Application-specific library subsetting
The limited cell count of standard cell libraries is restricting the performance that designs can achieve without resorting to expensive and time-consuming techniques. This article describes the addition of extended cell libraries and novel synthesis tools to a traditional RTL-to-GDSII flow in a new methodology that helps to overcome this performance brake. The technique is called “application-specific library subsetting”. It is based on introducing subsets of digital cells from that extended library into the netlist during design optimization according to requirements and constraints.
A largely unappreciated limitation of existing RTL-to-GDSII design flows is impacting digital logic designers more and more today because of the increasingly aggressive performance, power and cost targets.
This limitation, present in the current generation of digital cell IP and as a direct consequence also reflected in most RTL-to-GDSII EDA tools themselves, is attributable to the artificially limited cell count of standard cell libraries. This ultimately sets the bar for how well a digital design can perform when implemented on silicon unless custom methods are employed. The limitation affects pure digital designs and mixed analog-digital designs alike.
This article explores how a new generation of very large extension cell libraries, combined with novel synthesis technology, can overcome these performance limitations, introducing a concept called ‘application-specific library subsetting’. It then goes on to show how this methodology is now a practical reality, heralding a new era in digital logic design.
The logic design perspective
Digital logic designers will be aware that there is a practical limit to the performance that can be achieved for the combination of a given circuit architecture described as RTL, a specific choice of process technology and an accompanying standard cell logic library. When all the ‘knobs’ of the logic synthesis and physical implementation tools have been turned to ‘highest effort’, you have generally reached the performance ceiling. To further increase performance, architectural changes—often costly in terms of implementation effort, verification time and potential risk—must be applied to the RTL code. Such techniques might include the insertion of extra levels of pipelining.
There is, however, an alternative approach where significant additional performance can be gained generally without making any RTL changes—by using a carefully enhanced logic cell library. Such custom transistor-level optimization techniques are routinely used, for example, by teams performing specialized CPU core hardening to maximize performance.
Recently, however, a technique has emerged that enables a broader range of design teams to take advantage of improved cell libraries without a dedicated IP development team needing to work in parallel. Unlike previous solutions that offer ways of adding so-called ‘tactical cells’ to existing libraries, the new approach is based on comprehensive and fine-grained extensions of existing foundry cell libraries together with novel logic synthesis technology that can take best advantage of these ‘extended’ libraries.
The resulting increase in the performance ceiling allows speed to rise significantly while also delivering a reduction in the silicon footprint. This can, in turn, also reduce leakage power and manufacturing cost. And all of this is achieved without disrupting the existing design style or the fundamental implementation methods. Figure 1 illustrates the performance ceiling that often exists when implementing a digital logic block using a standard cell library flow, against what can be obtained using an ‘extended’ digital logic library allied with novel synthesis technology.
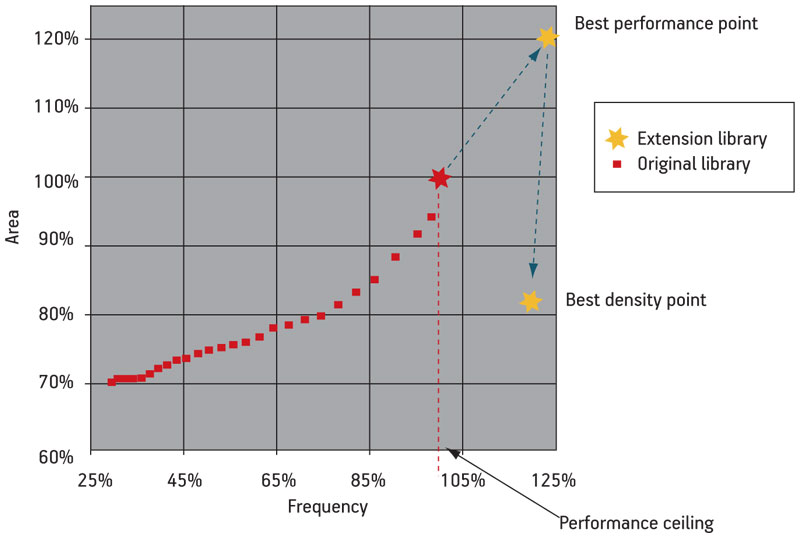
Figure 1
Digital logic performance ceiling
The library design perspective
Constructing an optimal generic cell library is naturally impossible. Even constructing a reasonably good one is hard and, under common practices, a very time-consuming process.
Even for a given design block, no known analytical methods exist for calculating the optimal cell library. The process is too complex. A large range of independent library parameters can vary, and these might include the physical cell template, the logic function line-up, the transistor and stage sizing, and the layout topology. Add to that the fact that each new process generation adds new design rule complexities and physical phenomena that affect cell performance.
For many cell library designers, library quality is still very much assessed cell-by-cell by manually inspecting and adjusting each individual layout in what can be characterized as a ‘beautification’ process. It can be shown that if you base your cell set on the results of a careful selection of block-level benchmarks, improved design level performance can be achieved, but such libraries perform best on a limited set of design types.
Thus, the library construction process for many organizations remains a manual process and therefore tends to be evolutionary. The starting point is what worked well last time—i.e., the libraries just completed for the previous process node. Studying generations of libraries, it can be observed that reuse applies to all levels of abstraction—function, sized netlist and layout topology.
