Teaching computers to recognize a smile (or frown, or grimace or…)
Using deep learning techniques and convolutional neural networks to bring facial recognition capabilities to embedded systems.
Humans very quickly learn to recognize that certain facial expressions are associated with common emotions such as anger, happiness, surprise, disgust, sadness, and fear. But transferring this skill to a machine is complex, especially if you try to program it to recognize each type of expression from scratch.
What if, instead of trying to program a machine to recognize emotions, you could teach it to do so instead?
Automating facial recognition
One way of doing this is to use deep learning techniques, which can be effective at recognizing and classifying expressions. Implementing deep neural networks (Figure 1) in embedded systems can help machines visually interpret facial expressions with almost human-like levels of accuracy.
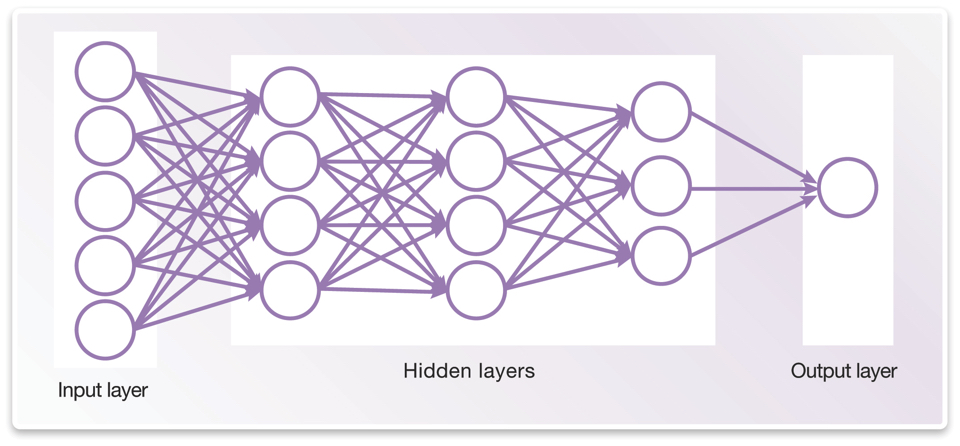
Figure 1 A simple example of a deep neural network (Source: Synopsys)
A neural network can be trained to recognize patterns and is considered to be “deep” if it has an input and output layer and at least one hidden middle layer. The value of each node of the network is calculated from the weighted inputs from multiple nodes in the previous layer. These weighting values can be adjusted to perform a specific image-recognition task, in a process called training.
For example, to teach a deep neural network to recognize a photo showing people with happy expressions, its input layer is presented with many such images as raw pixel data. Knowing that the result should be recognized as happiness, the network discovers patterns in the picture and adjusts the node weights to reflect this. Each additional annotated image showing “happiness” helps refine the weights on each node. Trained with enough inputs, the network can then take in an unlabeled image, analyze it and accurately recognize the patterns that correspond to happiness.
Separating training and implementation of facial recognition
Deep neural networks require a lot of computational horsepower to calculate the weighted values of all these interconnected nodes. In addition, it’s important to have enough memory for data and to be able to move data efficiently. Convolutional neural networks (CNNs), as shown in Figure 2, are the current state-of-the-art for efficiently implementing deep neural networks for vision. CNNs are efficient because they reuse a lot of weights across the image, and take advantage of the two-dimensional input structure of the data to reduce redundant computations.
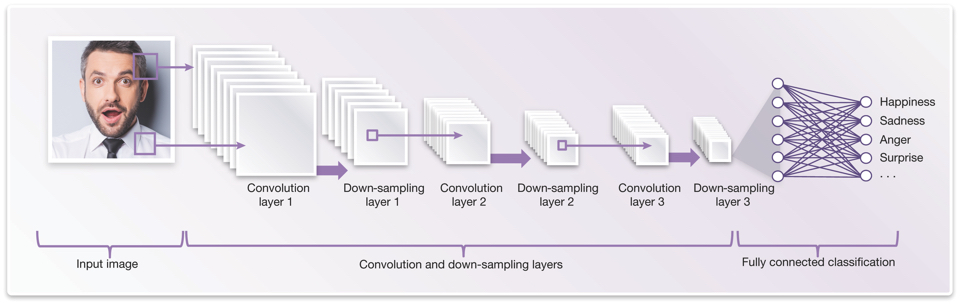
Figure 2 Example of a convolutional neural network architecture (or graph) for facial analysis (Source: Synopsys)
Implementing a CNN for facial analysis requires two distinct and independent phases. The first is a training phase, and the second, a deployment phase.
The training phase (Figure 3) requires a deep learning framework such as Caffe or TensorFlow (which use many CPUs and GPUs to do the training calculations), and the knowledge to apply the framework appropriately.
These frameworks often provide example CNN graphs that can be used as a starting point, which can then be fine-tuned for the particular application, for example by adding, removing or modifying layers to achieve the most accuracy.
