Reducing power demands with specialized coprocessors
Consumer electronics is a difficult business.Market windows open and close quickly. Cost is critical. Requirements change unpredictably. Risk is high. Functionality and performance increase with every product generation, while both manufacturing-limitations and feature-driven demand require low power implementations. Of all these, power constraints have the largest impact on current product architectures. As CMOS reaches its scaling limits, multicore approaches must be used to meet performance needs within stringent low power constraints. At the same time, to manage product complexity and risk, implementations strive to maximize functionality in software without breaking cost or power budgets.
Multi-Core architectures
Multi-core architectures can be broadly classified as symmetric and asymmetric in their processing capabilities.
In symmetric multi-processing architectures, the workload is divided across a set of similar processors.With this architecture, software can run on any available processor.However, for most embedded applications, data flows and processing loads are never uniform, so finding an efficient mapping to a symmetric architecture is very unlikely. Data movement alone can easily break a power budget.
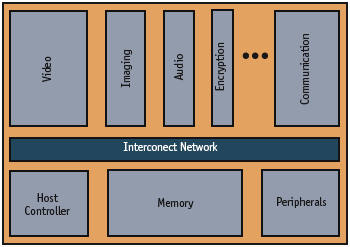
Figure 1. Asymmetric multi-core Architecture
For embedded systems, a more natural partitioning is to divide the workload by subsystem. Rather than balancing processing resources, architectures are defined to minimize subsystem coupling and maximize parallel operations. Programming models are more complex, but data movement is reduced, and processing subsystems can be optimized more independently. One or more centralized control processors may remain for subsystem integration and low demand operations as shown in Figure 1.
Each subsystem can be specialized to match its peculiar processing and data flow requirements. Options for implementing these subsystems range from embedded processors and digital signal processors (DSPs) to custom hardware accelerators.
DSPs retain programmability and are designed for common signal processing workloads, but they are not optimized for specific subsystem algorithms and may not realize all available parallelism in the application. As a result, multiple DSPs may be required to meet throughput requirements, or DSPs may require high clock frequencies which burn too much power.
On the other hand, hardware accelerators are custom-tailored to specific subsystem algorithms. They offer the best power-performance ratio of any solution. Their disadvantages are complexity of design and limited reprogrammability which add substantial risk and limit any ability to adapt the final product.
Application coprocessors
An intermediate solution is a coprocessing subsystem which blends the characteristics of both DSPs and custom hardware accelerators. An application coprocessor, like a DSP, can be reprogrammed, and is therefore capable of running multiple algorithms and being enhanced after market. Like a custom hardware accelerator, the design of an application coprocessor allows for tailored memory interfaces and execution paths that match algorithmic requirements. By doing more in parallel, a coprocessor requires fewer cycles than a DSP. It may be used to accelerate an algorithm, or, by reducing the clock frequency and using slower logic, may give the same performance with much lower power consumption. Resulting designs can approach the performance and low power characteristics of custom hardware while retaining the reprogrammable flexibility of software.
The major remaining disadvantage with application coprocessors is the time required to design and verify their implementation and programming infrastructure. Handcrafted coprocessors including combinations of DSPs and localized hardware accelerators have been designed, but their long development time necessitates early algorithmic partitioning with very limited architectural exploration. Software must be manually repartitioned and critical sections replaced with hardware descriptions and interfaces, and the custom coprocessor must be thoroughly verified.
Overcoming these limitations requires an ability and/or strategy that includes the following:
- Working from the original software – no coding restrictions or rewriting required.
- Automatically synthesizing complete application coprocessors.
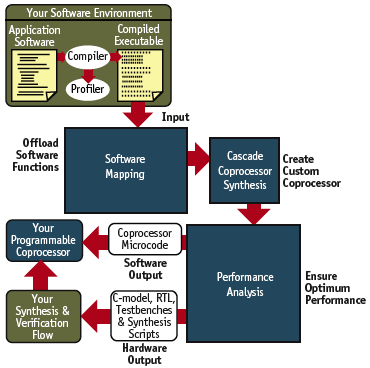
Figure 2. Coprocessor synthesis flow
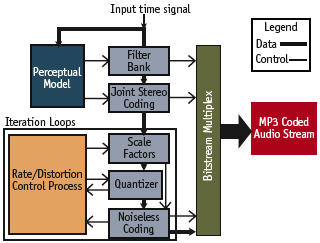
Figure 3. MP3 encoder
Working from the original software reduces errors by maintaining a single point of description, while automatic synthesis greatly reduces design and verification time.Within time-to-market constraints, this software-centric flow enables far more architectural exploration. With more time for system and sub-system optimization, reprogrammability is enhanced while meeting or exceeding critical power constraints.
Maximum software, minimum power
Automatic coprocessor synthesis is used to maximize software content while minimizing power constraints. There are two steps. First, the overall design space is explored to identify an acceptable software distribution onto coprocessors. Next, each subsystem is individually optimized.
