Changing the economics of chip verification
Introduction
Burgeoning design complexity has greatly increased the scale of the verification effort. At the same time, there is a widening gap between the growth in vital activities such as functional verification and the ability of tools and methodologies to fulfill such tasks efficiently. If we fail to close that gap, the potential impact on design quality and time-to-market is self-evident.
We want to discuss this problem from an economic as opposed to technological point of view, notwithstanding that the two elements are inextricably linked. As the verification workload increases, it is inevitable that its cost and its share of the overall development budget will increase also.
This poses a challenge to both privately financed start-ups and financially fit public companies. The need to augment a server farm to match rising design complexity is a problem to tax the mind of any chief financial officer.
Critically, we are at a point where verification cost threatens to outstrip the capacity of the available verification methodologies. Most current strategies involve the expense of adding more equipment, more simulation software licenses and more personnel. All these factors can negate the benefit of many of the spending controls companies have traditionally achieved through ongoing productivity programs.
Verification is therefore on the same resource-and-cost treadmill that design was on during the 1980s. In order to deal with the exponential increase in verification that is a result of Moore’s Law, we need a solution that delivers the order-of-magnitude increases in productivity for verification that library-based design and logic synthesis gave to design two decades ago.
To see how this might be achieved, we must first understand the limitations of existing strategies.
The cache miss problem
One way of increasing productivity is simply to increase processor speeds. However, the resultant increase in throughput is purely incremental because the standard processor is essentially a serial engine – it lacks the instruction-level and hardware resource parallelism necessary to process more than one routine at a time.
It also suffers from ‘cache misses’. Recovery from a cache miss requires that the data be re-accessed from the main memory, a task that is slower than accessing from the cache memory. In addition, this transfer of new data to the cache memory imposes a time delay. Consequently, performance scales with cache size, memory bandwidth and latency, rather than with processor speed.
The brute force approach
A common response to the verification problem is to partition simulation into multiple tasks for parallel execution on a server or server farm. The problem is that this increases resource parallelism only linearly, therefore productivity increases and cost reductions are, at best, also only linear. Often, however, they are less than linear.
The size of any increase in throughput depends heavily on the design team’s ability to identify and partition those processes that can be executed in parallel across the server array. This is no trivial task. Many processes are sequential, so they cannot be partitioned. The more sequential processes there are, the less linear the increase in throughput. This approach also still suffers from the biggest problem – cache misses.
Moreover, parallel process identification and partitioning is a manual, time-consuming task, further eroding any productivity increase won elsewhere with this strategy. Then add the need to run regression tests every time the testbench is enhanced, and the result is a bottleneck that this approach cannot eliminate because it is inherent within it.
Design-for-verification
Some design teams have moved to higher levels of abstraction – C, C++ or SystemC – in the hope of improving verification productivity. Usually, C/C++/SystemC wrappers around the RTL blocks issue commands that stimulate RTL inputs and service monitors that observe the outputs. This technique is said to increase simulation speed by reducing the amount of implementation detail that must be verified by the simulator.
In order to increase performance, the design team must model major portions of the RTL at the higher abstraction level. This is both time-consuming and can be as complex a task as the original RTL design effort. When simulation detects a bug at this higher level of abstraction, the engineers must first ensure that the wrapper is bug-free, and then trace back from the wrapper to the RTL. Any move to a higher level of abstraction also demands a significant methodological change, as well as hiring or training an engineering team with the requisite development and debug skills.
However, the most significant drawback with this technique is that it requires designers to work on what is essentially designfor- verification rather than using their valuable time on designing value-added functionality.
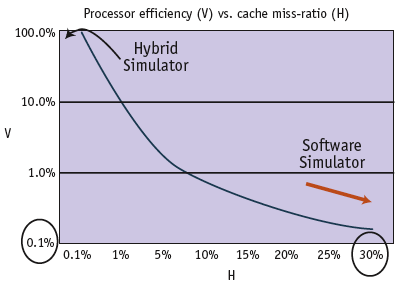
Figure 1. Hybrid simulator achieves 100% processor efficiency. Based upon formulae described in the paper, “Model Simulation and Performance Evaluation for a VLIW Architecture”, by C. Popescu, F. Iacob, presented at the First IEEE Balkan Conference on Signal Processing, Communications, Circuits, and Systems, ISIK University Campus Maslak, Istanbul, Turkey, June 2-3, 2000.
