Learning the value of preparation and simulation by OSMOSIS
OSMOSIS is a super-fast optical switch developed through the Advanced Simulation and Computing program. The article describes the strategies adopted by the IBM team charged with designing the Central Scheduler board for the project.
The design was of a far greater complexity than the team had previously encountered, and as a result, developed new pre-preparation and simulation strategies to give them the greatest possible control over the project from day one.
Consider the various issues that are pushing PCB design and PCB tools to their limits. Any list of those having significant influence would include:
- densely packed components;
- high pin-count ICs;
- large numbers of constrained nets;
- length-constrained nets;
- length matching;
- differential pairs;
- nested busses; and
- unbiased layers.
We can divide these issues into two groups: those that have linear complexity factors and those that do not. In the non-linear column, we would find those factors that relate to the following issues: requirements for high-speed implementations, signal integrity (including the use of differential pairs), and constrained nets. These are also the greater sources of increasing PCB design complexity (Figure 1).
Recently, our group at the IBM Zurich Research Lab completed a project that pushed technological possibility to its limits. Each of the primary complexity-increasing issues mentioned above featured greatly in the design, and our experience with them showed that they could be addressed efficiently.
The design under review was part of the OSMOSIS (Optical Shared MemOry Supercomputer Interconnect System) optical switch developed under the aegis of the Advanced Simulation and Computing program (ASC – formerly the Accelerated Strategic Computing Initiative).
OSMOSIS
OSMOSIS is a 64-port, super-fast optical switch. Each port is capable of handling traffic at up to 40Gbit/s. Our particular contribution was the Central Scheduler or OSCB (Optical Switch Controller Board). This design was significantly more complex than anything we had previously tackled, as the metrics in the sidebar show. The largest project we had worked on before OSMOSIS was a 16-layer board with 3,000 nets and 400 differential pairs.
The OSCB had eight large FPGAs and sockets for 40 control link daughter boards. This raised all the complications you might expect given such a plethora of connectors, and also posed an unusual physical challenge: the completed board would weigh more than 6lb.
The specification then set down that the switch had to have very low latency of 100-250ns, and be capable of a sustained utilization rate of 95%. The bit-error-rate had to be better than 10-21. Naturally, everything had to be delivered within tight cost constraints.
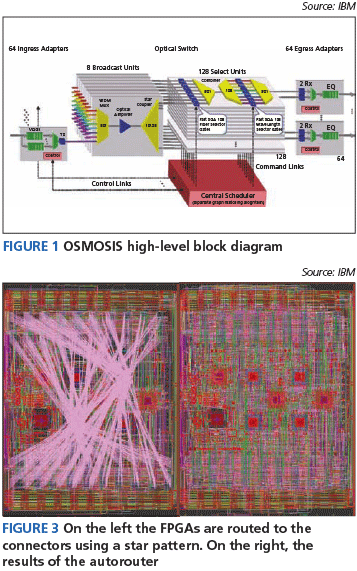
Figure 1 shows the high-level block diagram for the entire switch and again underlines the complexity of the project. For example, the duplicated command/control link units did allow some layout reuse, but then presented major challenges because the OSCB required a substantial number of very fast nets, and these nets needed to be routed as nine independent, overlapping global stars.
Pre-preparation
We quickly recognized that to complete the project efficiently, we needed a very detailed design plan that defined every stage of the work, from beginning to end.
Our first step was to assign logical and useable names to the thousands of signals that were to be routed. This was no trivial exercise. It actually took two weeks, but was worth it because having well-thought-out definitions saved more time and effort over the life of the project.
Another high-priority task was the selection of EDA tools. We did this early on because, should new software be adopted, we needed the time to acquire it and train staff to use it. Some improvements and extensions of the toolset were indeed required. We already had Mentor Graphics’ Expedition/Design View and I/O Designer, so we felt quite capable of routing the BGAs. However, we decided that new verification and simulation software would be needed.
Signal timing simulation was critical because the system clocks first were constrained to no more than 25ps delay variation at the connectors. That’s just 4mm variation of trace length. Moreover, the clocks were also heavily constrained with regard to phase jitter at any connector, creating a demand for minimum crosstalk. We had to define special rules for routing these critical clock signals.
With all the trace length rules and other constraints incorporated, we ended up with 86 signal classes. Given the scale of the task, we acquired HyperLynx, also from Mentor, to verify signal integrity.
Schematic and material
At this point, we were ready to begin the project. We brought in a contractor to enter the schematic, the rules and the constraints data while I concentrated on selection of board material.
The schematic was entered using DesignView and the Constraint Entry System, which proved quite easy to use, although we wanted to take the time to complete this task precisely. It was delivered as a 129-page file.
Since the wiring for the design was highly global, we decided to use just two levels of hierarchy and re-arranged the schematic pages to produce a ‘pseudo-hierarchy’. Defining and refining all the rules and constraints easily took two weeks.
