLB) management, and inter-partition communication mechanisms.
The embedded hypervisor mode converts the traditional two-level user/supervisor mode architecture to a three-level guest-user/guest-supervisor/hypervisor mode hierarchy. The hypervisor level enables hypervisor-mediated access to hardware resources required by guest OSs. When a guest performs a privileged operation, such as a TLB modification, the processor can be configured to trap this operation to the hypervisor. The hypervisor can then decide whether to allow, disallow, or modify (emulate) the guest operation. The hypervisor mode also provides for additional guest processor states, enabling guest OSs to access partition-specific logical registers without trapping to the hypervisor.
Guest interrupt injection enables the hypervisor to control which interrupts and exceptions cause a trap into hypervisor mode for hypervisor handling, and which interrupts can be safely redirected to a guest, bypassing the hypervisor. For example, an I/O device that is shared between multiple partitions may require hypervisor handling, while a peripheral dedicated to a specific partition can be handled directly by the partition’s guest OS. Interrupt injection is critical for achieving optimal real-time response.
TLB and page-table management are among the most performance-critical aspects of hardware virtualization support. The TLB and page tables govern access to physical memory and therefore must be managed by the hypervisor to enforce partitioning. Without special hypervisor support, all attempts to manipulate hardware TLB or page tables must be trapped and emulated by the hypervisor, and this mediation can reduce performance.
ISA 2.06 supports doorbell messages and interrupts that enable guest OSs to communicate with software outside of its VM without involving the hypervisor. For example, a control plane guest OS can efficiently inform data plane applications of changes that might affect how packets are processed.
Mode hierarchy
Many processor architectures define user and supervisor states. The OS kernel often runs in supervisor mode, giving it access to privileged instructions and states such as the MMU while applications run in user mode. The hardware efficiently implements transitions between applications and the kernel in support of a variety of services such as peripheral I/O, virtual memory management and application thread control.
To support hypervisors, the Power Architecture now has a third mode to run the hypervisor. Analogous to user-kernel transitions, it supports transitions between user, supervisor and hypervisor states. Another way of thinking about this tri-level hierarchy is that the hypervisor mode is an equivalent of the old supervisor mode that provided universal access to physical hardware states, the guest OSs now run in the guest supervisor mode and the guest applications run in guest user mode.
Interrupt management
The Power Architecture also provides facilities for managing interrupts between the hypervisor and guests. For example, if the hypervisor is time-slicing multiple guest OSs, a scheduling timer may be used directly by the hypervisor. If a guest OS is given exclusive access to a peripheral, then that peripheral’s interrupts can be directed to the guest, avoiding the latency of trapping first to the hypervisor before reflecting the interrupt back up to a guest.
There is also a new set of registers that enable intelligent interrupt management. These include:
- Guest Save/Restore registers (GSRR0/1)
- Guest Interrupt Vector Prefix Register (GIVPR)
- Guest Interrupt Vector Registers (GIVORn)
- Guest Data Exception Address Register (GDEAR)
- Guest Exception Syndrome Register (GESR)
- Guest Special Purpose Registers (GSPRG0..3)
- Guest External Proxy (GEPR)
- Guest Processor ID Register (GPIR)
Most provide states important to servicing exceptions and interrupts and duplicate those available in hypervisor mode (or prior Power Architecture implementations without guest mode). These registers have different offsets from the originals. To ensure legacy OSs can run unchanged while in guest mode, references to the original non-guest versions are mapped to the guest versions above.
When an external interrupt is directed to a guest and the interrupt occurs while executing in hypervisor mode, the interrupt remains pending until the processor returns to guest mode. The hardware automatically handles this transition.
The Power Architecture has introduced some additional exceptions and interrupts to support hypervisors. To allow a paravirtualized guest OS to call the hypervisor, a special system call causes the transition between guest and hypervisor mode. It uses an existing system call instruction but with a different operand.
Some exceptions and interrupts are always handled by the hypervisor. When a guest tries to access a hypervisor privileged resource such as TLB, the exception always triggers execution to hypervisor mode and allows the hypervisor to check protections and virtualize the access when necessary. In the case of cache access, normal cache load and store references proceed normally. A mode exists for guests to perform some direct cache management operations, such as cache locking.
In support of virtualization, ISA 2.06 also introduced a new doorbell interrupt. Besides being a general shoulder-tap mechanism for the system, the hypervisor can use doorbells to reflect asynchronous interrupts to a guest. Asynchronous interrupt management is complicated by the fact that an interrupt cannot be reflected until the guest is ready to accept it. When an asynchronous interrupt occurs, the hypervisor may use the ‘msgsnd’ instruction to send a doorbell interrupt to the appropriate guest. Doorbell exceptions remain pending until the guest has set the appropriate doorbell enable bit. When the original exception occurs, it is first directed to the hypervisor that can now safely reflect the interrupt using the asynchronous doorbell.
