Optimizing energy in processor-memory subsystems during SoC design
System-level architectural decisions made before any RTL code has been written have a much larger impact on overall system energy than RTL-level, gate-level, or circuit-level tweaks. The Xenergy tool from Tensilica estimates energy for a processor subsystem (processor, caches, local memories) based on the application code that will run on that subsystem. Designers can thus tune the software and optimize their Xtensa configurable processors and the associated memory subsystems for energy.
A focus on total energy consumption is key. Too often, designers will focus merely on the mW/MHz power figure for processor core logic, but ignore the total energy consumption per unit of workload. An increase in power-per-clock of 20%, for example, might be offset by a 3X speedup in application execution. The mW/MHz number increases 20%, but total energy consumption is actually reduced by 60%.
Sometimes applications can be accelerated by increasing accesses to local memories. While performance on the processor increases, total energy usage can increase significantly since memory accesses dissipate more energy than processor activity. Xenergy helps the designer make informed trade-offs between performance and energy consumption.
Power has become a first-order concern for SoC designers, right alongside performance and area, and it is of equal importance whether the design is a portable device or a networking box. Optimizing energy at an application and system level can improve energy efficiency by an order of magnitude. At lower levels of abstraction (RTL and below), the best improvement is 2X. Additionally, by iterating early in the design cycle, SoC designers can avoid the months of effort required when power optimizations are left until much later in the flow.
Several low-power EDA methodologies target clock gating; voltage and frequency reduction; gate sizing and logic optimization; leakage reduction techniques; and low-power libraries and technology processes. By contrast, taking appropriate system-level architectural decisions – such as those that address the number and size of local (tightly coupled) memories and caches, or data flow interconnects for streaming data sources – has a much large impact on overall system energy.
Much emphasis has been placed on guiding the SoC designer towards performance- and/or area-optimized architectures during memory subsystem design (banked memories versus a single large memory), interconnect design (single bus versus a hierarchy of buses versus point-to-point interconnects), and cache design. However, little has been done to guide them towards energy-efficient solutions.
In response, Tensilica has just launched the Xenergy tool. This seeks to provide SoC designers with early estimates of the energy performance for the processor subsystem (processor, caches, local memories). It does this based on the application code that will run on that subsystem. Energy estimates take minutes rather than the hours or days needed for RTL-based power analysis, and give engineers the data they need to appropriately optimize both the processors and the software applications.
The tool provides a way to estimate the overall energy impact of different processor configurations and extensions. It also enables the energy-driven tuning of application code on the overall processor and the memory subsystem. Coupled with traditional software tool chains that focus on guiding application code development to improve performance, Xenergy assists designers in correctly choosing between performance-energyarea trade-offs during code development and processor-memory subsystem tuning.
Optimizing processor and memory energy
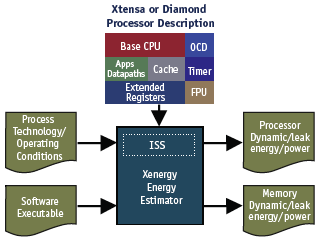
Figure 1. Using Xenergy to estimate energy for an application running on an Xtensa or Diamond Standard processor
Xenergy executes a software application binary on one of Tensilica’s Xtensa configurable processors or one of the company’s Diamond standard processors. It quickly generates its early estimate of the power and energy consumed by the processor, caches, and local memories, so that the designer can tune the application software or hardware configuration as appropriate.
Inputs to the tool include a software binary, data about which processor the binary is targeting, and data about the process technology and operating conditions. Xenergy then executes the binary on an instruction set simulator (ISS) and generates its power and energy report for the core and memory.
This report includes a breakdown of the dynamic, leakage and total power and energy consumed by the core and the memories connected to the local memory interfaces. The flow is depicted in Figure 1 and has two use models:
- Designers can tune application software to reduce processor and memory energy (e.g., by reducing the number of memory accesses).
- Designers can tune hardware for energy by selecting different configuration options; by adding instruction extensions, register files and new execution units; and by changing the number and size of local memories and caches.
A focus on total energy consumption is key. Too often, designers focus on the static milliwatts per megahertz (mW/MHz) power figure, but ignore the total energy consumption per unit of workload. They may add a set of application-specific instructions to a processor that increases the total size of the processor core and, thereby, increases the average power per clock cycle (mW/MHz). But if that added instruction set dramatically lowers the total clock cycles (ms) required to perform a given functional workload then the total energy consumed (power-per-cycle multiplied by total cycle time) can be reduced. For example, an increase in power-per-clock of 20% might be offset by a 3X acceleration in application execution. While mW/MHz increases by 20%, total energy consumption actually drops by 60%. The tool is designed to be used iteratively, first by the processor designer when selecting the configuration options and adding new instruction extensions, then by the software application developer as the application is tuned. In earlier flows, the hardware and software developers only had performance and area analysis tools to guide them through this hardware-software tuning process. Xenergy provides them with early energy guidance as well.
Energy modeling strategy
Xenergy uses statistical models for energy-per-memory-access (read and write) and energy-per-instruction, including energy estimates for designer-defined instruction extensions specified in the Tensilica Instruction Extension (TIE) language. These models were developed by doing detailed synthesis and RTL, and gate-level simulation on a very wide range of processor configurations for a variety of different process nodes.
