MPSoC demands system-level design automation
The relative performance of a single processor has leveled off in the last decade. Built-in instruction-level parallelism is becoming less efficient because issuing more than four instructions in parallel has little effect on most applications. Meanwhile, recent attempts to boost performance have come dangerously close to the energy/power consumption ceiling. Dedicated hardware accelerators may prove valid alternatives for some applications, but do not offer the flexibility and programmability an expensive chip development project needs to meet time-to-market nor optimize its longevity. We need alternative solutions. One of the most promising is the multiprocessor-system-on-chip (MPSoC).
MPSoCs address power issues largely by exploiting parallel software. Multiple processors can execute at lower frequencies, resulting in comparable overall MIPS performance; designers can slow clock speed, a major constraint for low-power projects. However, MPSoC transfers challenges from hardware to software as traditional sequential software does not exploit parallelism.
Abstraction has historically been the main response to increasing complexity. It has moved the industry from layout to transistors to gates and then to RTL. Designs have then grown more complex, moving the industry forward to block-level strategies. This transition was very much hardware-based.
The next logical step is to parallel hardware and software design via a sea of programmable processors, combined with programming models that express parallel software running on MPSoCs. But, while the hardware design of multiple processors on a single die is well understood, daunting questions surround MPSoC programming, debugging, simulation, and optimization.
MPSoC users and use models
The end-user wants to develop an application for an MPSoC. To assess the feasibility of his performance targets, constraints must be checked and power consumption optimized. This requires the exploration of various options for partitioning the parallel software. The designer wants to ensure that the selected application will run to specification. This involves programming computation-intensive parts of the application and verifying the MPSoC’s performance in a range of appropriate scenarios.
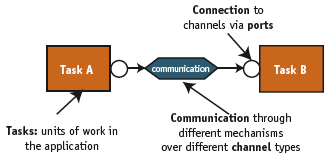
Figure 1. Tasks, ports and channels in a programming model
Users and designers need effective MPSoC simulation, debug and analysis. Parallel programming techniques for the software must also be available along with an efficient automation process for mapping that software to the parallel hardware. The degree of integration and the execution speed then determine the productivity level.
Software verification is typically completed once hardware is available by connecting single core focused debuggers via JTAG to development boards. Sometimes prototype boards are used with FPGAs representing the ASIC or ASSP under development.
Designers now also use virtual prototypes that simulate the processor and its peripherals in software or via dedicated hardware accelerators. All these techniques have different advantages and disadvantages. Software verification on real hardware is only available late in the design flow and offers limited ability to ‘see’ into the hardware. It does not normally take turn-around-time into account when defects are found that can only be fixed with a hardware change.
Prototype boards are available earlier but require the maintenance of several code bases of the design – one for the FPGA-based prototype, one for the real ASIC/ASSP. This can make it hard to get enough visibility into the hardware design for efficient debug.
Virtual prototypes are available earliest of all and offer the best visibility into the design, but often represent an abstraction and as such are not ‘the real thing’. There is the risk that defects are ‘found’ which are not in the real implementation or that defects in the real implementation are not found because the abstraction did not enable their discovery. There are also differences between the time when the virtual prototypes become available and their speed. Reasonably fast (e.g., tens of MIPS) models can be available long before verified RTL but users typically pay for this by sacrificing some accuracy.When cycle accuracy is required, models are not usually available long before RTL. Then, hardware-assisted methods such as emulation are feasible alternatives.
Shortcomings and solutions
A major shortcoming in many solutions for parallel software on parallel hardware is their single core focus. Today’s systems require new analysis and debug techniques. Users face issues of functional correctness and performance. Here are some issues that keep MPSoC software engineers awake at night.
Data races. Two or more threads or processors are trying to access the same resource at the same time, and at least one is changing its state. If they are not synchronizing, one cannot know which will access the resource first, causing inconsistent results in the running program.
Stalls. One thread or processor has locked a resource and then moves on to other work without releasing the lock.When a second thread or processor tries to access the locked resource it cannot.
Deadlocks. Similar to stalls, they occur under a locking hierarchy. For example, Thread 1/Processor 1 locks Variable A and then wants to lock Variable B while Thread 2/Processor 2 is simultaneously locking Variable B and then trying to lock Variable A.
False sharing. This is not necessarily a program error, but a performance issue. It occurs when two threads or processors are manipulating different data values on the same cache line.
Memory corruption. A program writes to an incorrect memory region. This happens in serial programs and is even more difficult to detect in parallel ones.
MPSoC parallel programming
The adoption and standardization of the right programming models are important prerequisites for moving MPSoCs into the mainstream. Several have been analyzed in projects under the MESCAL research program, including some dedicated to Intel’s IXP family of network processors and some as a subset of the MPI (Message Passing Interface) standard. Open MP and HPF are two other high performance computing models.
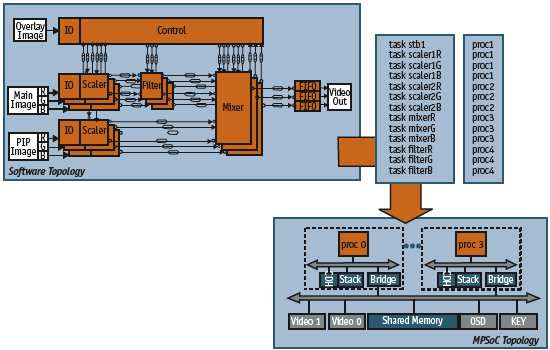
Figure 2. Application to MPSoC mapping
In SoC specifically, STMicroelectronics is part of the MultiFlex project, which aligns with the POSIX standard and CORBA. NXP Semiconductors has demonstrated an abstract task-level interface named TTL, following earlier work on YAPI. Another DSP-focused model is called StreamIt.
Each model has specific advantages, often application-specific ones. The target architecture may also affect the model choice. And there can be trade-offs between abstraction and performance. Figure 1 shows one approach where parallel tasks – communicate with each other via channels and talk to channels via ports. Various communication modes like blocking and non-blocking can be supported and communication can be implemented in various ways depending on the platform.
Parallel software and MPSoCs
These models above show that MPSoC designers and users must be able to rapidly program different combinations of parallel software that run on parallel hardware, automated. It is essential here that the descriptions for application functionality and hardware topology are independent of one other, and that users can define different combinations using a mapping of parallel software to parallel hardware. This requires a description of the software architecture in combination with the programming models. For a mechanism in which the communication structures are separated from the tasks, a coordination language is needed to describe the topology.
A description of the hardware architecture topology is also required. This allows a mapping to define which software elements are to be executed on which hardware resources and which hardware/software communication mechanisms are used for communication between software elements. In the hardware world, the topology of architectures can be elegantly defined using XML-based descriptions as defined in SPIRIT. In the software world, techniques exist to express the topology of software architectures (e.g., techniques defined in UML).
Figure 2 illustrates this relationship. The upper left portion shows the topology of a video scaler application with 13 processes communicating via 33 channels. The lower right shows a MPSoC topology with four processors and shared memory. If these are kept independent, different design experiments can be run, mapping between processes in the application and the processors executing them.
Outlook
The inevitable switch to multicore designs will cause a fundamental shift in design methodologies. However, the effects this switch will have are not yet well understood and are likely to spawn a new generation of system design automation tools.
The support of commercial tool providers and the efforts of organizations such as the MultiCore Association in driving communication interface standards will be key in triggering MPSoC’s widespread adoption.