Micro-architecture exploration for deep submicron design
Alcatel Space supplies complete satellites for use in geostationary and low-earth orbit as well as custom designs for specific missions. These are based on various in-house platforms which support different payloads according to their final use. Fields serviced include telecommunications, observation, meteorology, navigation and science.
The company has 5,600 employees, of which around 2,000 work at its site in Toulouse, France. Toulouse is also the home of its ASIC development group, comprising 12 engineers. Here, we develop silicon for everything in a satellite, be it part of the platform or payload. Applications include solar panels, maneuvering thrusters, antennas, cameras, receivers and transmitters, as well as hardware and software for information processing.
A major part of our work is on proofs-of-concept for next-generation technologies that are based on sophisticated algorithms developed by system engineers in Alcatel Space’s various divisions.
Strain on the design flow
By early 2004, our designs typically contained about one-million equivalent gates in a 0.35ìm process, but we had already worked on two million-gate designs implemented using 0.18ìm, and are presently working on a six million-gate design in 0.13ìm. The existing design flow for digital signal processing ASICs begins with another group at Alcatel that evaluates different complex algorithms using tools such as MATLAB and SimuLink from The MathWorks. Hand-coded ANSI C/C++ descriptions are then developed based on the MATLAB simulation models. Once completed, these ‘golden’ C++ models are handed off to the ASIC design team.
The ASIC team’s objective is to create an HDL representation of the design at the RTL level of abstraction. Over the years, we have amassed a huge library of existing C++ models for different portions of a design.We try as much as possible to re-use these models in different designs. But, for today’s larger, more complex designs, we have found that traditional ASIC prototyping has become more time consuming because it requires several laborintensive steps:
- The creation of a paper specification on how to architect the design, including resource sharing.
- Coding the RTL version of the design.
- Validation of the RTL model against the original C++ source code.
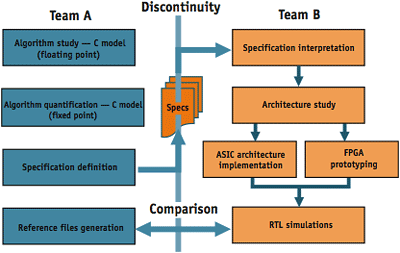
Figure 1. The risks of manual translation
Figure 1 illustrates how an emerging discontinuity between the golden C++ model and the RTL description complicated the original design flow because of the potential for errors to be introduced during manual translation. In conjunction with the RTL code development and validation, our team members continuously evaluate whether the timing and area goals will be satisfied. But any changes at the RTL level are very time consuming because of the sheer size of the RTL description.
Consequently, we are often forced to limit the design exploration, resulting in the creation of sub-optimal RTL code.
Once the RTL code is created and validated via RTL simulation with a subset of all possible test vectors, more exhaustive validation begins using FPGA prototyping. FPGAs are employed so the designs can be validated at real-time speeds, as opposed to requiring days or weeks of RTL simulation. This approach enables us to go far beyond the first-stage validation of the functionality of the RTL, resulting in a more comprehensive assessment of the design’s performance.
As an example, we partitioned one telecom application ASIC for on-board processing across five FPGAs mounted on the real circuit board with all of the ancillary circuitry, such as A/D and D/A converters. A massive amount of real-world data was then streamed through the FPGAs to simulate the effects of noise and signals being obscured and/or distorted.
Despite our objective of maintaining the same RTL code for both FPGA and ASIC targets, the reality was that specific RTL modifications had to be implemented in order to reach the required performance of the target. Therefore, once the design had been validated, the team faced the time-consuming and risky task of reengineering the RTL for a target ASIC implementation.
Towards higher level abstraction
Given these concerns, we decided to investigate new approaches that promised to move design synthesis to a higher level of abstraction.We hoped to use these to achieve high-quality designs while still meeting our aggressive schedules. But we also had some very specific needs of our own.