The selection of the PCB material involved considerable effort and we had to work closely with the board manufacturer to meet the specification. We needed a material with a low dielectric constant, and a very high Tg (215ºC in this case) to ensure soldering would not damage the board. Had we selected a lower Tg (e.g., FR4), vias could have fractured from the heat generated by today’s soldering techniques. We finally settled on Isola IS620 epoxy.
Thermal issues
Given the number of devices on the board, the computing power and the maximum switching speed, generated heat was an obvious design consideration. We used some techniques beyond the scope of smaller scale designs. For example, each individual FPGA had a fan mounted on it for cooling.
All told, the board consumed 1.2kW when fully populated and powered on. Our solution was to design everything with respect to thermal considerations so that it would be completely bulletproof.
Place and route
Placement was actually one of the least difficult tasks. The presence of 40 connectors and eight FPGAs in BGA packages pretty much dictated the process. Now we had to define the board buildup.
Our starting point was to target 32 layers (16s 16p). Later, another four signal layers were added, providing space for meanders to accommodate length matching. This was to address the significant fanout issues in routing the FPGAs to the 40 connectors. The connectors also prohibited use of through vias, as the holes would close needed routing channels on all signal layers, making a proper connector fanout impossible. We ended up creating two, if you will, ‘half boards’ (sub-composites) to help overcome this problem.
With the buildup complete, it was time to place the remaining 3,600 components, a daunting task. However, given that the large connectors and FPGAs had more or less dictated their placement, there was little leeway for placing the remaining components. In fact, we reached a stable placement after just three weeks.
We planned to route as much of the board as possible automatically because of the complexity of the project. Certainly, manual routing seemed physically impossible within our time and signal integrity budgets. While the received wisdom was that you route critical nets by hand, how exactly do you do that when there are 4,000 critical nets?
We looked at several strategies, but the complexity of the board ruled out using just one, and rather demanded a combination of several. We did route the master clock nets first, followed by a careful manual cleanup (N.B. the critical timing constraints for those nets). Next came the synchronization nets, and then all the remaining differential pairs (still about 3500), all done in a similar manner. The connections for most of these nets formed nine global stars, each one consisting of 450 differential pairs, connecting each of the FPGAs with each of the 40 connectors. The result was the complexity of overlapping stars.
Figure 2 shows two of the stars as open netlines, and how the autorouter derived the connections. The intention was to give the autorouter one star at a time and have it do the routing overnight
And then, disappointment. We had purchased the fastest PC available. We ran the autorouter for three nights with different routing strategies, but it could not finish the job in a timely manner. We had clearly underestimated the scale of the task. Luckily, Mentor was beta-testing a new version of Xtreme AR, its distributed autorouting system. We were given access to the software, and running it on four very fast PCs finally allowed us to complete the routing. Indeed, without the collaborative autorouter, we could not have completed this project with our existing tools.
Verification and simulation
From the beginning, we had known the project would require detailed simulation and signal integrity analysis. Unfortunately, we could not simulate the entire board because of scheduling constraints. Instead, we identified the most critical signals and simulated those, through the connectors to the daughter boards. Initially, we were worried that this approach would prove inadequate, but the results surpassed even our most optimistic expectations and gave us very high confidence in the layout.
Lessons Learned
In the end, we produced four prototype boards. Each met the specification fully. Not one ‘yellow wire’ was needed. This was particularly pleasing as the specification had been changing throughout the project. The total time elapsed from defining signal names to completion was about nine months. We could have completed the project earlier but had to postpone placement because several devices were not yet fully defined.
Some of the things we learned were things that we wish we had done. For example, you may wonder why we did not use HDI for a board this complex. That was because no team member had any previous experience with HDI and we felt that the schedule would not allow us to ascend that learning curve. However, were we to embark on a similar project today, there is no question that we would. We also did not have access to some new tools like Mentor’s Topology Router. It would have eased the routing of the FPGAs to the connectors.
We did use I/O Designer for the first time. However, because we still were not entirely familiar with the tool, we did not use it as much as we might have done. Instead, the FPGA architects were still defining the devices, so we had to freeze the pinouts early and could not take advantage of its pin optimization feature. However, when the design was finished, we went back and used I/O Designer to optimize pinouts for routing. We found we could have reduced the board from 20 signal layers to 16, and 36 total layers to 32.
We really learned the value of careful, logical signal naming and of taking the time to input schematic, rules and constraints data. These look like lengthy tasks at the beginning of a project, but their ripple effect saves countless hours.
We found the tools really shined when pushed to near their limits. This was more obvious than on smaller projects. Meanwhile, we believe simulation has become a critical design stage given the signal speed of today’s products—it makes ‘correct by design’ possible.
IBM Research GmbH
Zurich Research Laboratory
Säumerstrasse 4
CH-8803 Rüschlikon
Switzerland
T: +41 44 724 8111
W: www.zurich.ibm.com
