A pragmatic approach to evaluating NoC strategies
Network-on-chip (NoC) could prove to be an effective methodology that addresses interconnect roadblocks to the development of more complex systems-on-chip. However the term covers many approaches, some of which – simple enhancement to existing bus technologies, the costly adaptation of theoretical networking concepts – fall short either in terms of performance or NREs.
The article identifies a number of ‘practical’ challenges, which a technologically and economically viable NoC methodology must address. These include:
- Optimized support for many transactions of different sizes that occur in parallel;
- An ability to interconnect many, varying and sometimes proprietary IP blocks and cope with their quality of service (QoS) requirements;
- The minimization of transport wires for easier and less expensive bufferization and pipelining;
- The co-management of initiators’ QoS requirements with efficient access to memory controllers.
A key element in a well-designed NoC system, the network interface unit (NIU), is described in detail and in function. These NIUs gather initiator transactions into a packet, or convert a packet back into a transaction for the target. This mechanism is more efficient than encapsulation and provides true interoperability between multiple protocols on the same chip.
Over the last few years, network-on-chip (NoC) has been proposed as an effective way of addressing the system-on-chip (SoC) interconnect challenge — enabling communication between multiple blocks of intellectual property (IP) on a single piece of silicon. However, the term ‘NoC’ covers many implementation strategies, not all of which provide the required performance. Some use simple improvements to existing busses and do not deliver real ‘network’ benefits. Then there are straightforward implementations of theoretical network principles, but more often than not, these prove prohibitively expensive. To realize NoC’s promise, we need a practical implementation methodology that takes the best in appropriate networking technology and combines it with a pragmatic approach to dealing with deep submicron SoC interconnect issues.
The major elements in an SoC — CPU, digital signal processor, direct memory access, video engine, hardware accelerators, etc. — have a common characteristic: they all generate, load and store transactions. An efficient interconnect must therefore provide optimized support for many transactions of different sizes that occur in parallel (multiple outstanding transactions, split transactions). This alone clearly differentiates NoCs from classical terrestrial networks, such as the Internet.
SoC designers and architects must deal with the interconnection of many and varying IP blocks. Although the interconnect typically covers only 10% of total SoC area, it is very challenging to design. In the first place, it accounts for most integration and timing problems. Common difficulties are:
- Timing problems associated with long wires;
- Late or not-well-known floorplan constraints;
- Challenges posed by multiple frequency and power domains.
Given the scope of these issues, it is not unusual for projects to be delayed or even cancelled because of issues related to the interconnect.
In this context, a true NoC strategy must be one that can be deployed at multiple levels, from specification down to physical design of the SoC. It must also provide the features required by SoC architects, designers, verification engineers, and layout engineers, as each group contributes to the design flow.
The following is intended as a theoretical study of NoCs, but still examines some of the key issues engineers now face in developing them and how a well-designed methodology can help them overcome the various obstacles. Gilles Baillieu manages the European technical team at Arteris. He has held various positions as an applications engineer in the EDA, ESL and IP sectors.He received his MSc from the University of Surrey at Guildford
On-chip interconnect requirements
There are many socket protocol standards in use today (e.g., AXI, OCP). Most experienced designers are familiar with them and consider them reliable. However, many companies also have proprietary protocols and sockets, sometimes for use on specific projects and sometimes deployed across all design activity.
The interconnect in a complex SoC must also cope with the quality of service (QoS) requirements of all the integrated IPs. Traffic is often classified in the following ways:
- Real-time traffic: this is throughput-critical traffic (e.g., to fill a display memory).
- Processor traffic: this is latency-critical traffic (for a CPU, a lost cycle can never be recovered).
- Best effort traffic: this traffic gets the remaining bandwidth.
Efficient transport is another of the most important aspects of NoC. A proper transport protocol definition significantly improves global system performance. By comparison, using a bus socket protocol for transport results in very inefficient implementations. While socket wires are local and short and the parallelism in processing is not so expensive, wires at the transport layer are long and make routing difficult. Therefore, it is critical to minimize the number of transport wires. This results in much easier and less expensive bufferization and pipelining. Designers should be warned that any on-chip communication system that has not been designed with wire optimization will prove especially problematic in high-performance designs.