For each designer-defined instruction extension in an Xtensa processor, the tool creates an energy estimate, and models the energy consumed by all locally attached memories that are active for that given instruction. It then simulates the application on a cycle-accurate ISS, which gives detailed profiling information about each instruction executed and every memory access made. Based on this, the tool uses its statistical models to estimate the dynamic, leakage and total energy dissipated by the processor, the caches, and the local instruction and data memories.
Energy as another variable in the design decision matrix
The RGB-to-YUV color conversion benchmark from EEMBC (the Embedded Microprocessor Benchmark Consortium) is available at www.eembc.org and can be used to illustrate the Xenergy tool in use. The kernel itself converts pixel color information from RGB to YUV for a 32x32pi image.
Tensilica’s XPRES (Xtensa PRocessor Extension Synthesis) compiler is used on the color conversion benchmark. It takes as input the application software specified in C or C++ and generates processor extensions in TIE. It then explores the design space in an attempt to find the best performance solution. The designer can also control these search strategies by placing constraints on the area overhead and the amount of performance improvement required. XPRES is directed to generate three solutions based on three optimizations for instruction extensions to an Xtensa processor.
- Generate TIE instructions that are operation fusions. A fusion operation is a combination of multiple operators into a single, complex operation.
- Generate SIMD (single instruction multiple data) functional units (and corresponding instructions) that are vector operations, which apply the same operator on multiple data elements.
- Extend the processor into a VLIW (very long instruction word) architecture using Tensilica’s FLIX (Flexible Length Instruction eXtensions) technology. In this approach, XPRES creates a multi-issue datapath in which a VLIW instruction contains several operations. The compiler automatically extracts parallelism from the C/C++ application code and packs multiple operations into a single VLIW instruction bundle.
The results for performance (cycle count), energy (uJ), and area (gate count) normalized to the largest value in the data set are shown in Figure 2 (p18). The cycle count is determined by executing the color conversion application on the ISS. The energy estimates for processor, memory, and the total thereof are generated by the Xenergy tool. The gate count is estimated by the TIE Compiler.
Those results in Figure 2 illustrate these aspects of tool functionality:
- When it generates SIMD operations in addition to fusion operations, the performance improves significantly — by about 3.8X. The gate count is almost 5X more. Energy for the processor and memory track performance quite well.
- When it generates the VLIW (FLIX) architecture, it improves performance by roughly 20%. However, the gate count doubles. In this case, even though performance improved, energy worsened, particularly, energy dissipated by the processor.
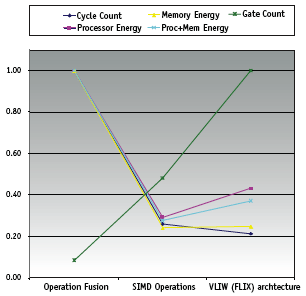
Figure 2. Performance, energy, and area trade-offs for different Xtensa processor extensions
The data generated shows that the performance improvements due to the SIMD operations lead to large energy reductions that clearly outweigh the power/energy increases attributable to the increase in area (gate count). In the VLIW case, the energy increase attributable to the increase in area outweighs the decrease in energy due to the performance improvements. This example shows the flexibility that the energy estimation tool gives SoC designers in evaluating complex, non-obvious trade-offs between performance, area, and energy.
The effect of memories and application code
Xenergy’s consideration of memory power consumption is an important part of the tool. Imagine a scenario where a custom TIE instruction improves application performance, but also significantly increases accesses to memory. Even though the application may execute faster and, therefore, consume less energy on the processor, the extra memory accesses increase overall energy consumption. Similarly, a designer can modify the cache configuration (size, associativity) to optimize for energy.
If designers do not pay attention to memory energy consumption, the new TIE instruction may produce a less energy-efficient solution. Xenergy will highlight this, making it easy for the designer to understand the impact of the changes on the total processor, early in the processor configuration stage.
Similarly, a software programmer developing application code for a Tensilica processor has traditionally tuned that application for either performance or code size. The new tool now helps that developer tune the application to reduce energy dissipation by the processor and its memories. For example, a developer may rework the data structures in an application to reduce accesses to memories by exploiting temporal locality of the data. Intuitively, this should not only lead to better application code performance, but also reduce energy. Tensilica’s standard software profiling tools will demonstrate if application performance improves, while Xenergy determines if the code tuning reduces energy also.
Summary
Xenergy is a powerful tool that gives an early estimate of the energy of the processor-memory sub-system. Designers can immediately see the impact on total energy consumption of their selection of Xtensa configuration options (multipliers, DSP engines, a floating point unit, etc), additional TIE instruction extensions, and the number and size of local memories and caches. The tool’s ability to model designer-defined TIE instruction extensions is critical to engineers that use the Xtensa processor as an RTL alternative while designing the data plane of their SoC. These users write a significant amount of TIE to create the same hardware structures they would, were they implementing the architecture using hardwired RTL. Being able to get an early estimate of the impact on energy of their custom TIE instructions is as important to most designers as the results gained from area estimation and performance profiling tools.
Tensilica
3255-6 Scott Blvd
Santa Clara
CA 95054 USA
T: 1 408 986 8000
W: www.tensilica.com