We wanted to use our large library of golden C++ models to automatically generate the RTL. Moreover, we needed the ability to quickly explore alternative micro-architectures. This included making area and performance tradeoffs by controlling resource sharing, loop unrolling, and loop pipelining, all at the C++ level of abstraction (but without modifying the original C++ model).
Evaluation
We first investigated a SystemC synthesis flow only to discover that this required re-coding everything in a pseudo-timed C++. This style of C++, often referred to as Behavioral SystemC, is closer to RTL abstraction than untimed C++ and is extremely difficult to write. Ultimately, this approach was abandoned not only because it required considerable programming expertise and code modifications, but more importantly, it did not give acceptable RTL results.
Next, the team decided to investigate the effectiveness of synthesizing RTL directly from algorithmic C descriptions. Tools have recently been introduced for C-based design flows that use C code as input. This code is very close to what a system designer would write to model functional behavior without any preconceived hardware implementation or target device architecture in mind. As opposed to adding ‘intelligence’ to the source code (thereby locking it into a target implementation), all the intelligence is provided by controlling the C synthesis engine itself.
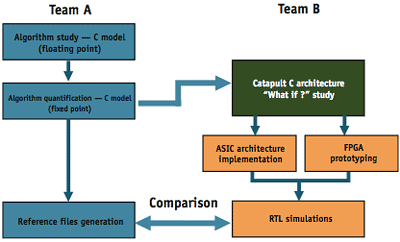
Figure 2. Synthesis directly from C to RTL
Since we, like many design groups working on data-intensive applications, already create an untimed C/C++ representation of the design for algorithmic validation, the ability to synthesize directly to RTL from the C description promised to dramatically shorten development time (Figure 2).
To validate the quality of the results produced by algorithmic C synthesis, we decided to use Mentor Graphics’ Catapult C toolset to automatically generate RTL for an existing design that was already in prototype evaluation. All of the C++ models and most of the RTL code for the initial version had been manually created using the team’s traditional design flow. As the RTL code had already been created, the design would provide an ideal comparison for our evaluation of C-based synthesis. Specifically, the evaluation design was made up of five FPGAs used to implement the functionality of the eventual single ASIC.
Leveraging the design’s partitioning, we started with three small functional blocks to perform the initial testing. The first block was from the power recovery stage, the second was from the timing recovery stage, and the third was a filter block from the frequency recovery stage.
Using the traditional flow, each block took three weeks to complete:
- The first block involved writing the paper specification on resource sharing and the target micro-architecture.
- The second was generation of the RTL.
- The third was verification that the RTL exactly matched the C++ model.
The first two blocks were well understood, with hand-coded RTL that provided the optimum implementation. The third block had been knowingly created in a sub-optimum way to facilitate the implementation of the sequencing function.
Promising results
Using the C synthesis tool, it took about one week to process the C++ code for each block and one day to generate the RTL. For the first two design blocks, we matched the efforts of the RTL experts using C synthesis, but in near one-third the time taken for previous runs. These were the blocks that were hand-coded for the known optimum implementation.
For the third block, which had been sub-optimally designed to facilitate architectural exploration, the new methodology generated RTL that synthesized to 50% of the gates/resources compared to those in the RTL generated by the experts.
So, where using our traditional RTL flow, three blocks took approximately nine weeks to design, once we were up to speed on Catapult C Synthesis, all three blocks were done in three weeks, starting from the original untimed C++ source – an impressive 3X improvement. The most surprising outcome, however, was that the resulting RTL design was not only equivalent to the hand-coded design but in some cases actually smaller and faster. Because it supports the use of ANSI C++, this approach also allows us to leverage our golden C++ models. Once the C++ design is read into the C synthesis tool, we can easily perform micro-architectural ‘what if?’ tradeoffs in terms of area and performance.
Catapult C enables us to quickly specify the ports on the design (RAM, register, FIFO, etc) using interface synthesis. The loop hierarchy of the design is presented graphically in the tool, allowing us to partially or fully unroll loops, as well as to control loop pipelining and resource sharing globally or at the component level.