Memory management assists
One important role of hypervisors in virtualization is managing and protecting VMs. The hypervisor must ensure that a VM has access only to its allocated resources and must block unauthorized accesses. To perform this service, the hypervisor directly manages the MMU for all cores and in many implementations also manages a similar hardware resource called the I/O MMU for all I/O devices with master memory transactions within the SoC.
In the case of the MMU, the hypervisor typically adopts one of two primary management strategies. The simplest reflects all memory management interrupts to the guest. The guest will execute its usual TLB miss-handling code, which includes instructions to load the TLB with a new page-table entry. These privileged TLB manipulation instructions will in turn trap to the hypervisor so that it can ensure the guest loads only valid pages.
Alternatively, the hypervisor can capture all TLB manipulations by the guest (or take equivalent paravirtualized hypercalls from the guest) to emulate them. The hypervisor builds a virtual page table for each VM. When a TLB miss occurs, the hypervisor searches the virtual page table for the relevant entry. If one is found, it performs a TLB fill directly and returns from the TLB miss exception without generating an exception to the guest. This process improves performance by precluding the need for the hypervisor to emulate the TLB manipulation instructions that the guest would execute when handling the TLB miss.
Extended addressing
To allow the physical TLB to simultaneously carry entries for more than one VM, its virtual addresses are extended with a partition identifier. Furthermore, to allow the hypervisor itself to have entries in the TLB, a further bit of address extension is used for hypervisor differentiation.
In the Power Architecture, the TLB’s virtual address is extended by an LPID value that is a unique identifier for a logical partition (VM). The address is further extended with the GS bit that designates whether an entry is valid for guest or hypervisor mode. These extensions allow the hypervisor to remap guest logical physical addresses to actual physical addresses. Full virtualization is then practical because guest OSs often assume that their physical address space starts at 0.
I/O MMU
An I/O MMU mediates all address-based transactions originating from mastering devices. DMA-capable peripherals such as Ethernet or external storage devices can be safely dedicated for use by a VM without violating the system partitioning enforced by the hypervisor. Any attempt at DMA into physical memory not allocated to the VM will default to the hypervisor. The I/O MMU keeps an internal state that relates the originator of the transaction with authorized address regions and associated actions. The hypervisor initializes and manages the I/O MMU to define and protect logical partitions in the system.
Hardware allocation and sharing
The allocation and possible sharing of hardware resources on a multicore SoC across VMs is one of the most important performance factors. Resources dedicated to a single VM can often execute at full speed, without hypervisor inter-positioning. However, in many systems, at least some of the limited hardware resources must be shared. For example, a single Ethernet device may need to be multiplexed between VMs by the hypervisor. The hypervisor can handle the Ethernet interrupts, transmit packets on behalf of the VMs, and forward received packets to the appropriate VM. In theory, the hypervisor could even implement firewall or other network services between the VMs and the physical network.
Certain applications require shared hardware access but cannot tolerate the overhead of hypervisor mediation. Modern microprocessors are rising to this challenge by providing hardware-mediation capabilities designed specifically for virtualized environments.
Hypervisor software architectures
There are numerous dimensions under which hypervisor software architectures are classified.
One aspect involves dependence upon a general-purpose host OS. When virtualization is added on top of such an OS, it is referred to as a Type 2 or hosted hypervisor. Type 2 hypervisors are common on desktop computers with preinstalled OSs. By contrast, Type 1 hypervisors execute alone in the hypervisor mode of the processor and hence are sometimes called bare-metal hypervisors.
Some hypervisors include aspects of both Type 1 and Type 2. For example, Green Hills Software’s Integrity Secure Virtualization (ISV) is a hybrid virtualization technology that combines a tightly integrated virtualization layer providing hardware resource emulation and other services with a bare-metal embedded OS that provides the fundamental memory and CPU partitioning and scheduling as well as an ability to execute native processes alongside virtual machines.
An ability to execute native processes can be critical in embedded systems in which the guest OSs are unsuitable for certain tasks, such as real-time control or system security enforcement. In addition, native processes can be implemented to perform device multiplexing and other services on behalf of the guests, thereby minimizing the bare-metal portion of the system. The hybrid model is depicted in Figure 2 (p.20).