This software-centric approach begins with the system functionality described in software. The best place to start is with the application binaries themselves. Supporting binary formats ensures that any compilable language and its constructs can be used including, but not limited to, C and optimized assembler. The original source code is not required, and the developer uses his normal software development flow to develop the application binaries.
Basic software profiling is used to identify functional hotspots within subsystems. These hotspots are likely candidates for offloading onto custom coprocessors. A range of coprocessor implementations can be quickly generated to obtain estimates of different combinations of performance, area, and power.
Additional functions may be moved on and off coprocessors, and different coprocessor combinations may be selected to minimize data movement and global power consumption. Exploration of the design space concludes with a high-level architecture and a set of coprocessors with target implementation metrics that meet overall system performance and power goals.
In the second step, each coprocessor can be individually optimized within the range of the performance, area, and power metrics obtained from the architectural exploration. Coprocessors are optimized in several ways. The cache memory design and communication interfaces can be optimized to minimize data latencies and synchronization overheads. Execution units can be added and chained to exploit available parallelism in the software algorithms, and instruction encodings can be optimized to optimize code density and scheduling.
An optimized coprocessor consists of an RTL level description of the hardware with synthesis scripts and a verification testbench as well as the coprocessor microcode which is patched back into the original application binary. The overall flow is shown in Figure 2. Throughout this flow, the application software need not be modified; instead, the processing configuration executing that software is optimized for the particular functionality and data traces prevalent within the application. The original application software investment is preserved.
MP3 example
An MPEG-1 Audio Layer 3 Codec (MP3) provides a good example of minimizing power consumption at real-time performance while preserving the description in software. In this instance, an MP3 codec had to operate at 40 frames-per-second within the tight power consumption constraints of a portable product. Figure 3 shows the flow of the MP3 encoding algorithm. T
he codec was derived from open source software and had been proven in a previous product, though it ran at a much reduced bit rate. The previous product had run the codec on an ARM926EJ processor. Using the same processor at the new frame rate required the ARM9 to run at over 500 MHz. This exceeded the maximum frequency possible in the 130nm target technology, but if achievable, the power estimate was 226mW. The initial result and subsequent coprocessor results are shown in Figure 4.
Due to time-to-market constraints, and limited knowledge of the software, moving the codec to a DSP or custom hardware would be risky and time consuming.
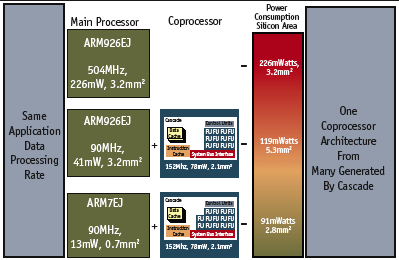
Figure 4. Power-reducing design variations
ARM + application coprocessor
After profiling the code running on an ARM9, the polyphase quadrature filter (PQF) and modified discrete cosine transform (MDCT) were identified for offloading onto a custom coprocessor.Multiple coprocessor configurations were synthesized to provide a range of performance-power tradeoffs. The key results and design choices are summarized below and in Figure 5.
The combined ARM926 EJ/Cascade coprocessor configuration met the desired frame rate with a power consumption 47% lower than that of the stand-alone 926EJ. The clock frequency of the ARM9 was reduced to a more reasonable 90 MHz while the coprocessor ran at 152 MHz. Adding the coprocessor increased the silicon area from 3.2mm2 to 5.3mm2, an increase of 65%. Being a high volume consumer product, this area increase was undesirable.
With most of the compute intensive operations and data streaming now running on the coprocessor, a smaller footprint and lower royalty ARM7 was considered. An ARM7EJ without cache memory was determined to be an adequate replacement for the ARM9.
In this final configuration – the ARM7EJ/Cascade coprocessor configuration consumed 60% less power than the stand-alone 926EJ, and, combined, used 12% less silicon area than the original ARM926EJ.
A good day’s work
While retaining full programmability, synthesis of the audio application processor required only one engineer day of effort.
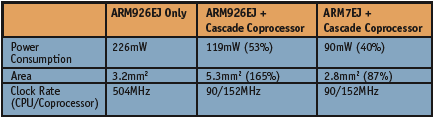
Figure 5. Results for a commercial MP3 design
While meeting the MP3 frame rate requirements, the Cascadesynthesized coprocessor cut power consumption in half. The reduced processing requirements enabled the ARM9 to be downgraded to an ARM7, resulting in lower IP royalties and additional area and power savings. The resulting application and codec are fully reprogrammable while the new solution reduced power consumption by 60%.
In a larger system design, the benefits of this software-centric flow are magnified.More time is available for architectural exploration, and maximizing programmability while meeting power constraints is an invaluable benefit to a consumer device.
CriticalBlue
226 Airport Parkway, #470
San Jose
CA 95110
USA
T: +1-408-467-5091
W: www.criticalblue.com