Cell libraries offered for a given process are rarely improved over time—for instance, extending in terms of function line-up or drive strengths. In fact, many new cells that are added to satisfy the requirements of one design may not be suitable for general synthesis, and ultimately remain unused in the library.
What we can conclude at this point is that the ‘best available’ cell library is a result of a long series of compromises—there is little chance that more can be gained through the refinement of such libraries.
Increasing digital logic performance
Numerous leading IDMs are transitioning themselves into ‘fab-lite’ and even fabless companies. Thus the reliance on not only foundry-provided process technology, but also foundry-provided foundation IP such as standard cell libraries is growing.
Consolidation is expanding the foundry market and as new players start to offer foundry services, the need for differentiation increases. System IP and foundation IP are becoming essential to staying ahead of competition in the foundry business. And this is very good news for logic designers.
One promising technology that is emerging alongside the foundry-provided or -approved cell libraries are families of extension libraries and accompanying synthesis tools that can handle the resulting very large cell libraries. Such technology is being offered by independent library vendors through foundry IP channels and combines the advantages of trusted, foundry-qualified cell libraries with the design optimization potential that can be realized through careful extraction of optimal cell subsets using advanced synthesis tools.
Nangate’s MegaLibrary is one such example of a very large library built as an extension to foundry-approved cell libraries and is deployed in combination with a next-generation synthesis tool such as Nangate’s Design Optimizer.
Building large, fine-grained extension cell libraries
Constructing large cell set extension libraries is mainly the preserve of independent library IP vendors and in-house library teams at IDMs and foundries. The number of cells in these extended libraries can be up to 50,000 and they incorporate many different cell subsets:
- Drive strength, skew and arc variants ideal for optimizing critical path timing and channel-length variants focused toward power reduction. This set also includes footprint-compatible cells, which are very efficient for late-stage speed and power optimization because very fine-tuned cell sizing can be done post-route, avoiding the need to re-extract routing parasitics.
- Combined cells. These are created by combining two or more base cells into one new cell. As an example, a NOR3 into a NAND2 is a combined cell. The combined cells can have a positive impact, particularly on area reduction.
- Complex cells. These cells have a more complex functionality than what is usually found in a standard-cell library. This subset is very efficient for use in critical path speed optimization, but is also useful for area recovery and, indirectly, power optimization.
The limited cell count of standard cell libraries (~600 cells) has traditionally and predominantly been the result of the methods and tools commonly used in their construction and would ordinarily preclude the practical development of such very large extension libraries.
This is now no longer the case with the availability of more advanced IP development tools that greatly increase the level of automation and access to vast computing arrays for incredibly efficient, automated cell library creation. A good example of such a tool is Nangate’s Library Creator.
A full custom-like, cell-based methodology
In addition to the traditional RTL-to-GDSII flow, two further components are required to facilitate an increase of the digital design performance ceiling.
- An extended cell library provided by independent library vendors typically through the usual foundry interface mechanism and containing a very large number of fine-grained cell variants built to complement the existing foundry-provided or -approved base cell libraries.
- A novel type of synthesis tool that is able to take advantage of the much richer and fine-grained extension libraries. It operates on the design netlist in concert with the existing RTL-to-GDSII flow and enables cell subsets from an extended cell library to be used to improve and fine-tune the design’s performance.
The combination of these two elements enables the concept called ‘application-specific library subsetting’ whereby, during the design optimization phase, subsets of digital cells from the extended library that better suit the design requirements and constraints are introduced into the design netlist.
This activity takes place at the synthesis stage of design implementation all the way through to place and route (P&R) with different types of cells being used at each optimization step, depending on the design metric (or metrics) to be improved (i.e., speed, area, power or a combination thereof).
The net effect of this methodology is similar to performing transistor-level optimization while maintaining the convenience and efficiency of a cell-based design flow and can achieve near full-custom levels of performance.
Practical gains
There are many factors that influence absolute performance. Not least of these is how well tuned the design has become within the traditional flow. Experience has shown that, even with a heavily optimized modern CPU core on a recent process node (65nm or below), it is quite realistic to expect a 15% speed increase over the best result that can be achieved using a traditional foundry-approved base library.
In the case of area, the advantages of deploying combined cells and new complex cells can reduce the digital logic real estate by 20% or more. This can have a huge impact on baseline profit margins in terms of reduced manufacturing costs. The secondary benefit of such area reduction is a static power decrease, which for a mobile device usually means longer battery life—a win-win situation.
Static and dynamic power can easily be addressed with this new methodology. Static power reduction comes naturally with area reduction, but additional benefit can be obtained with late stage in-place optimization using footprint compatible channel-length cells. Improvements of 20-30% are achievable, enough in some cases to allow the use of a lower cost IC package.
Conclusion
With the emergence of an innovative new synthesis technology and the ability to reliably and cost-effectively build large fine-grained digital cell extension libraries, it is now possible to significantly raise the performance ceiling of current and future digital logic designs, but without discarding the considerable investment in existing EDA technology and IP.
Simon Fielding is director of EMEA Sales for Nangate. He has held a number of technical, sales and management positions in the EDA and IP industries over the past 18 years at companies such as Virage Logic, Viewlogic, Synopsys and Avant. He holds a BSc in Computer Science from Leeds University.
Nangate
155-A Moffett Park Drive
Suite 101
Sunnyvale
CA 94089
USA
T: +1 408 541 1992
W: www.nangate.com