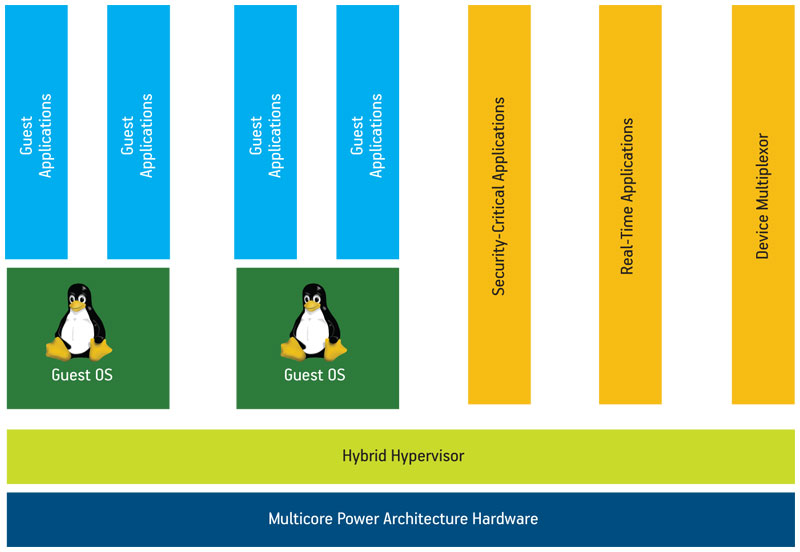
Figure 2
Hybrid embedded hypervisor
Another important aspect of hypervisor architecture is the mechanism for managing multiple cores. The simplest approach is static partitioning (Figure 3,
p. 21), where only one VM is bound permanently to each core. Dynamic partitioning (Figure 4) is the next most flexible implementation, allowing VMs to migrate between cores.
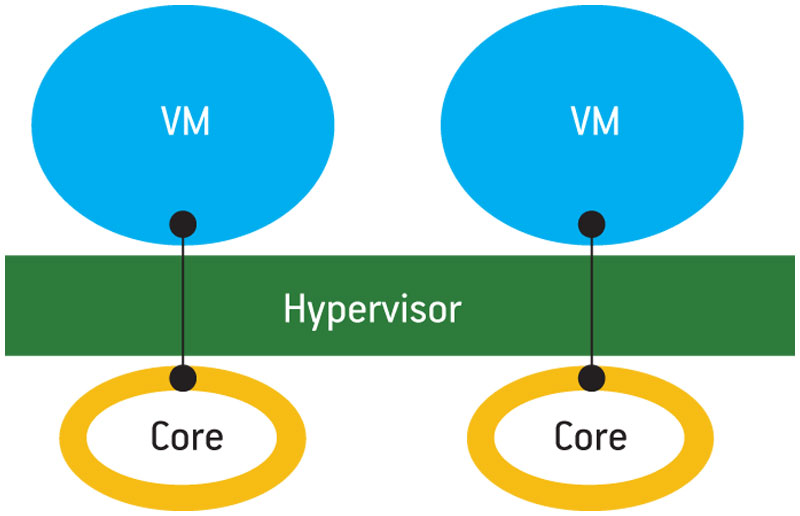
Figure 3
Static partitioning
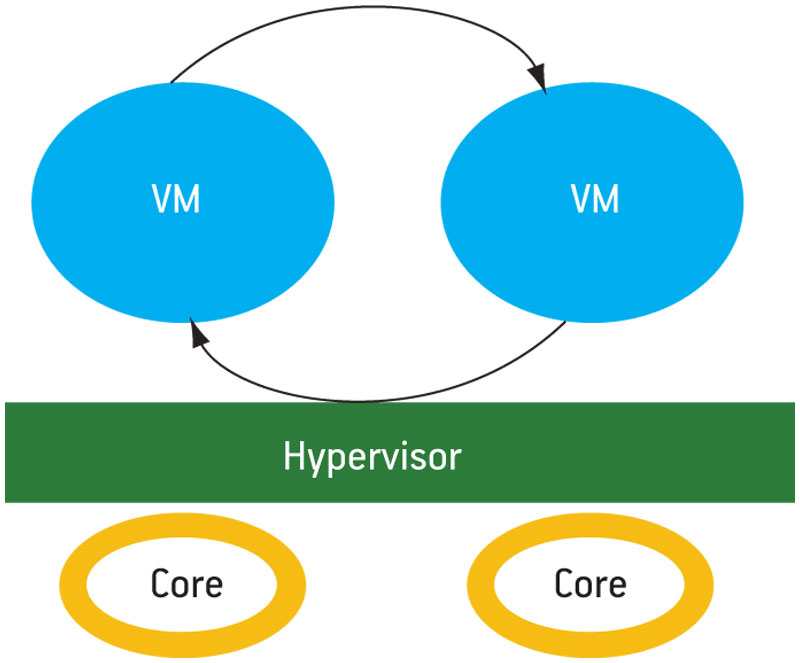
Figure 4
Dynamic partitioning
VM migration is similar to process migration in a symmetric multiprocessing (SMP) OS. The ability to migrate workloads can be critical when the hypervisor must manage more VMs than there are cores. This is similar to server-based virtualization (for instance, cloud computing) where there are more virtual servers than cores and the hypervisor must optimally schedule the servers based on dynamically changing workloads. In embedded systems, the ability to schedule VMs provides obvious advantages such as allowing the user to prioritize real-time workloads.