Hardware acceleration
Some teams boost performance by using a hardware accelerator, in which the design is partitioned and mapped to either FPGA- or processor-based hardware resources – that is, the design is actually re-implemented in order to verify it. However, this can reduce the productivity gains delivered by the higher performance.
In fact, compile and set-up time can be of the order of weeks, even months, so applying this approach to individual blocks throughout the project can introduce significant project delays. Hardware acceleration is typically used towards the end of the project for full-chip design verification – certainly not the best time to find out that a design has serious problems.
Hardware accelerators are also incompatible with software simulators. Because the hardware accelerator cannot easily cope with the behavioral logic that is used to implement complex assertions and memory checks, behavioral logic must reside outside the accelerator, and communicate with it via vector-level data. The consequent increase in data volume can slash claimed performance by 90% or more – sometimes, acceleration numbers of 1,000X can be achieved only under a very restricted set of conditions. In addition, the approach limits visibility into functional behavior, causing much of the time won in acceleration to be lost in debug.
Hybrid simulation of the whole design
Increasing processor speed, increasing processor count, moving to a higher level of abstraction and using hardware acceleration do not deliver the requisite order-of-magnitude increases in productivity. To crack the problem, we must look at the critical bottleneck: the standard processor and its associated cache. The answer is to use a very long instruction word (VLIW) processor to increase instruction- level and hardware resource parallelism – and to eliminate the cache limitation.
A VLIW processor turbocharges a server or desktop computer and standard software simulator, boosting throughput by 10X to 100X. The VLIW processor executes simulation using popular software simulators. This hybrid simulator has a large memory bandwidth and a large processor bandwidth, so processor speed is not a limiting factor in performance. The hybrid simulator’s processing efficiency translates directly into major productivity gains. The processing efficiency of the hybrid simulator compared to that of a software simulator running on standard processing hardware is shown in Figure 1. The graph itself is a plot of processor efficiency against the cache-miss ratio.
The server farm can easily cope with executing a large number of parallel tests, each of which requires a few minutes to run. However, tests that cannot be partitioned into parallel tasks may run for hours, or even days, often restricting the opportunity for whole testbench regression testing to one per week. Using hybrid simulation to accelerate these tests by 10X or more, you can allow the design team to run regression tests daily.
The hybrid simulator compiles both synthesizable and behavioral RTL. It therefore supports the behavioral mapping of temporal assertions and other non-synthesizable checks, such as SystemVerilog Assertions (SVA) and Property Specification Language (PSL) assertions. Since hybrid simulation incorporates and supports testbench instructions, it can reduce a 20% testbench runtime overhead to 10% or even 5%, an acceleration factor of 2X to 4X against a traditional hardware accelerator, where the testbench must reside externally.
Hybrid simulation requires none of the implementation of chip functionality necessary in hardware acceleration. Therefore, its compile and set-up time is comparable to that of software simulators. Consequently, designers can use it in any phase of the design without incurring the time penalties of hardware acceleration compile and set-up.
A hybrid simulator suffers none of the design and testbench restrictions of a hardware accelerator. In fact, to the user, a hybrid simulation looks exactly like an ordinary software simulation.
The bottom line
A 10X reduction in verification time dramatically increases productivity and reduces time-to-market. In capital cost terms, the hybrid simulator can deliver the same performance as did 10 servers previously at about half the cost, while reusing existing simulation software licenses. The hybrid simulator leverages the existing investment in hardware, and reduces the need to expand server farm capacity.
In conclusion, hybrid simulation can bring the order-of-magnitude productivity increases to verification that logic simulation delivered for design in the 1980s and fundamentally change the economics of this increasingly challenging task.