It can be very time consuming to tune the micro architecture to achieve the same behavior as the C++ models. Since Catapult C allows resource sharing, we did not get tied down in tuning the micro-architecture. Instead, we were able to free up many hours of valuable time to invest elsewhere in our design flow.
In addition, Catapult C automatically generates reports that indicate area, latency, throughput and clock frequency for each micro-architecture that is explored. It also provides a graphical depiction of the solution space using X-Y plots and bar charts. All of this is done while leaving the original C++ code intact.
Extending the evaluation
We then expanded our evaluation to include the design’s major functional block: the entire estimation section of the frequency recovery stage.With the traditional flow it had taken two weeks to write the specification (for resource sharing, proposed RTL architecture, etc). Then one engineer spent two weeks generating the RTL. Next, testing and verifying that the generated RTL matched the C++ code took one week. All together, a five week effort.
The frequency block alone required 102 Virtex II multipliers. This major contribution to the total number of multipliers (159 multipliers) resulted in the design exceeding the available Virtex II 6000 resources (144 multipliers). The original C++ design was handed over to an engineer on our team who by this time was very conversant with Catapult C.
It took him one week to process the C++ and another day to generate the RTL in Catapult C. The resulting design required only 61 block multipliers (Figure 3). However, while the initial result had a lower number of multipliers, the LUT count was close to exceeding the maximum number of LUTs available on the Virtex II 6000, rendering the design unroutable. This increased LUT count was caused by a combination of register sharing in the high-level synthesis and MUX mapping in the downstream RTL synthesis.
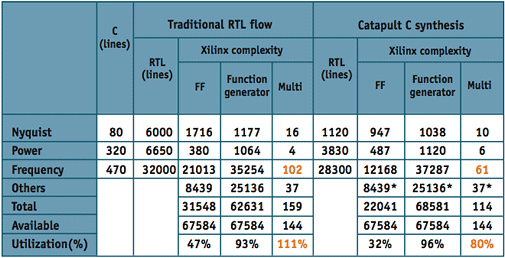
Figure 3. Evaluation phase one
The next step was to take advantage of tool’s enhanced ability to control register sharing, and thus effectively reduce the LUT count. In addition to this, new ‘placement aware’ optimization algorithms were added, which created a more routable design.
Enhancements had also been made to the Precision RTL Synthesis tool, which enabled it to identify certain types of MUX structures and employ technology-specific mapping techniques that effectively reduce the MUX area. The combination of these three enhancements reduced the area of the frequency block by over 50% (Figure 4) allowing the design to easily fit into the Virtex II 6000.
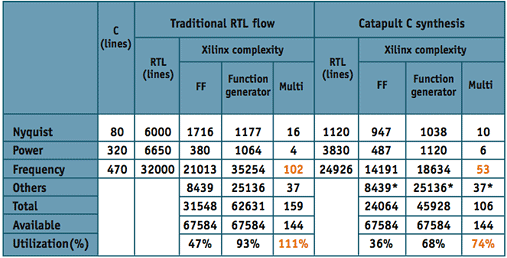
Figure 4. Evaluation phase two
Conclusions
For this entire evaluation, our design group at Alcatel Space was able to meet or exceed the results of the hand-coded portions of the design in significantly less time. Moreover, we were able to meet the design requirements for a major design block that had been previously unattainable using our existing flow.
This was achieved by leveraging the ‘placement aware’ optimizations in Catapult C, which reduced the design time from one month to one week for that block.
In our view, C synthesis truly does raise complex design to the next level of abstraction. By allowing system architects and hardware designers to connect the algorithmic C++ and RTL domains, it eliminates the need for manual RTL creation and all its associated pitfalls.
Companies can now use their existing libraries of golden C++ models to automatically create high-quality RTL designs.More importantly, Catapult C has given us the ability to tradeoff area and performance requirements via micro-architecture exploration, ultimately converging on optimal implementations for all design blocks.