The number of new SoC designs is not rapidly increasing; instead, individual SoCs are becoming progressively more complex, more expensive, and may have multiple derivatives. These platforms support a plethora of applications, introducing different constraints on topology, and must evolve quickly to address market needs.
An NoC implementation scheme must therefore be able to support any interconnection topology (e.g., 2DMesh, NUMA, octagon, clustered) and the methodology must deal efficiently with late changes in specification. The strategy must also address problems discovered during layout without requiring that the entire interconnect scheme is re-architected. Moreover, for optimal control, the interconnect should not restrict the granularity of the partitioning in clocks and power domains. As mentioned above, on-chip interconnect is dominated by wires and not gates, therefore it should be extremely wire efficient to avoid congestion.
Meeting the requirements of a pragmatic NoC methodology
Consider the basic NoC architecture (Figure 1). It resembles a traditional IT network in that it takes a layered approach, consisting of:
- A physical layer: the medium carrying the information (32, 64 or 128bit, globally asynchronous locally synchronous, chip-to-chip links);
- A transport layer: the provision of packet routing and arbitration based on QoS requirements;
- A transaction layer: the conversion of transactions into NoC packets.
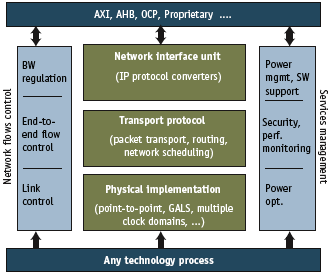
Figure 1. One NoC structure borrows from a traditional network architecture: a three-layered approach consisting of a physical layer, a packet transport layer and an interface layer (enabled by NIUs)
A key element in a well-designed NoC system is the use of network interface units (NIUs). These map initiator transactions into a packet, or convert a packet back into a transaction for the target. This mechanism is more efficient than encapsulation and provides true interoperability between multiple protocols on the same chip. Moreover, the transaction’s destination is decoded by the NIUs making the transport more efficient. For example, using this approach, the Arteris NoC methodology provides native support for all existing standard socket protocols (AXI, AHB, OCP, custom) and is interfaced to third-party memory controller IP providers.
To illustrate how NIUs work, consider the scenario of an OCP initiator running at 200MHz and generating a ‘Write increment’ of 5 words (no response) at the address 0x00010008. The NIU decodes the target (a 32bit AHB slave) and maps the transaction into a NoC ‘Write Increment’ type packet at address 0x0000008 with the final destination specified.
One can construct a transport with the following element: a 64bit data-path first, then reduced to 32bit (size converter) followed by a bisynchronous FIFO to reach the target NIU running at 133MHz. The target NIU will map the NoC packet onto a write increment unspecified of 10 cycles on the AHB socket.
QoS and memory
For a NoC to be effective, the initiators’ QoS requirements must be managed together with efficient access to the memory controllers. Seen from the memory controller, the memory efficiency is given by smart scheduling of transactions; seen from the initiators, QoS is provided by the NoC’s guaranteed throughput services.
The NoC IP library contains some specific QoS units:
- The bandwidth regulator guarantees the throughput for a given initiator.
- The QoS information is transported through the NoC via a mechanism called ‘pressure’ from the initiator to the target and across multiple levels of switches.
At the target, the memory scheduler unit will optimize the DDR access based on packet priority as well as other configurable criteria (e.g., bank swapping, page hit, R/W turn, etc). Consequently, the tradeoff will be made between latency and throughput based on dynamic priorities managed by the NoC
For example, software engineers always ask for maximum CPU performance, but in compensation they are unable to define a limit for memory bandwidth consumption. So the platform architect has to define the minimum guaranteed bandwidth for CPUs. Anything available above will be given in best effort mode. However real-time traffic, which is more regular and predictable, will always get priority when buffering capabilities are in short supply. Therefore, this QoS management must be totally supported by the memory scheduler.