Dynamic partitioning also adds an ability to time-share multiple VMs on a single core. This is well suited to the previously mentioned hybrid hypervisor/OS model because it means that you can also schedule and time-share processes. Thus, specialized applications can be prioritized over VMs and vice versa.
Dynamic partitioning can be critical for power efficiency. Consider a dual-core processor with two VM workloads, each of which requires 50% utilization of one core. Without sharing, each core must run a VM and use half of the available processing resources. Even with dynamic frequency and voltage scaling, the static energy of each core must be expended. With shareable partitioning, the hypervisor can determine that a single core can handle the load of both VMs. The hypervisor will then time-slice the two VMs on the first core, and turn the second core off, reducing power consumption substantially.
Dynamic multicore partitioning adds support for multicore VMs. For example, the hypervisor can allocate a dual-core VM to two cores, host an SMP guest OS, and take advantage of its concurrent workloads. Unicore VMs can be hosted on other cores (Figure 5).
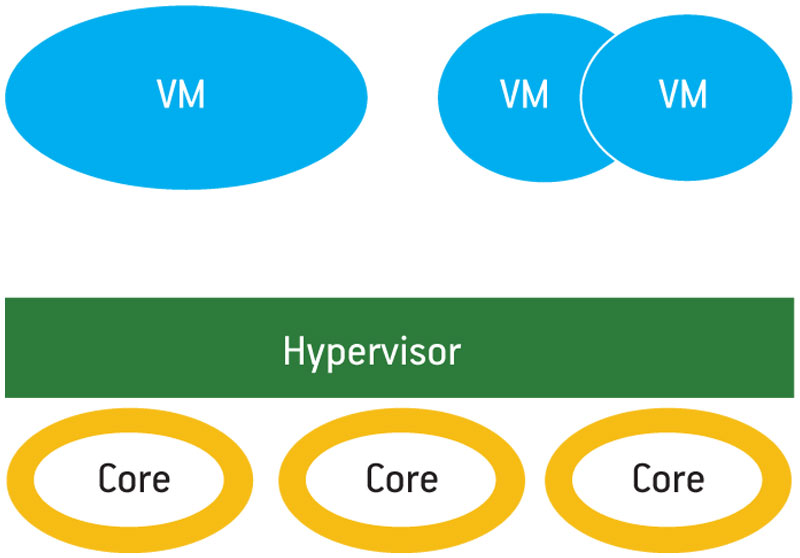
Figure 5
Dynamic multicore partitioning
ISA 2.06 virtualization facilities enable a wide variety of hypervisor approaches for a wide variety of applications and workloads.
ePAPR
The Power.org Embedded Power Architecture Platform Requirements (ePAPR) specification [2] standardized a number of hypervisor management facilities, including a device-tree data structure that represents hardware resources. Resources include available memory ranges, interrupt controllers, processing cores and peripherals. The device tree may represent the virtual hardware resources that a VM sees or the physical resources that a hypervisor sees.
In addition, ePAPR defines a boot image format that includes the device tree. The ePAPR specification enables Power Architecture bootloaders to understand and boot hypervisors from multiple vendors and provides a standard approach for using hypervisors to instantiate VMs.
Conclusion
The Power Architecture is driving new levels of virtualization capabilities into embedded systems. Aggregating formally separate standalone computing resources into a single multicore device presents great opportunities and some challenges. Hardware and software virtualization support is crucial to fully utilizing the capabilities of these complex devices and to meeting the unique requirements of embedded systems that are often different from those in the IT/server space.
Power Architecture hypervisors can provide a level of flexibility, while reducing system size, weight, power and cost, that opens unique opportunities across a variety of applications and markets.
References
1. Download at http://tiny.cc/vjed1
2. Download at http://tiny.cc/n9548
Power.org
c/o IEEE-ISTO
445 Hoes Lane
Piscataway
NJ 08854
USA
W: www.power.org
