A methodology of integrated post tape-out flow for fast design to mask TAT
Semiconductor devices are being fabricated with features that are less than half the wavelength of the available lithography exposure tools. Increasing circuit density has improved the complexity and performance of ICs but also led to serious patterning proximity effects. These effects make the chips almost impossible to fabricate without optical proximity correction (OPC) technology. Thus, as the centerpiece of patterning technology. OPC both directly impacts chip performance and accounts for a large portion of the total cost of chip fabrication.
For a pure-play foundry such as SMIC, turn-around time (TAT) is the major concern. Therefore, to meet a necessarily aggressive tape-out schedule, a significant reduction in the GDS-to-mask run-time was required. Furthermore, we also wanted to achieve a fully automated OPC/MDP [mask data preparation] production flow.
The objective of the research presented here was the evaluation of the run-time for an OPC methodology and integrated MDP flow using what is known as a 1-IO-tape-out platform. We chose backend- of-line (BEOL) layers for the evaulation because these were most affected by run-time performance.
The integrated flow evaluated included four layers of metal with model-based OPC (MB-OPC) and six layers of via with rulebased OPC (RB-OPC).
We also tested the advantage of the OASIS format (compared with GDS) for MDP evaluation.
Integrated post tape out flow
Consider a conventional tape out flow. After receiving the customer’s database information and reviewing the accompanying documentation, the foundry will go through five steps:
- Design rule check (DRC).
- Pre-OPC logic Operation (e.g. shrinkage or Boolean Op.).
- OPC implantations.
- Post-OPC check. (today, mask rule checking (MRC) and XOR checking).
- Fracture to mask data.
This procedure typically involves the use of five separate tools, one for each step. That, in turn, represents five sets of database inputs and outputs and the question of data volume becomes critical. This is where turn-around-time is seriously inflated. For this exercise, we adapted the flow above as follows:
- Pre-OPC DRC using Calibre DRC (e.g., built-in OPC Cleanup).
- Logic operation also using Calibre DRC.
- OPCpro for model-based OPC implementation.
- Post-OPC verification (including ORC (optical and process rule checking) to examine potential weak points, and DRC to check XOR for any major errors after OPC).
- FractureM to do MDP.
The critical point here is that every step can be performed within the Mentor Graphics’ Calibre 1-IO platform, allowing for a significant reduction in data volume.
Illustrations
To offer some context on SMIC’s approach, this section details the evaluation we carried out for OPC and ORC.
First, we applied the hintoffset + fastiter construct. To obtain a fast OPC convergence we performed the process of Apply Known Bias to Target. This essentially predetermined what kind of mask would be needed to print the wafer on target and what mask movement would be needed. The mask was brought close to the target state in a first iteration, and then, moved on to the OPC iteration.
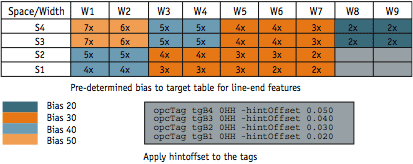
Figure 1. Apply known bias to target
Figure 1 offers an example of this procedure based on line-end feature correction. Given the line-end width and the space between the line-ends, we determined what mask size to target by running and measuring a test pattern. This produced the lineend- correction table shown as an aid to understanding what kind of line-end shortening would be involved.We separated the sample data into four groups/bins, and then applied hintoffset to the setup files. For all kinds of line-end features, we applied different biases before MB-OPC.
A second issue for SMIC as a foundry is that we receive various kinds of designs. In some, there are small jogs, notches or an element of built-in OPC. It may also be the case that there is some tape-in database information which will create problems during OPC. The MB-OPC step can find such problems, so we can perform a pre-OPC-clean-up.
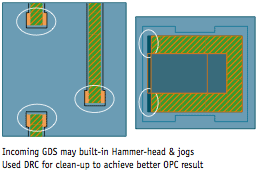
Figure 2. Pre-cleanup of incoming GDS
Another factor concerns designs with a built-in hammer-head, as illustrated in the left-hand example on Figure 2. The orange color is the incoming GDS file with the hammer-head in the line-end. In order to make our OPC easier, we do pre-cleanup. Then, the area marked in green becomes our real target. After that, we applied MB-OPC and the black area became the post-OPC layout. The right-hand example on Figure 2 shows a similar case, but here there are unnecessary jogs which will create problems during OPC. The orange is the incoming GDS with jogs. Clean-up was performed, so that green is, again, the wafer target and black is the post-OPC mask layout.