Memory interleaving is an advanced way of managing the memory space based on multiple DDR interfaces when burst size is variable in the system: in other words, where there are both small memory bursts (16byte: MPEG computing, data cache refill) and large ones (128byte: DMA raster, Ethernet Gigabit interface). It is easy to show that a 32bit-DDR interface is not particularly efficient for 16bytebursts. A flexible NoC strategy can address this with multiple 16bit DDR interfaces provided in an optimal way. The smaller interfaces efficiently handle small bursts, while the larger ones are interleaved on the different memories. The NoC thus simplifies the initiator’s task and makes it easier to configure the final product.
Efficient transport
Self-contained packets are fundamental to an efficient NoC strategy (Figure 2). NIUs generate these packets that transport control information and payload together. The approach is extremely efficient in terms of wires and has very little impact on latency.
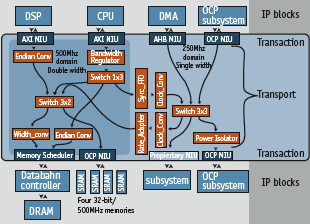
Figure 2. NIUs are used to connect IP using different socket methods to facilitate design re-use and interoperability
With the use of self-contained packets, request and response networks become totally independent. This insures against deadlock and allows specific optimization based on potential dissymmetric traffics. Since the Arteris approach to NoC is fully stateless, it can scale without limitations to meet any design needs.
To see how this works, consider this example based on a basic transport problem encountered in most multi-core systems. Four 32bit traffics at 200MHz are to be aggregated into one single 64bit traffic at 400MHz. The NoC must enable the merger of this traffic in a single stream without inserting unnecessary wait states. In the Arteris system, a technique is used based on different and carefully designed library units (e.g., rate adapter, size converter, FIFOs).
Because of multiple clock domains crossing each other, or due to a multi-die chip, designers use different physical layers. As a result, the transport layer must be independent from the medium (physical layer). Link width and frequency are easiest to change. If the NoC expands itself through multiple frequency domains, designers will prefer to use a mesochronous link (on-chip transport of data plus clock on the same long wires routed without skew). In case of a chip-to-chip link (multi-die design) they will use a physical SERDES type interface (e.g., the PIPE standard from PCI Express) to transport NoC packets. These options also give designers the assurance that they will always be able to react to unavoidable changes in the specification and the floorplan.
NoCs are integrated at the very last stage of the design, when timing margins are low and routing constraints are tough. So, one needs a methodology that gives engineers effective ways of dealing with layout changes attributable to the following:
- Point-to-point connections. Any bus-based interconnect implementation will create layout problems, because of unpredictable loads (fanout + wires). This is true not only for the high performance part of the interconnect, but also when a large number of blocks (peripherals) is connected. Bus structures also make the interconnect much more sensitive to last-minute changes (load variations and timing variations).
- Wire efficiency. This is the most important criterion for the back-end and measures the average throughput obtained per wire. It sets the need for an efficient transport protocol, defined using a minimal number of wires and supporting multiple physical layers. The localization of mux/demux operations in the NIU (i.e., at the network peripheral) is key, avoiding routing congestion and facilitating timing convergence.
- Pipelining. Being able to insert a pipeline stage at any place into the NoC (NIU, transport) allows the designer to fine tune interconnect performance (frequency, latency). Most interconnect tools on the market have predefined pipelining structures and these severely limit performance.
Conclusion
In complex SoCs based on deep submicron processes, the interconnect has to be much more than a set of raw wires. NoC is a viable strategy for coping with issues such as IP interoperability, architecture innovation, and challenging performance targets, all of which suffer under traditional bus-based strategies.
This brief overview of NoC has highlighted elements such as topology, QoS, and layout where a powerful NoC strategy can make a difference. However, many other factors must still be addressed (e.g., security, power, debug, peripheral NoC, service NoC). For each of these, one can identify implementation rules and techniques that favor certain NoC implementations over others.
Therefore, consider your design requirements and challenges carefully when choosing an NoC strategy and remember that the objective is to get your SoC performing correctly, efficiently and as close to your performance goals as possible. NoC can help you achieve this, even in the most challenging designs, but does require informed planning.
Arteris
6 Parc Ariane
Immeuble Mercure
Boulevard des Chenes
78284 Guyancourt Cedex
France
T: +33 1 61 37 38 40
W: www.arteris.com