Achronix builds machine learning IP into eFPGA
Achronix has incorporated direct support for machine learning into the latest version of its embedded field-programmable gate array (FPGA) architecture.
Like competitors such as Flex Logic, which launched an embeddable core for inferencing within an FGPA fabric last month, Achronix has been a beneficiary of the way in which machine learning is upending computer architecture – potentially to the point where we start to look at general-purpose processors as “complexity offload” units for algorithms that run primarily on a dedicated fabric, albeit in the case of eFPGA implementations, a fabric that can be rewired for different jobs.
“Moore’s Law is no longer the engine to increase compute performance,” claimed Steve Mensor, vice president of marketing at Achronix. He pointed to trends in cloud computing where FPGAs now form part of the core offering in order to beef up performance. “All the hyperscalers are announcing work on FPGA offload as part of their data-center product offerings.”
Machine learning is only part of the push into data centers. Compression, XML decoding, genomic analysis and video coding are among the applications that are now being offloaded to FPGAs, both standalone and embedded into larger custom devices.
A common factor in these applications is that they do not require high precision in calculations. DNA search and matching, for example, needs only a few bits to handle each base pair in a sequence. But because of these properties, the applications are not well-matched to the integer and floating-point pipelines of standard processors. “FPGAs can offer 16 times more operations per second per watt than GPUs,” Mensor claimed.
Other areas where Achronix is looking to expand is in communications, particularly 5G, where latency concerns and fluid standards are pushing designers to use programmable hardware rather than processor-based computation. “5G will probably be the largest segment for embedded-FPGA technology,” said Mensor.
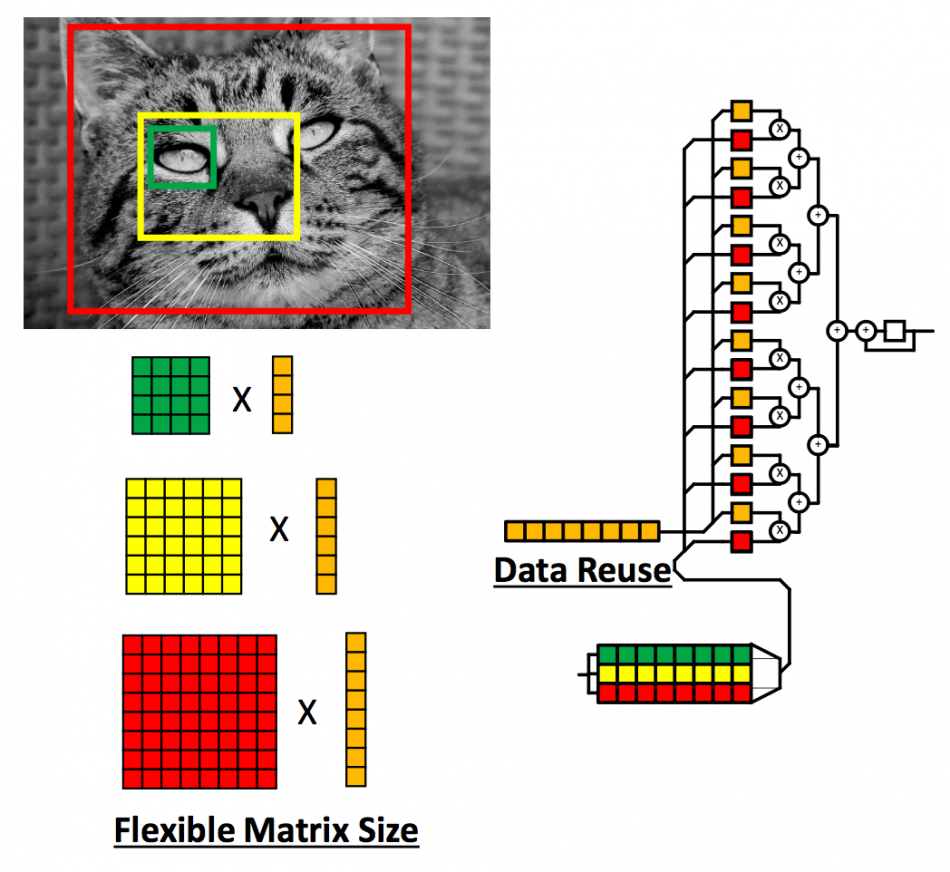
Image The MLP caches vectors locally in a cyclic memory for reuse and is intended to deal with varying matrix sizes
When it comes to machine learning, Achronix is looking more at embedded and edge-computing applications where there is a stronger emphasis on inferencing performance, although the designers have recognized the need to do local training. The main problem is getting the energy consumption down, which means attacking the memory interface more than the computation.
“Moving data around consumes more power than performing computations on that data,” Mensor said. “The question is: how do you make that more efficient? That’s what we are being tasked with.”
These requirements have led to two main directions in the Gen4 architecture. There are a number of core logic-block changes intended to favor high-throughput compute of many different kinds as well as the introduction of a 4bit-wide interconnect to complement the single-wire infrastructure of a conventional FPGA. This change has provided the opportunity to put 4:1 muxes into the fabric itself to allow some bus-oriented logic operations to be handled without dropping down into the lookup tables (LUTs).
The six-input LUTs themselves have been expanded to have two registers per LUT and with some additional logic paths to improve density in some circumstances. According to Achronix, this change makes multipliers implemented in the core fabric take up a lot less space than with a conventional design. Similarly, there are now 8:1 muxes and 8bit ALUs in the core fabric along with an 8bit cascadable Max() function unit, which is being included because of the prevalence of that kind of operation in pooling and similar layers in neural networks. Another addition is the inclusion of dedicated shift registers to support the creation of short FIFO register files for temporarily caching data.
The use of dedicated local memory to reduce accesses to the outside world continues into the machine-learning processor (MLP) unit. Intended for the matrix-type operations found on convolutional layers, the engine includes a cyclic register file into which vector data can be loaded and used repeatedly as the operations move across a tile of pixels or samples. The datapaths can be programmed for different types of layers, such as convolutional and LSTM and can handle different matrix sizes.
As with other FPGA architectures that have incorporated machine-learning acceleration, the MLP is intended for handling dense networks where every calculation is, ideally, on a non-zero weight. This is in contrast to dedicated machine-learning processors that now embed the concept of sparsity – skipping operations on zero weights rather than filling their pipelines with useless operations. Achronix expects designer to use the FPGA fabric to exploit sparsity – reassembling the data from a sparse network into a flow of dense-matrix operations that can be handled efficiently by the MLP.
The MLP handles a number of different precisions, from 4bit integer to 16bit and 24bit floating point, to support local training. Higher-resolution floating point can be taken care of by the existing DSP64 block. Achronix expects the MLP to support a clock rate of around 750MHz.
The first outing for the Gen4 architecture will be in TSMC’s 7nm process next year. But once the rollout of that is complete, the company expects to port the IP to the 16nm process to support customers who do not want to make the leap to the latest finFET process.