From here we moved on to the ORC step.We performed two types of ORC: one was edge placement error-based (EPE) for recipe tuning; the second was image tagging followed by CD (Image + CD) simulation for critical failures (bridging, pinching and enclosure).
EPE-based ORC is for OPC convergence test and recipe tuning. This two-line example illustrates the application and objectives:
newTag –tg1D –how subtractTags all tgLE tgPost tgCorner tgAdj
newTag 1D_pos_00_01 –how EPE tg1D 0.00 0.01
Here, ‘1D’ is defined to subtract all features from line-ends, posters, corners and adjacents. You can then carry out the EPE check for all such 1D tags and, in this case, an EPE error from 0 to 10nm was output and separated in the 1D_pos_00_01 bin. 1D is not the only tag filter we applied; there were also ‘2D’ and ‘lineend’. Next, we analyzed all the EPE histograms and put the OPC recipe through another iteration, trying to get those histograms narrower and narrower by looking into each error, while checking against and tuning the recipe.
For the ‘Image + CD-based ORC for critical failure detection’ step, we used ‘Imax’ to denote ‘too small for bridging’ and ‘Imin’ to denote ‘too large for pinching’.We then applied EPE tagging with tag2boxes. Using the offset option to output the Pseudo PrintImage1, all the fragments would print and output an edge out so that wherever the EPE was, that is where the Printimage was also. Later on, we used DRC to measure the CD of the Pseudo Printimage. Finally in this section, I want to consider production flow automation. Given SMIC’s current limited resources, we wanted a process that was as ‘push-button’ and ‘one-stop’ as possible.
To achieve this optimization, we simply separated the flow into two parts: recipe and configuration.
For the recipe part, we optimized all recipes so that they did not need to be changed at the production line. Thus production involved only control of the configuration part, such as the number of CPUs, layer numbers, GDS in-out file names and so on.

Figure 3. Model verification
Results
This section offers more details on the results we achieved for metrics such as modeling accuracy; post-OPC quality (ORC result); and runtime performance/data volume.
For the runtime and data volume elements of the exercise, more than 15 flows were tested, including single layer comparison, multiple layer comparison, partially integrated flow, and fully integrated flow (from pre-OPC DRC to OPC, on to OPC XOR checking and fracturing).
Model accuracy
A ‘Vector Optical model + simple VT5 resist model’ was used to fit the empirical dataset without using any density terms. Most OPC fitting residual errors were within 2nm for 1D and 7nm for 2D.We also performed model simulation comparisons with SEM images to ensure stability, convergence and accuracy (Figure 3).
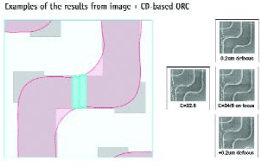
Figure 4. Critical failures detection
Post-OPC quality (ORC result)
In general, no CD Error was larger than 10% of its target. Figure 4 is an example of results from the image + CD-based ORC. The bridging weak point here would not have been detected by using EPEbased checking only, because the CD Error was just about 10% of its target. Fortunately, the Imax checking methodology enabled us to find instances of inadequate fragmentation. The weak point tagged at this stage was confirmed on the wafer.
Runtime performance/data volume
We integrated the hintoffest + fastiter construct, the Calibre 1-IO platform and our improved hierarchy control and flow automation model with the following results: The model-based OPC proved to be about 5X faster and the rule-based OPC about 3X faster than conventional OPC.We found that the total turn-around-time for MDP could be reduced by around 5X on the integrated Calibre platform (Figure 5).
Going further, (Figure 6), we found that in the OASIS format, Calibre reduced the data volume by more than 10X in general and even up by about 80X on occasion. Even though we are not going to put OASIS in our flow, we can note that it offers benefits for database storage.
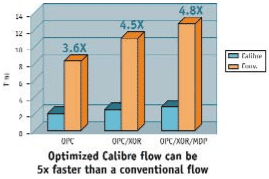
Figure 5. Calibre data volume and run-time comparison
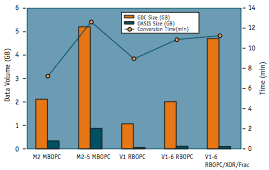
Figure 6. Oasis data volume and run-time comparison