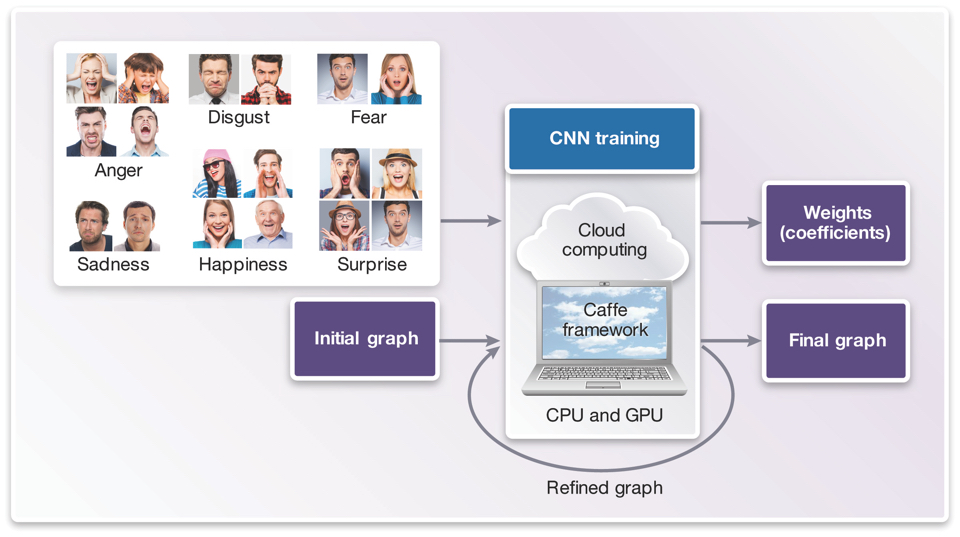
Figure 3 CNN training phase (Source: Synopsys)
One of the biggest challenges in the training phase is finding a labeled dataset upon which to train the network. The accuracy of the deep network is highly dependent on the distribution and quality of the data on which it is trained. For facial analysis, the emotion-annotated dataset from the Facial Expression Recognition Challenge and the multi-annotated private dataset from VicarVision can provide useful starting points.
Deployment
The deployment phase (Figure 4) for real-time embedded design can be implemented on an embedded vision processor, such as the Synopsys DesignWare EV6x embedded vision processors with programmable CNN engine.
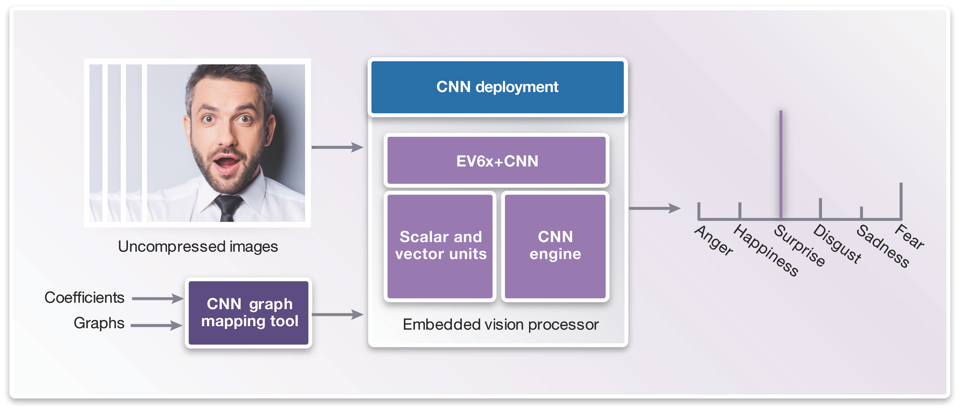
Figure 4 The CNN deployment phase (Source: Synopsys)
An embedded vision processor balances performance with small area and lower power. While the scalar unit and vector unit of the processor are programmed using C and OpenCL C (for vectorization), the CNN engine does not have to be manually programmed. The final graph and weights (coefficients) developed during the training phase are fed into a CNN mapping tool and then the embedded vision processor’s CNN engine can be configured and ready to execute facial analysis.
Images or video frames captured by a camera lens and image sensor are fed into the embedded vision processor. CNNs can have difficulties handling significant variations in lighting conditions or facial poses, so the images can be pre-processed (to normalize the lighting, scale the images, rotate their plane etc.) to make the faces more uniform.
The fact that the embedded vision processor has a scalar unit, vector unit and specialized CNN hardware also means that the CNN engine can be classifying one image while the vector unit is preprocessing the next. The scalar unit handles decision making, such as what to do with the CNN detection results.
Image resolution, frame rate, number of graph layers and desired accuracy all affect the number of parallel multiply-accumulations needed to achieve the required recognition performance. Synopsys’s EV6x embedded vision processors with CNN can run at up to 800MHz on 28nm process technologies, and offer performance of up to 880 multiply/accumulate operations per cycle.
Once the CNN is trained and configured to detect emotions, it can be more easily reconfigured to handle facial analysis tasks such as determining an age range, identifying gender or ethnicity, and recognizing the presence of facial hair or glasses.
Running CNNs on an embedded vision processor opens new applications for vision processing. It will soon be commonplace for consumer electronics device to interpret our feelings, with toys detecting happiness and electronic teaching systems determining a student’s level of understanding by identifying facial expressions. The combination of deep learning, embedded vision processing and high performance CNNs will be one of the key enablers of this trend.
Author
Gordon Cooper is embedded vision product marketing manager at Synopsys.
